Vartija ei ymmärrä jakaumia
Suomessa vartija on kaksi kertaa tehnyt ratkaisun, joka on koetellut ihmisten oikeustajua.
Ensimmäisessä tapauksessa lapsi jäi kiinni maksamattomasta muovipussista.
Toisessa tapauksessa huippuravintolan kokki pysäytettiin kassavirheen vuoksi.
Monen intuitio sanoo:
tämä tuntuu väärältä.
Miksi?
Koska vartija käsitteli tapausta yksittäisenä tapahtumana.
Hän sovelsi samaa sääntöä joka tilanteessa.
Hän unohti, että maailma on jakauma.
Data scientist ei kysy:
rikos vai ei rikos.
Data scientist kysyy:
kuinka todennäköistä on, että kyseessä on vahinko?
Näytän nyt konkreettisesti, miten data science olisi voinut estää nämä kohut.
Todellinen päätösongelma
Vartijan todellinen kysymys ei ole juridinen.
Se on tilastollinen.
Kun tuote jää maksamatta, vaihtoehtoja on kaksi:
- henkilö teki virheen
- henkilö yritti varastaa
Ongelma:
molemmat näyttävät usein samalta.
Yksi maksamaton tuote ei kerro motiivista.
Tarvitsemme kontekstia.
Mitkä asiat vaikuttavat riskiin?
Tarkastellaan realismia.
Paikkakunta vaikuttaa
Suomessa rikollisuus ei jakaudu tasaisesti.
Suuressa kaupungissa satunnaisia näpistyksiä tapahtuu enemmän.
Pienellä paikkakunnalla lähes kaikki tuntevat toisensa.
Todennäköisyys on erilainen jo lähtökohtaisesti.
Vuodenaika vaikuttaa
Suomi ei ole Kalifornia.
-20°C vähentää spontaania rikollisuutta.
Joulusesonki lisää virheitä kassalla.
Pimeys vaikuttaa käyttäytymiseen.
Kauppaympäristö vaikuttaa
Itsepalvelukassat lisäävät virheitä.
Suuret ostoskorit lisäävät virheitä.
Kiire lisää virheitä.
Ihminen tekee virheitä
Ihmiset eivät ole täydellisiä.
Kassalla tapahtuu virheitä jatkuvasti.
Joskus unohdamme maksaa tuotteen.
Useimmiten kyse ei ole rikoksesta.
Rakennetaan realistinen maailma
Simuloin ympäristön.
Mukana:
- eri paikkakunnat
- eri kauppatyypit
- vuodenajat
- vartijoiden oppiminen
- asiakkaiden käyttäytyminen
Miltä maailma näyttää jakaumana?
Jakaumat menevät päällekkäin.
Täydellistä rajaa ei ole. Tämä ei silti tarkoita, etteikö jotain sääntöjä ja päättelyä voitaisi tehdä.
Lisätään oikeat tapaukset simulaatioon
Rakennetaan realistiset profiilit tapauksista.
Tapaus 1 Lapsi ja muovipussi. Maksamattomia tuotteita oli 1 kappale ja sen arvo oli pieni, muutamia kymmeniä senttejä. Lisäksi tilanteessa oli lapsella jutun mukaan suuri hämmennys. Asetetaan siksi tuotteen arvoksi 30 snt ja hämmenyksen määräksi 0,9 (1 on maksimi). Tapahtumapaikaksi laitetaan “city” eli isohko kaupunki.
Tapaus 2 eli kokki ja kalat. Tarkka tuotteiden määrä ei selviä uutisesta, mutta koska jutussa puhutaan yksiköstä eli “kalafile”, oletetaan sen tarkoittavan yhtä kappaletta. Tuoteen hinta selviää jutusta eli 112,67 e. Koska kyseessä on ulkomaalainen ja liike oli shop-in-shop, laitetaan hämmenykseksi 0,7 ja tapahtumapaikaksi “metro”, koska se on mallini kaupunkiluokituksen isoin kokovaihtoehto.
Mallin arvio tapauksille
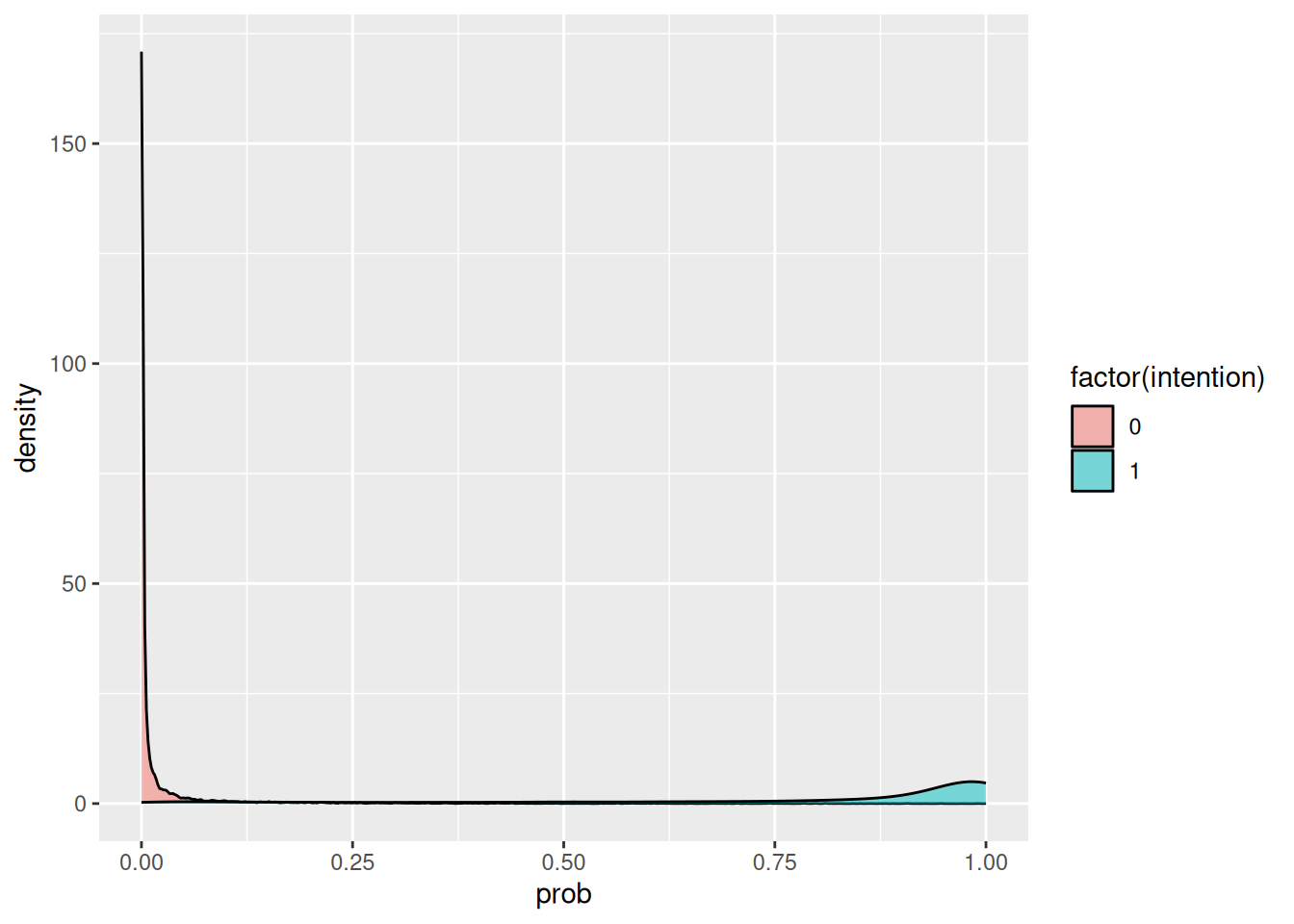
Visualisoidaan tapaukset jakaumaan
Nyt näemme:
tapaukset sijoittuvat jakaumaan.
Ne eivät ole selkeitä rikoksia.
Decision curve analysis
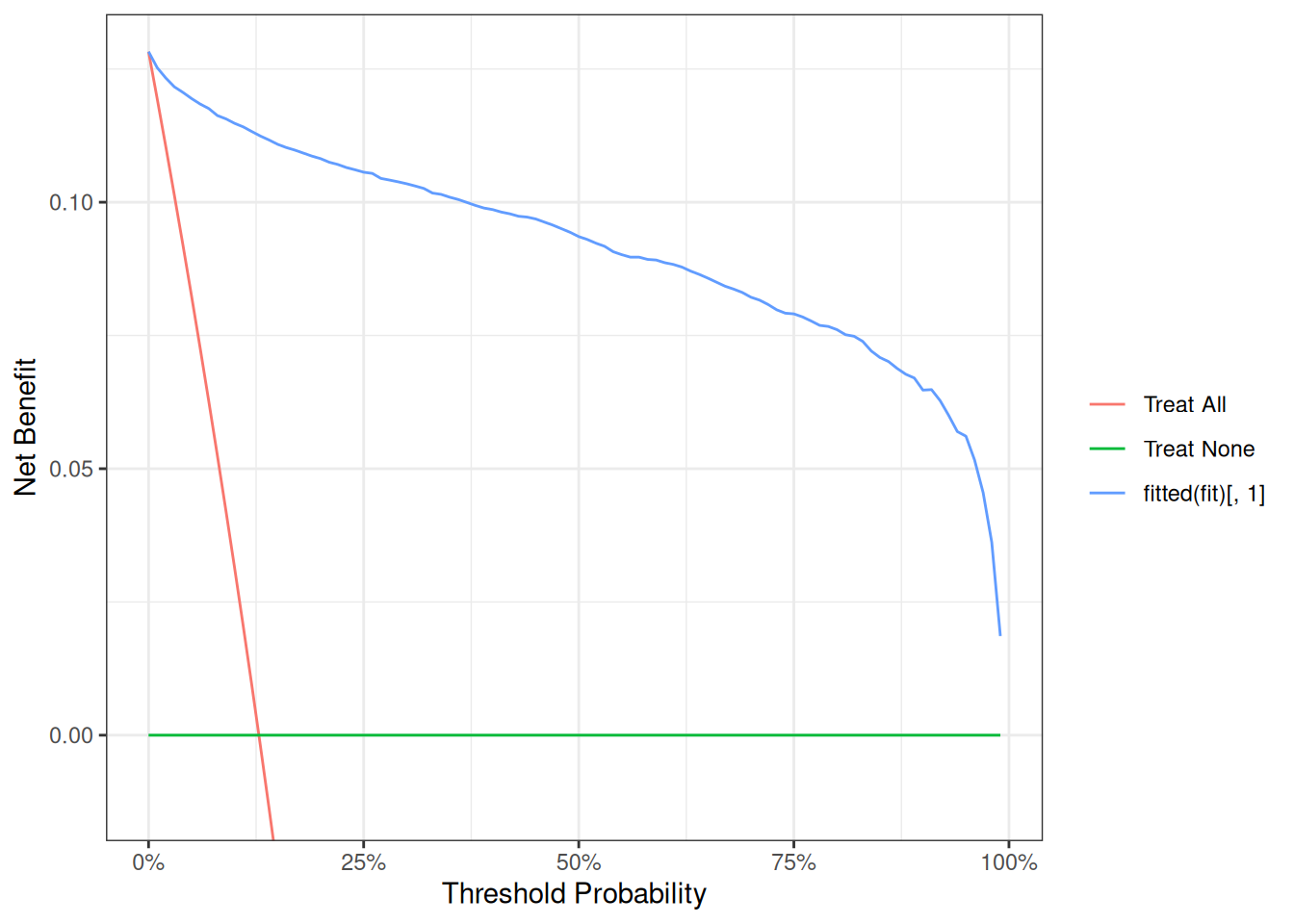
Tämä kertoo:
milloin puuttuminen on järkevää.
Miten Decision Curve Analysis -kuvaa luetaan?
Decision curve analysis kuulostaa monimutkaiselta.
Idea on kuitenkin yksinkertainen:
kuva kertoo, milloin vartijan kannattaa puuttua tilanteeseen.
Mallin tarkoitus ei ole maksimoida kiinniottojen määrää.
Tarkoitus on vähentää virheitä.
Virheitä on kahdenlaisia:
- syytön ihminen pysäytetään
- varas pääsee lähtemään
Näillä on erilaiset kustannukset.
Mitä akselit tarkoittavat?
x-akseli: päätöskynnys
x-akseli kertoo, kuinka varma vartijan pitää olla ennen kuin hän puuttuu tilanteeseen.
Esimerkkejä:
0.1 = vartija puuttuu jo pienellä epäilyllä 0.5 = vartija puuttuu vain jos rikos näyttää todennäköiseltä 0.8 = vartija puuttuu vain lähes varmoissa tapauksissa
Toisin sanoen:
kuinka paljon näyttöä tarvitaan ennen puuttumista.
y-akseli: nettohyöty
Net benefit kertoo, kuinka hyödyllinen päätössääntö on.
Hyöty kasvaa kun:
- oikeat rikokset havaitaan
- turhat pysäytykset vähenevät
Suurempi arvo tarkoittaa parempaa tasapainoa.
Voit ajatella tätä:
kuinka paljon järjestelmä tuottaa hyötyä verrattuna haittoihin.
Mitä viivat tarkoittavat?
vihreä viiva: Treat None
Tämä tarkoittaa:
vartija ei koskaan puutu tilanteeseen.
Seuraukset:
- kukaan ei joudu väärin syytetyksi
- kaikki varkaudet jäävät huomaamatta
Tämä toimii vertailukohtana.
punainen viiva: Treat All
Tämä tarkoittaa:
vartija pysäyttää kaikki, joilla jää yksikin tuote maksamatta.
Seuraukset:
- kaikki rikokset havaitaan
- paljon syyttömiä pysäytetään
Tämä on toinen ääripää.
sininen viiva: data science -malli
Sininen viiva näyttää, mitä tapahtuu, kun käytämme mallia.
Malli arvioi todennäköisyyden jokaiselle tilanteelle.
Puuttuminen tapahtuu vain, jos riski ylittää valitun kynnyksen.
Tämä tuottaa usein paremman tasapainon.
Miten kuvaa tulkitaan käytännössä?
Valitse x-akselilta päätöskynnys.
Katso, mikä viiva on korkeimmalla.
Korkein viiva tarkoittaa parasta päätösstrategiaa.
Esimerkki
Jos päätöskynnys on 30 %:
vartija puuttuu tilanteeseen, jos mallin mukaan rikoksen todennäköisyys on yli 30 %.
Jos sininen viiva on tässä kohdassa korkeammalla kuin punainen ja vihreä:
malli tuottaa vähemmän haittaa kuin kumpikaan ääristrategia.
Mitä tämä tarkoittaa käytännössä?
Jos vartija toimii kuin Treat All:
- syntyy paljon kohuja.
- Syytön ihminen pysäytetään liian usein.
Jos vartija toimii kuin Treat None:
- rikoksia ei estetä.
- hävikki kasvaa.
Jos vartija käyttää dataa:
- virheitä tapahtuu vähemmän.
Miksi kohut syntyvät?
Koska ihmiset odottavat varmuutta.
Todellisuudessa on vain todennäköisyyksiä.
Jos vartija käyttää liian aggressiivista sääntöä:
syntyy vääriä kiinniottoja.
Jos vartija on liian varovainen:
hävikki kasvaa.
Optimi on kompromissi.
maailma on jakauma
yksittäinen tapaus ei kerro totuutta.
Se on vain yksi piste jakaumassa.
Data science auttaa näkemään kokonaisuuden.
Siksi data scientist ajattelee eri tavalla kuin vartija.
Siksi data scientist välttää kohut.
Kaipaatko analyysiä tai onko sinulla projekti, jonka haluat toteuttaa? Ota yhteyttä kristian.vepsalainen@proton.me . Olen käytettävissäsi.