---
title: "Tarvitseeko Suomi lisää miljardöörejä? Data-analyysi miljardöörien roolista taloudessa"
description: "Helsingin Sanomat kysyi tarvitseeko Suomi lisää miljardöörejä. Analysoin maailman miljardööridataa ja selvitän, miten miljardöörit liittyvät innovaatioihin, talouskasvuun ja eriarvoisuuteen."
author: "Kristian Vepsäläinen"
date: "2026-03-26"
slug: miljardoorit-taloudessa
categories:
- data science
- taloustiede
- eriarvoisuus
- innovaatio
- jakaumat
format:
html:
toc: true
toc-depth: 3
code-fold: true
code-summary: "Näytä koodi"
execute:
warning: false
message: false
---
```{r}
library(tidyverse)
library(scales)
library(here)
library(broom)
theme_set(
theme_minimal(base_size = 14)
)
billionaires <-
read_csv(
here("data", "processed", "billionaires_clean.csv"),
show_col_types = FALSE
)
billionaires_panel <-
read_csv(here("data","processed","billionaires_clean.csv"),show_col_types = FALSE
)
billionaires_latest <-
read_csv(here("data","processed","billionaires_latest.csv"),show_col_types = FALSE
)
country_year <-
read_csv(here("data","processed","country_year.csv"),show_col_types = FALSE
)
migration <-
read_csv(here("data","processed","migration.csv"),show_col_types = FALSE
)
gdp <-
read_csv(
here("data","raw","gdp_per_capita.csv"),show_col_types = FALSE,
skip = 4
) |>
pivot_longer(
`1960`:`2024`,
names_to = "year",
values_to = "gdp_pc"
) |>
mutate(
year = as.integer(year)
) |>
rename(
country = `Country Name`
)
population <-
read_csv(
here("data","raw","population.csv"),show_col_types = FALSE,
skip = 4
) |>
pivot_longer(
`1960`:`2024`,
names_to = "year",
values_to = "population"
) |>
mutate(
year = as.integer(year)
) |>
rename(
country = `Country Name`
)
patents <-
read_csv(
here("data","raw","patents.csv"),show_col_types = FALSE,
skip = 4
) |>
pivot_longer(
`1960`:`2024`,
names_to = "year",
values_to = "patents"
) |>
mutate(year = as.integer(year)) |>
rename(country = `Country Name`)
rd <-
read_csv(
here("data","raw","rd_gdp.csv"),show_col_types = FALSE,
skip = 4
) |>
pivot_longer(
`1960`:`2024`,
names_to = "year",
values_to = "rd_gdp"
) |>
mutate(year = as.integer(year)) |>
rename(country = `Country Name`)
country_year <-
billionaires |>
count(
country_citizenship,
year,
name = "n_billionaires"
) |>
left_join(
gdp,
by = c(
"country_citizenship" = "country",
"year"
)
) |>
left_join(
population,
by = c(
"country_citizenship" = "country",
"year"
)
) |>
left_join(
patents,
by = c(
"country_citizenship" = "country",
"year"
)
) |>
left_join(
rd,
by = c(
"country_citizenship" = "country",
"year"
)
) |>
mutate(
patents_pc =
patents / population * 1e6
)
```
## Tarvitseeko Suomi lisää miljardöörejä?
Helsingin Sanomat kysyi, tarvitseeko Suomi lisää miljardöörejä.
Kysymys herättää voimakkaita reaktioita. Osa näkee miljardöörit innovaatioiden moottorina. Osa pitää heitä merkkinä epätasa-arvosta.
Keskustelu jää usein mielipiteiden tasolle.
Data antaa mahdollisuuden tarkastella asiaa järjestelmällisemmin.
Sloganini on maailma on jakauma. Tämä pätee erityisesti varallisuuteen.
Miljardöörit eivät ole yksittäinen ilmiö. He ovat jakauma.
Tässä analyysissä tarkastelen:
* millaisia miljardöörit ovat?
* missä miljardöörit ovat?
* miten miljardöörit liittyvät talouteen?
* mitä tämä tarkoittaa Suomelle?
Käytän datana Forbesin julkaisemaa dataa miljardööreistä. Kyseinen data alkaa vuodesta 1997. Data ei kata kaikkia miljardöörejä. On olemassa ihmisiä, joiden omaisuus on monimutkaisten trusti- ja yristysjärjestelyjen takana ja he eivät ole tulleet julkisuuteen miljardööreinä. Samoin monen miljardöörin kohdalla omaisuuden arvo on teoreettinen, koska esimerkiksi osakkeiden arvot voivat vaihdella nopeasti ja kaiken omaisuuden muuntaminen rahaksi nopeasti olisi erittäin hankalaa.
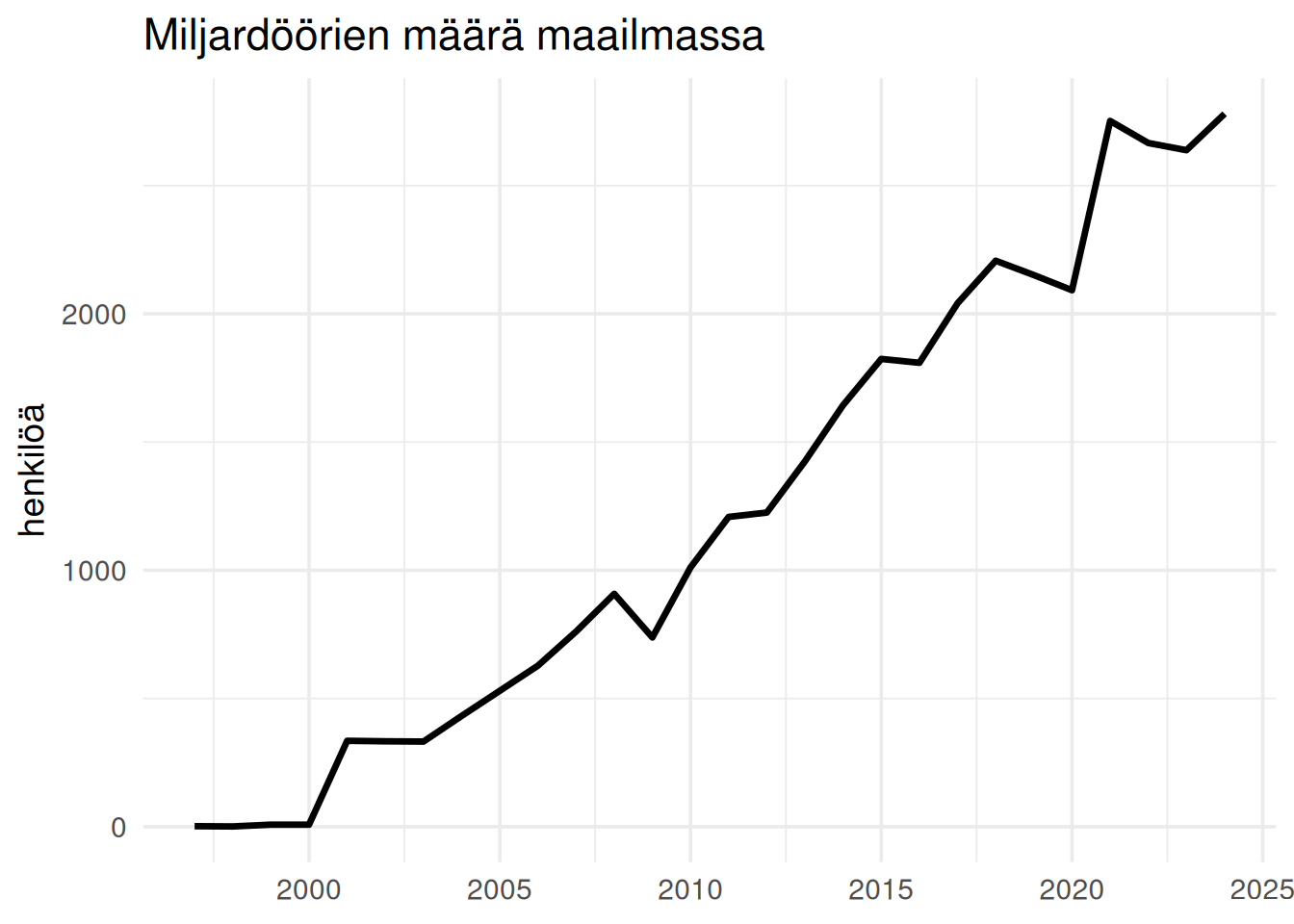
## Miljardöörien määrä on kasvanut nopeasti
Miljardöörit eivät ole uusi ilmiö, mutta heidän määränsä on kasvanut voimakkaasti.
Kasvu kiihtyi erityisesti 2000-luvulla.
```{r}
billionaires_panel |>
distinct(full_name, year) |>
count(year) |>
ggplot(aes(year, n)) +
geom_line(linewidth = 1.2) +
labs(
title = "Miljardöörien määrä maailmassa",
x = NULL,
y = "henkilöä"
)
```
Kasvu kertoo talouden rakenteellisesta muutoksesta.
Digitalisaatio mahdollistaa yritysten nopean skaalautumisen.
Globaalit markkinat kasvattavat potentiaalista asiakaskuntaa.
Pääoma keskittyy entistä voimakkaammin voittajille.
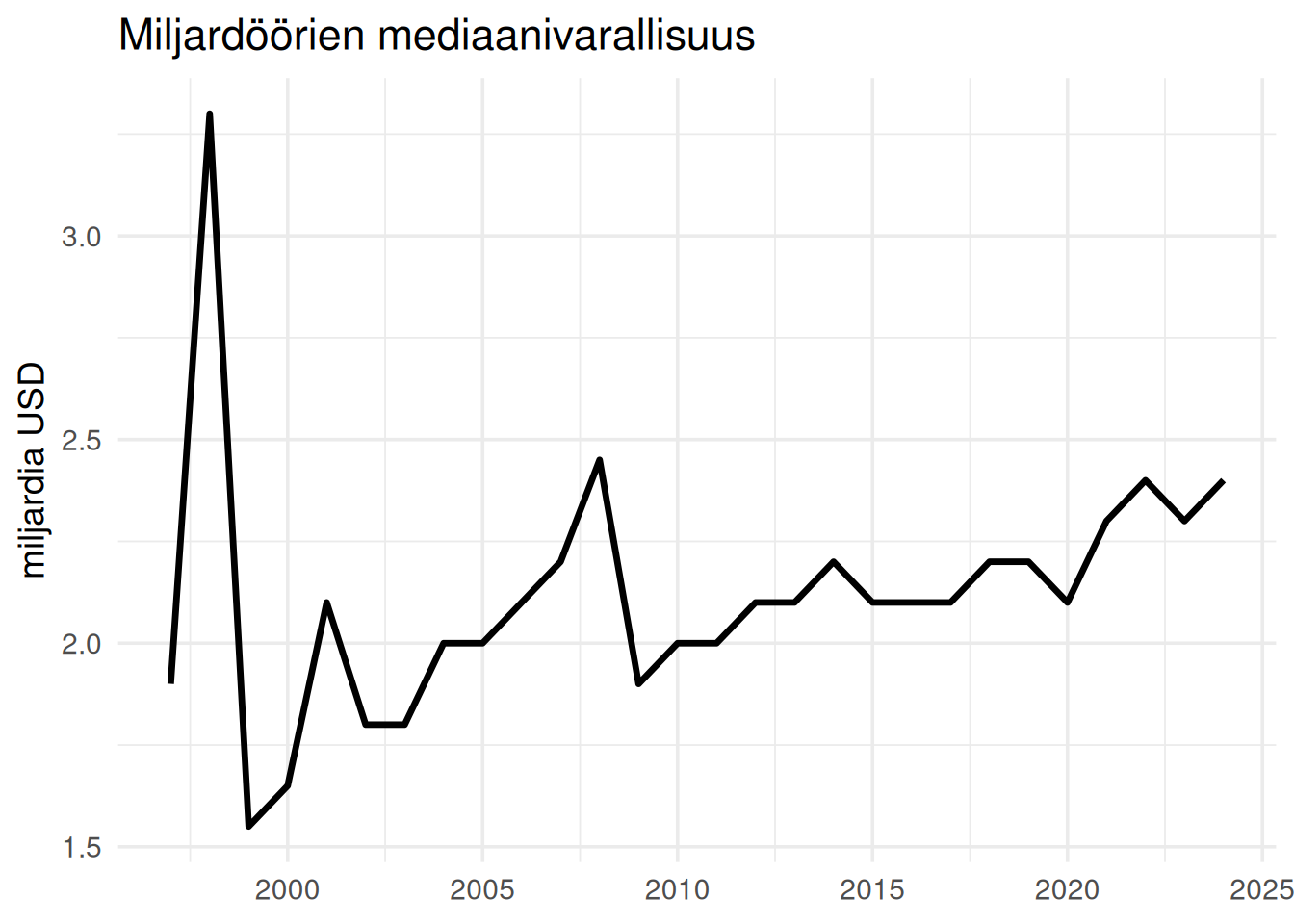
## Varallisuus on erittäin keskittynyttä
Miljardöörit eivät ole homogeeninen ryhmä.
Jakauma on voimakkaasti vino.
Suurin osa miljardööreistä on lähellä miljardin rajaa.
Hyvin pieni joukko omistaa kymmeniä tai satoja miljardeja.
```{r}
m <- billionaires_panel |>
filter(year ==max(year))|>
summarise(
mediaani = median(net_worth_usd) / 1e9,
keskiarvo = mean(net_worth_usd) / 1e9
)
```
Koska jakauma on hyvin vino, antaa mediaani keskiarvoa paremman kuvan miljardöörien todellisestä varallisuudesta. Varallisuuden keskiarvo vuonna 2024 oli `r m$keskiarvo` miljardia dollaria, mutta mediaani oli vain `r m$mediaani`. Taloudessa tällaiset jakaumat ovat yleisiä.
```{r}
billionaires_panel |>
group_by(year) |>
summarise(
median_wealth =
median(net_worth_usd),
.groups = "drop"
) |>
ggplot(aes(year, median_wealth / 1e9)) +
geom_line(linewidth = 1.2) +
labs(
title = "Miljardöörien mediaanivarallisuus",
y = "miljardia USD",
x = NULL
)
```
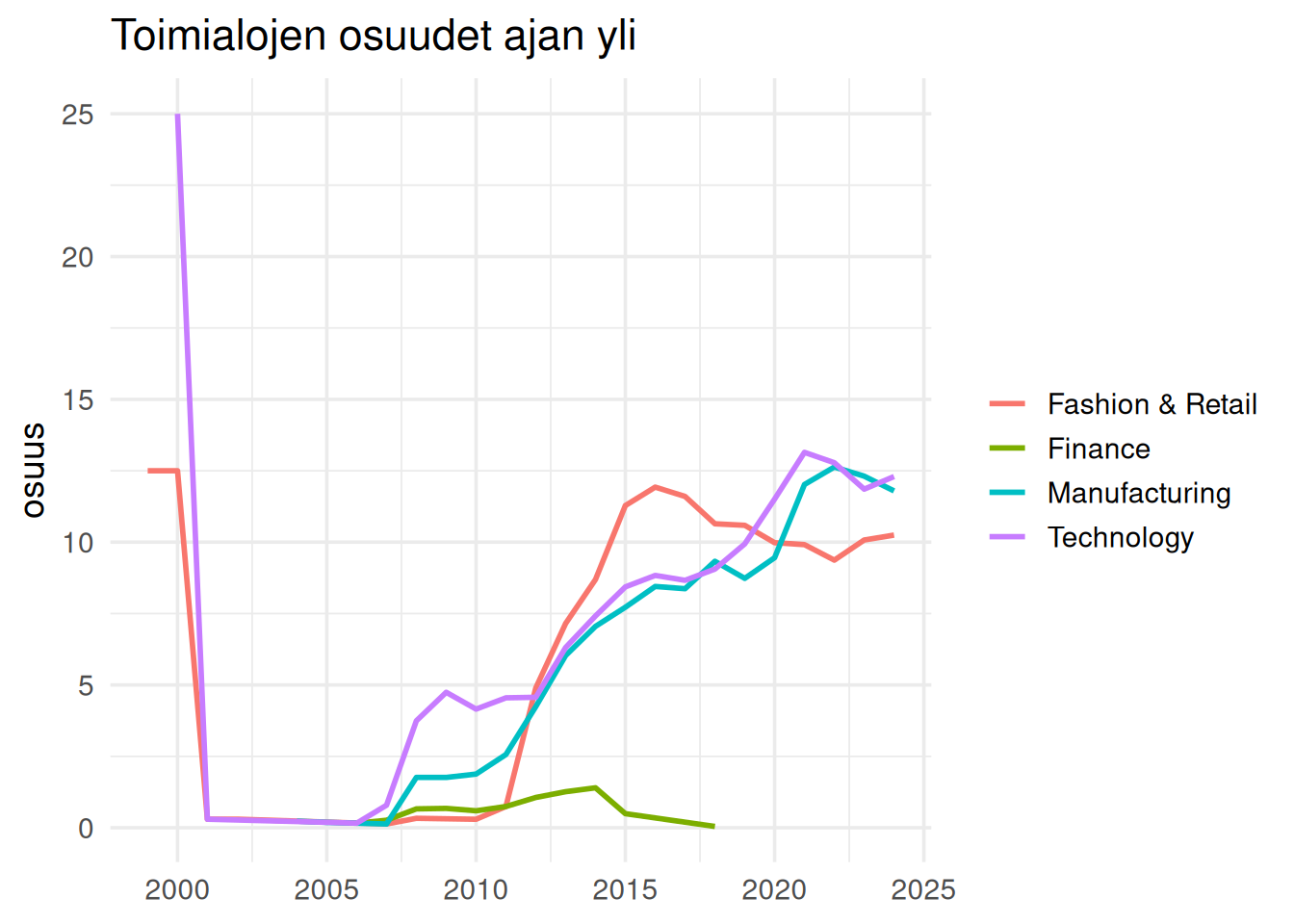
## Miljardöörit ovat keskittyneet tietyille toimialoille
Toimialajakauma kertoo, mistä varallisuus syntyy.
```{r}
billionaires_panel |>
count(
year,
business_category
) |>
group_by(year) |>
mutate(
share =
n / sum(n)*100
) |>
filter(
business_category %in%
c(
"Technology",
"Finance",
"Fashion & Retail",
"Manufacturing"
)
) |>
ggplot(aes(year, share,
color = business_category)) +
geom_line(linewidth = 1) +
labs(
title = "Toimialojen osuudet ajan yli",
y = "osuus",
x = NULL,
color = NULL
)
```
Skaalautuvat liiketoimintamallit tuottavat suurimmat varallisuudet.
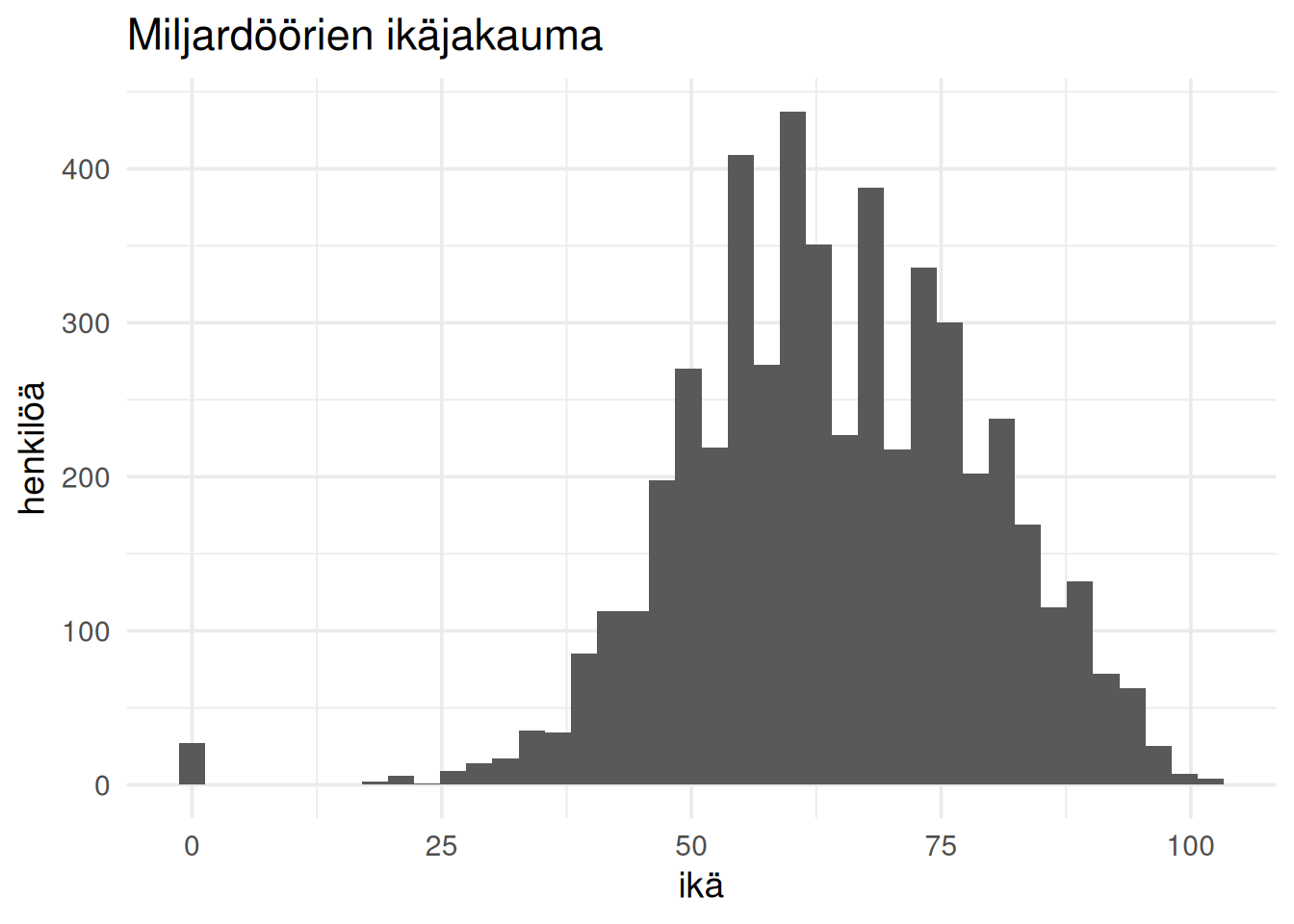
## Ikäjakauma kertoo urapoluista
Miljardöörit eivät ole erityisen nuoria.
Varallisuuden rakentaminen vie usein vuosikymmeniä.
```{r}
age_median <- median(billionaires_latest$age, na.rm = T)
billionaires_latest |>
ggplot(aes(age)) +
geom_histogram(bins = 40) +
labs(
title = "Miljardöörien ikäjakauma",
x = "ikä",
y = "henkilöä"
)
```
Miljardöörien mediaani-ikä on `r age_median` eli melko korkea. Tämä viittaa siihen, että miljardööriksi päätyminen on pitkä prosessi.
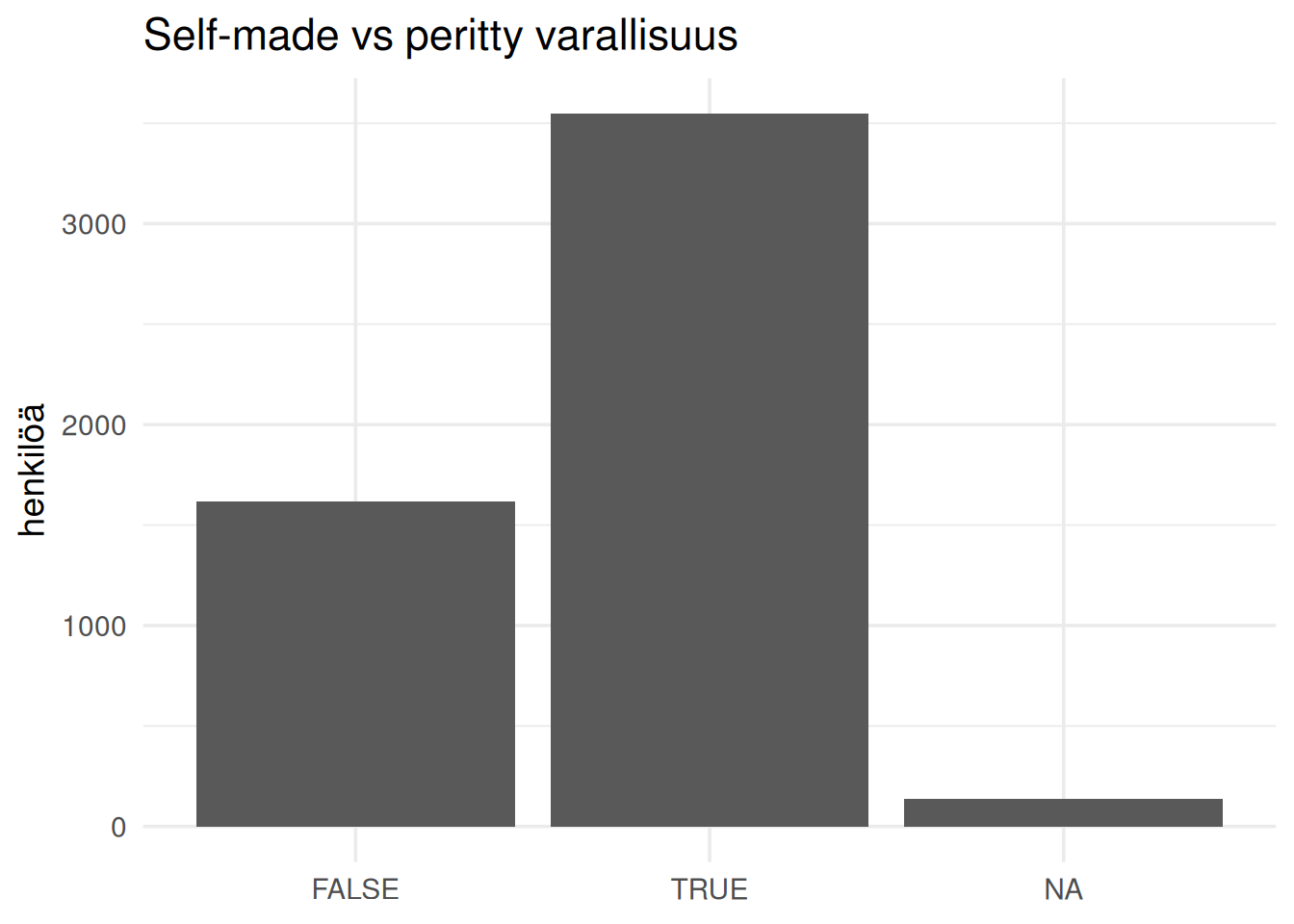
## Suurin osa miljardööreistä on self-made
Julkisuudessa usein mielikuva on peritystä varallisuudesta. Data kertoo toisin.
```{r}
billionaires_latest |>
count(self_made) |>
ggplot(aes(self_made, n)) +
geom_col() +
labs(
title = "Self-made vs peritty varallisuus",
x = NULL,
y = "henkilöä"
)
```
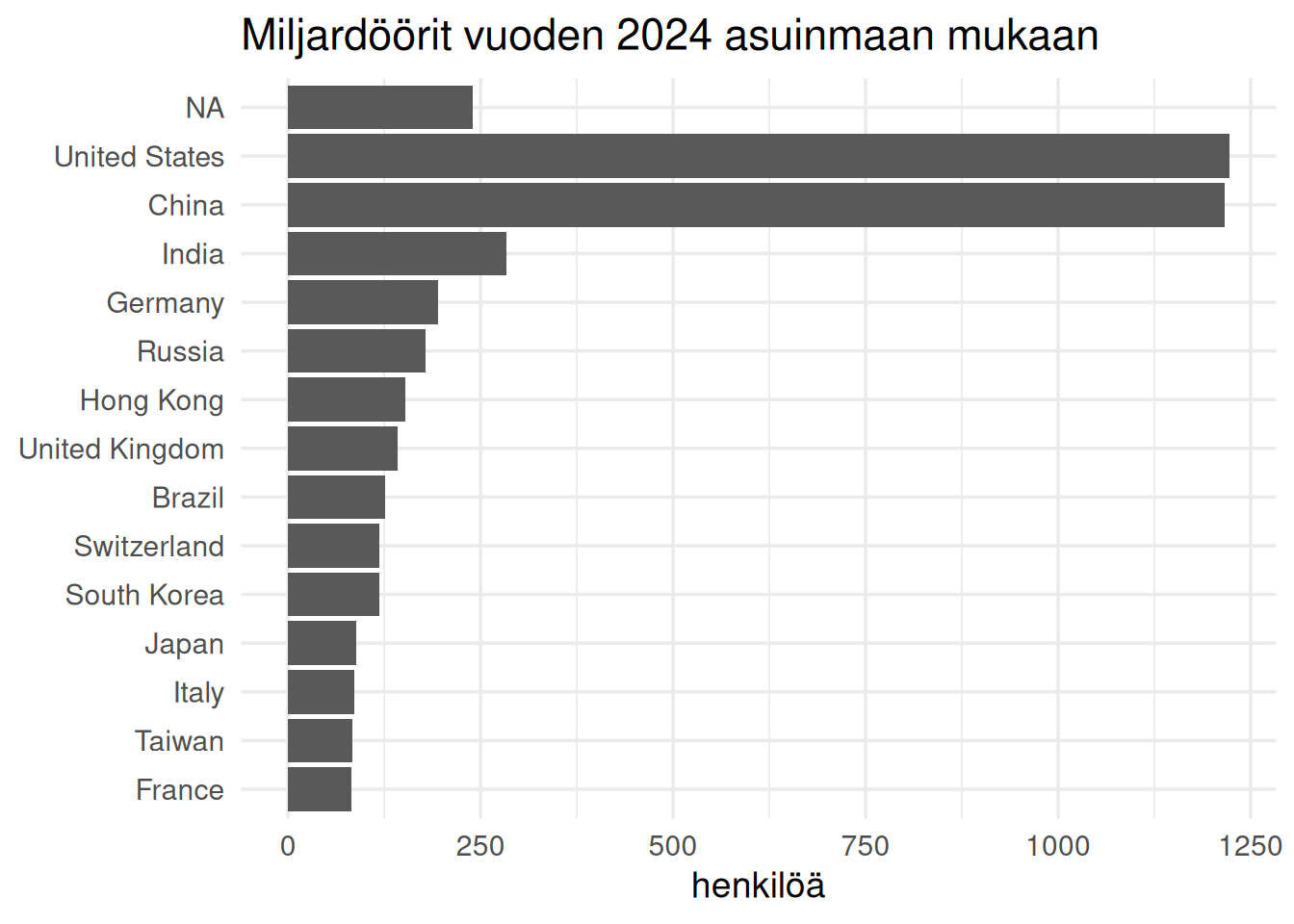
## Missä miljardöörit asuvat
Miljardöörit keskittyvät tiettyihin maihin.
Ekosysteemit näyttävät olevan tärkeitä.
```{r}
billionaires_latest |>
count(country_residence, sort = TRUE) |>
slice_head(n = 15) |>
ggplot(aes(reorder(country_residence, n), n)) +
geom_col() +
coord_flip() +
labs(
title = "Miljardöörit vuoden 2024 asuinmaan mukaan",
x = NULL,
y = "henkilöä"
)
```
Yhdysvallat dominoi.
Kiina on noussut nopeasti.
Euroopassa miljardöörit jakautuvat useampaan maahan.
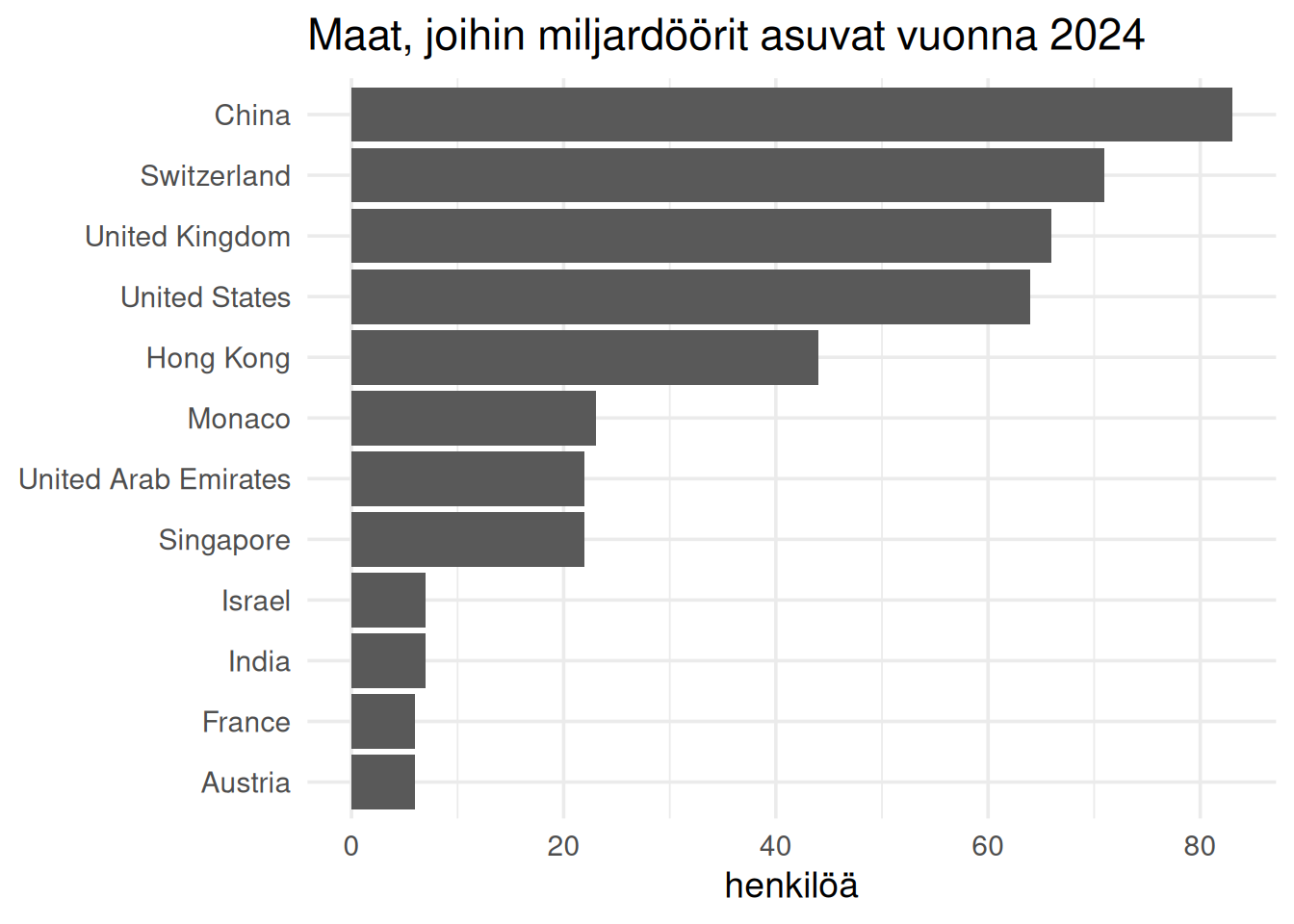
## Kaikki eivät asu syntymämaassaan
Kansalaisuus ja asuinmaa eivät aina ole samat.
Tämä liittyy verotukseen, yritysilmastoon ja liiketoimintaympäristöön.
```{r}
billionaires_latest |>
filter(
country_residence_iso3 != country_citizenship_iso3
) |>
count(country_residence, sort = TRUE) |>
slice_head(n = 12) |>
ggplot(aes(reorder(country_residence, n), n)) +
geom_col() +
coord_flip() +
labs(
title = "Maat, joihin miljardöörit asuvat vuonna 2024",
x = NULL,
y = "henkilöä"
)
```
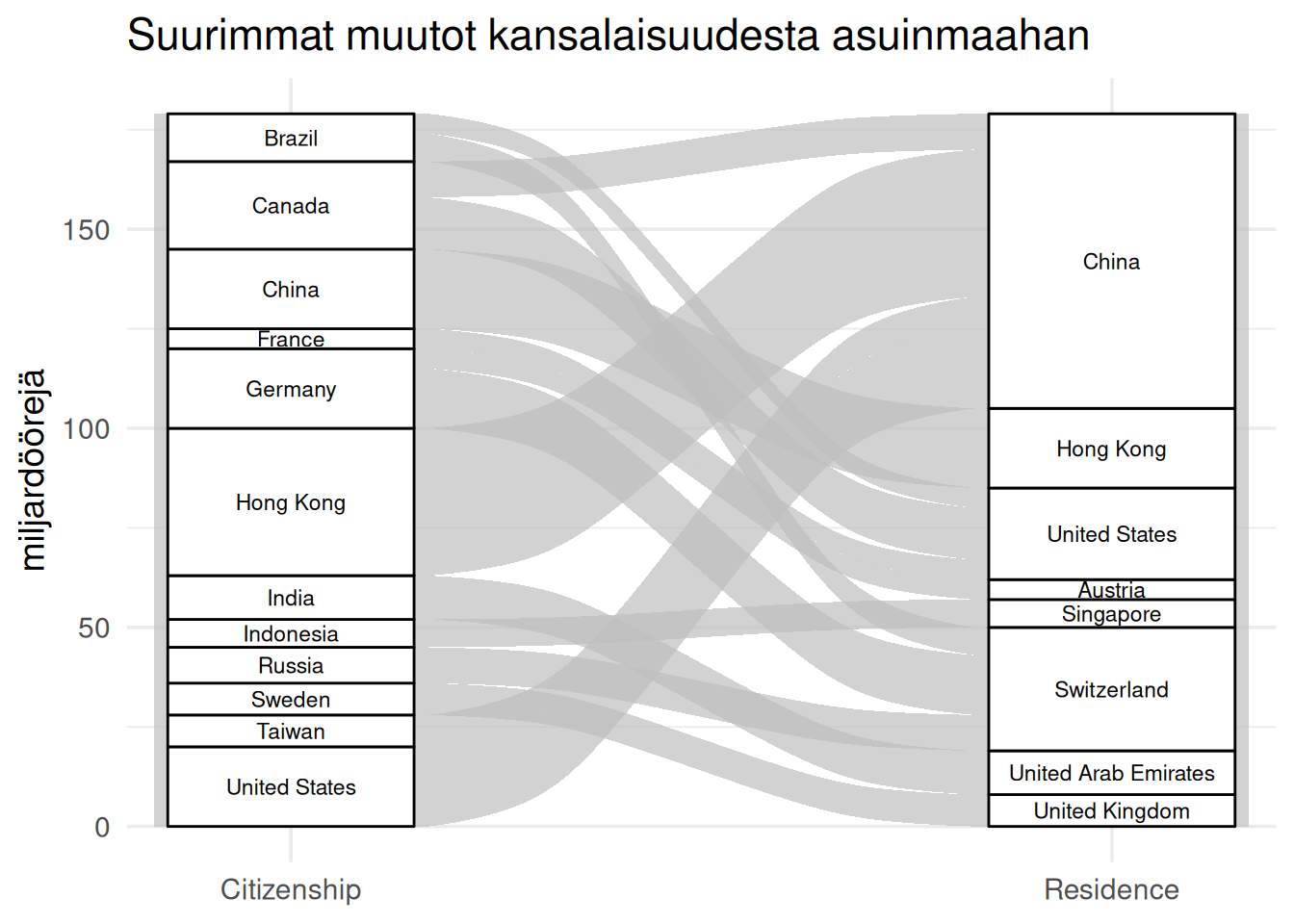
Kiinnostavampaa on kuitenkin miljardöörien muuttoliike.
```{r}
migration_clean <-
billionaires_latest |>
filter(
country_residence_iso3 !=
country_citizenship_iso3
) |>
count(
country_citizenship,
country_residence,
sort = TRUE
) |>
mutate(
pair =
paste(
country_citizenship,
"→",
country_residence
)
)
top_migration <-
migration_clean |>
slice_head(n = 15)
library(ggalluvial)
top_migration |>
ggplot(
aes(
axis1 =
country_citizenship,
axis2 =
country_residence,
y = n
)
) +
geom_alluvium(
alpha = 0.7
) +
geom_stratum(
width = 0.3
) +
geom_text(
stat = "stratum",
aes(label = after_stat(stratum)),
size = 3
) +
scale_x_discrete(
limits = c(
"Citizenship",
"Residence"
),
expand = c(.1, .1)
) +
labs(
title =
"Suurimmat muutot kansalaisuudesta asuinmaahan",
y = "miljardöörejä"
)
```
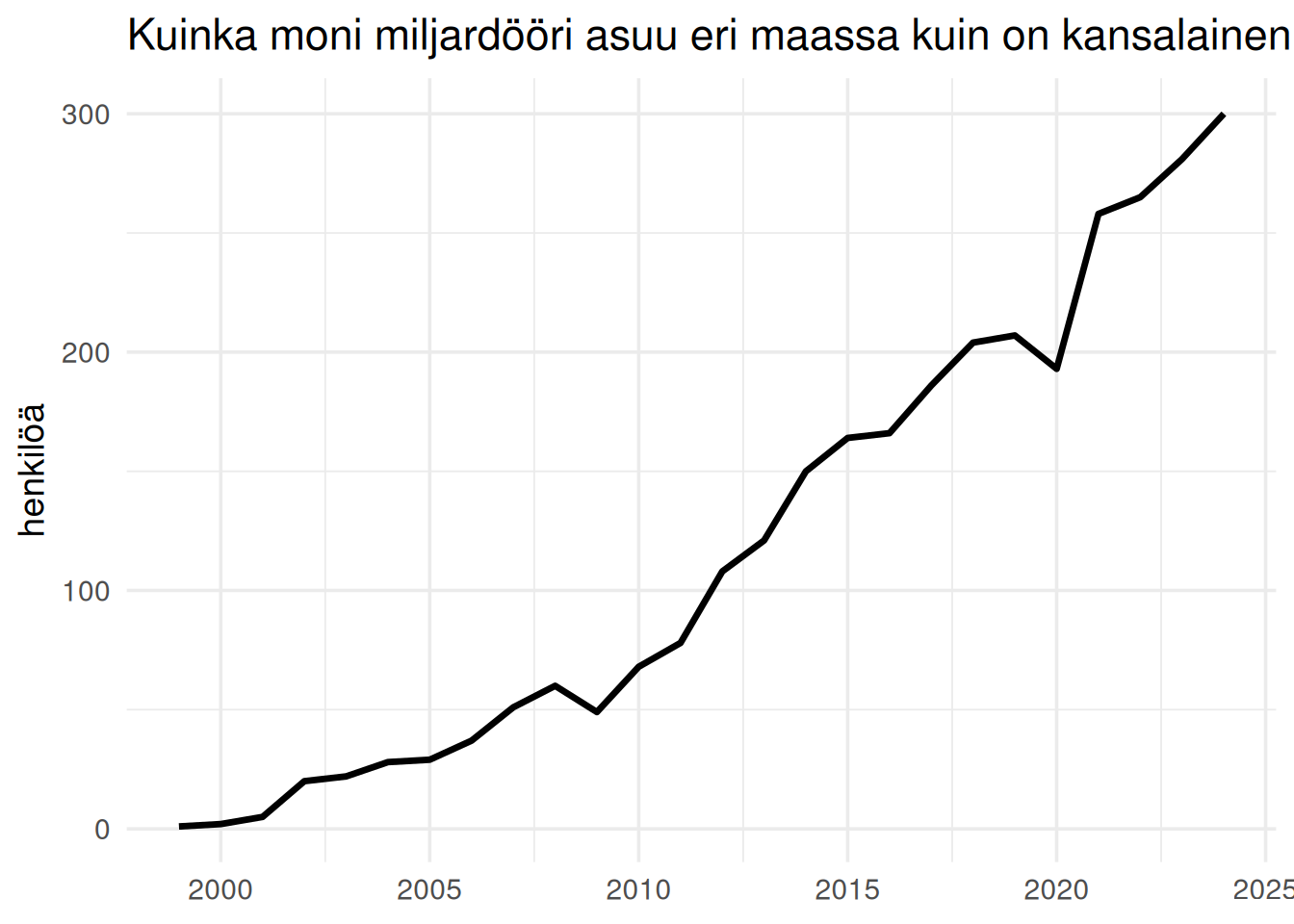
Kuten kuvasta nähdään, miljardöörit asuvat usein maaassa, joka ei ole heidän kansallisuutensa. Varsinkin Kiina ja Sveitsi saavat muuttajia.
Vielä mielenkiintoisempi on tilasto muuuttajista vuositasolla. Se antaa kuvaa siitä, miten miljardöörit vaihtavat valtioita.
```{r}
migration_year <-
billionaires_panel |>
filter(
country_residence_iso3 !=
country_citizenship_iso3
) |>
distinct(
full_name,
year
) |>
count(year)
ggplot(
migration_year,
aes(year, n)
) +
geom_line(linewidth = 1.2) +
labs(
title =
"Kuinka moni miljardööri asuu eri maassa kuin on kansalainen",
y = "henkilöä",
x = NULL
)
```
Katsotaan vielä muuttamista maiden tasolla yli ajan.
```{r}
library(ggraph)
library(igraph)
edges <-
billionaires_latest |>
filter(
country_residence_iso3 !=
country_citizenship_iso3
) |>
count(
country_citizenship,
country_residence,
sort = TRUE
) |>
filter(n > 5)
g <-
graph_from_data_frame(edges)
ggraph(g, layout = "fr") +
geom_edge_link(
aes(width = n),
alpha = 0.4
) +
geom_node_point(size = 4) +
geom_node_text(
aes(label = name),
repel = TRUE
) +
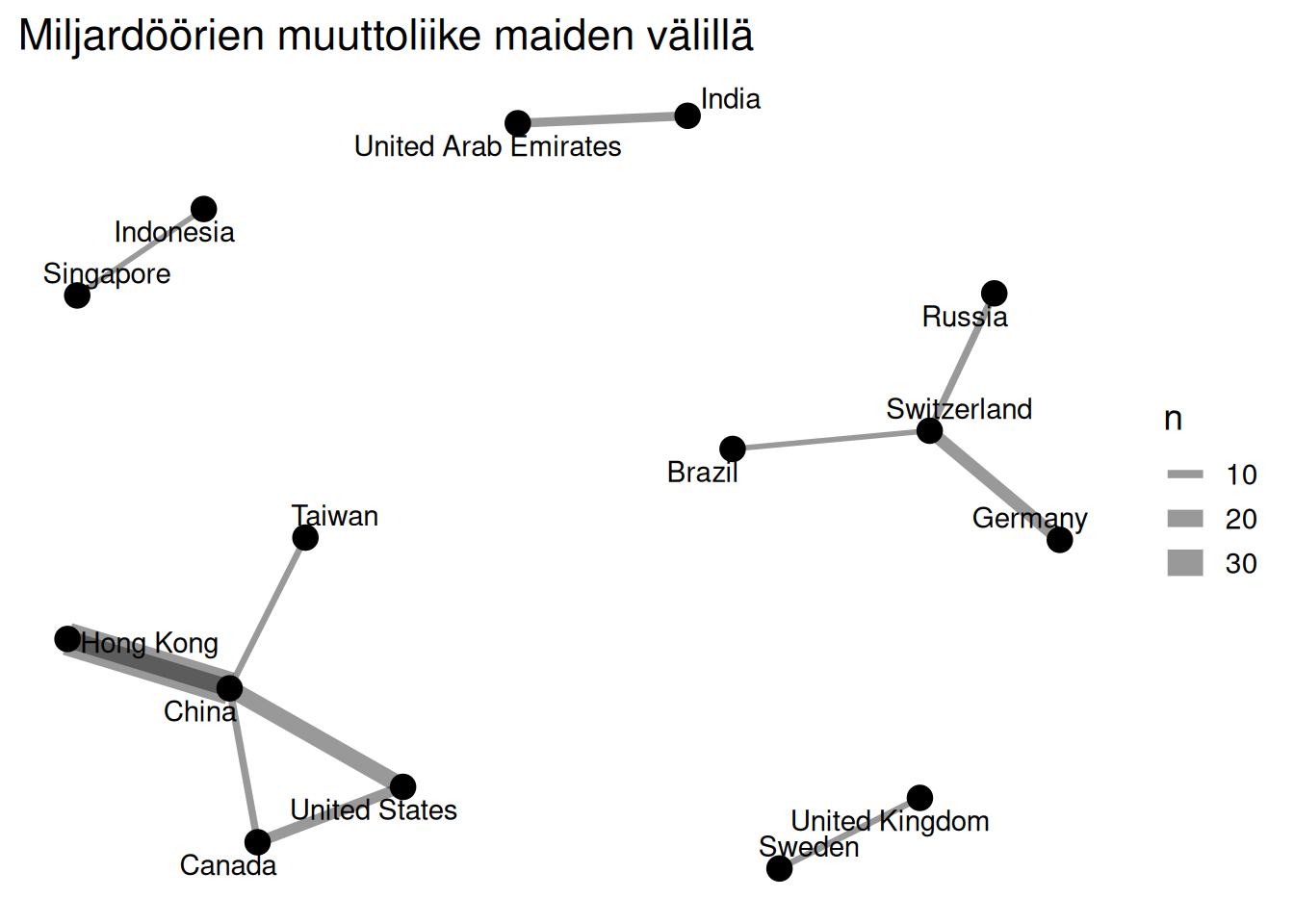
labs(
title =
"Miljardöörien muuttoliike maiden välillä"
)
```
Kuten kuvasta nähdään, on tiettyjä maita, jotka selkäesti vetävät miljardöörejä puoleensa ja joiden välillä muutetaan ajan kuluessa jopa useita kertoja. Tämä biljonäärien muuttoliike maiden välilä on hyvin laaja teema, joka ansaitsisi jopa oman postauksensa.
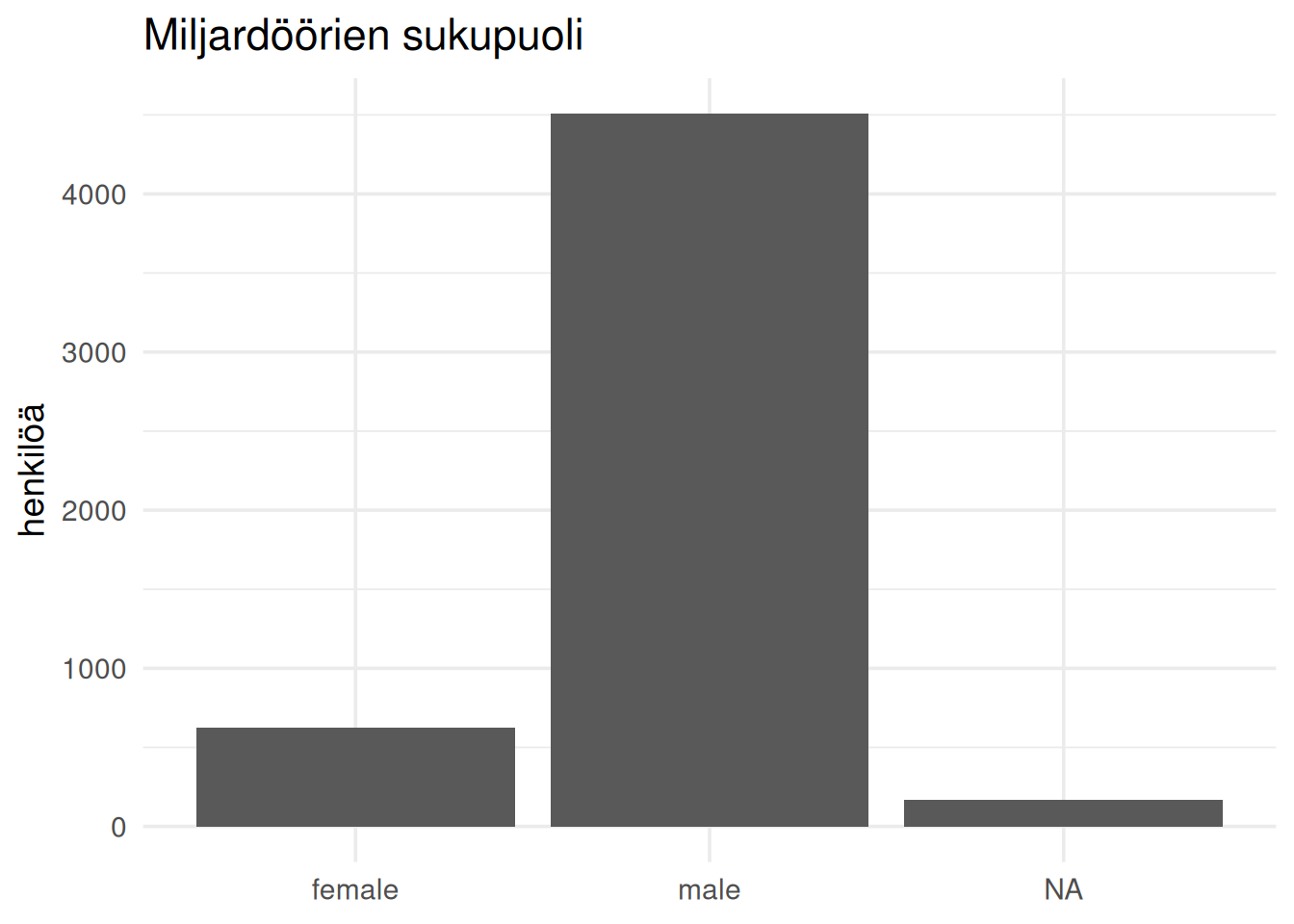
## Sukupuolijakauma on epätasainen
```{r}
billionaires_latest |>
count(gender) |>
ggplot(aes(gender, n)) +
geom_col() +
labs(
title = "Miljardöörien sukupuoli",
x = NULL,
y = "henkilöä"
)
```
Kuten huomataan, valtaosa biljonääreistä on miehiä.
## Mallinnus
Kun data on käyty läpi, päästään viimein itse asiaan eli siihen, mikä ennustaa miljardöörien määrää ja tarvitseeko mallin mukaan Suomi niitä lisää? Käytetään miljardööridatan lisäksi datana BKT:tä per asukas, patenttien määrää, tutkimus- ja kehitysmenojen osuutta BKT:stä (R&D) ja väestömäärää.
```{r}
model_df <-
country_year |>
filter(
population > 1e6,
!is.na(gdp_pc),
!is.na(patents_pc),
!is.na(rd_gdp)
)
fit <-
glm(
n_billionaires ~
log(population)
+ log(gdp_pc)
+ log(patents_pc + 1)
+ rd_gdp,
family = poisson(),
data = model_df
)
```
Käytetään mallinnukseen yleisettyä lineaarista mallia (glm). Tulos on alla:
```{r}
model_df |>
mutate(
pred =
predict(
fit,
type = "response"
)
) |>
ggplot(
aes(
pred,
n_billionaires
)
) +
geom_point(alpha = 0.3) +
geom_abline(linetype = "dashed") +
scale_x_log10() +
scale_y_log10() +
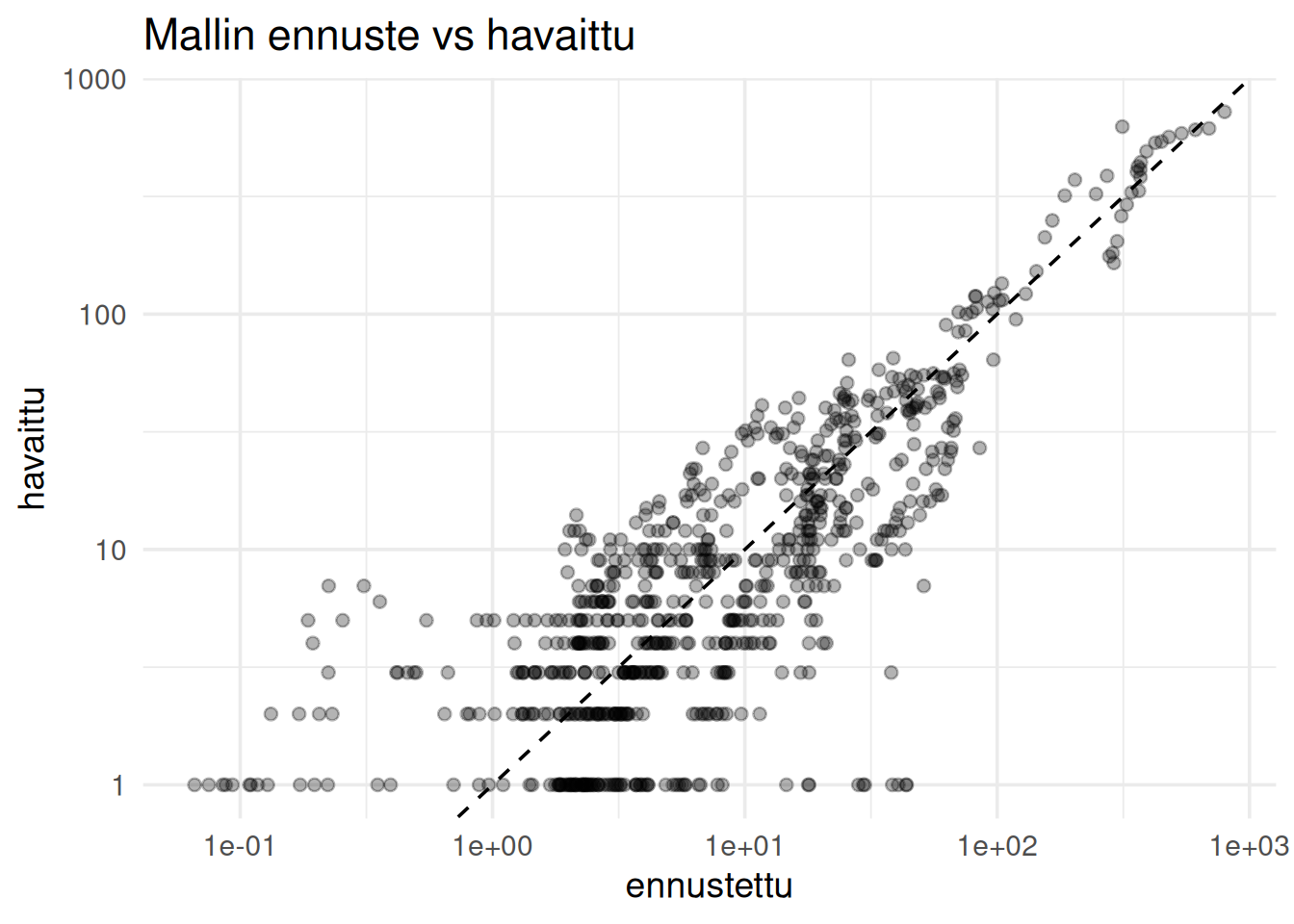
labs(
title =
"Mallin ennuste vs havaittu",
x =
"ennustettu",
y =
"havaittu"
)
```
Kuvassa siis jokainen piste on yksi valtio ja pystyakselilla on todelliset miljardöörien määrät ja vaaka-akselilla on ennusteet. Suora kertoo sen linjan, millä tulosten tulisi olla.
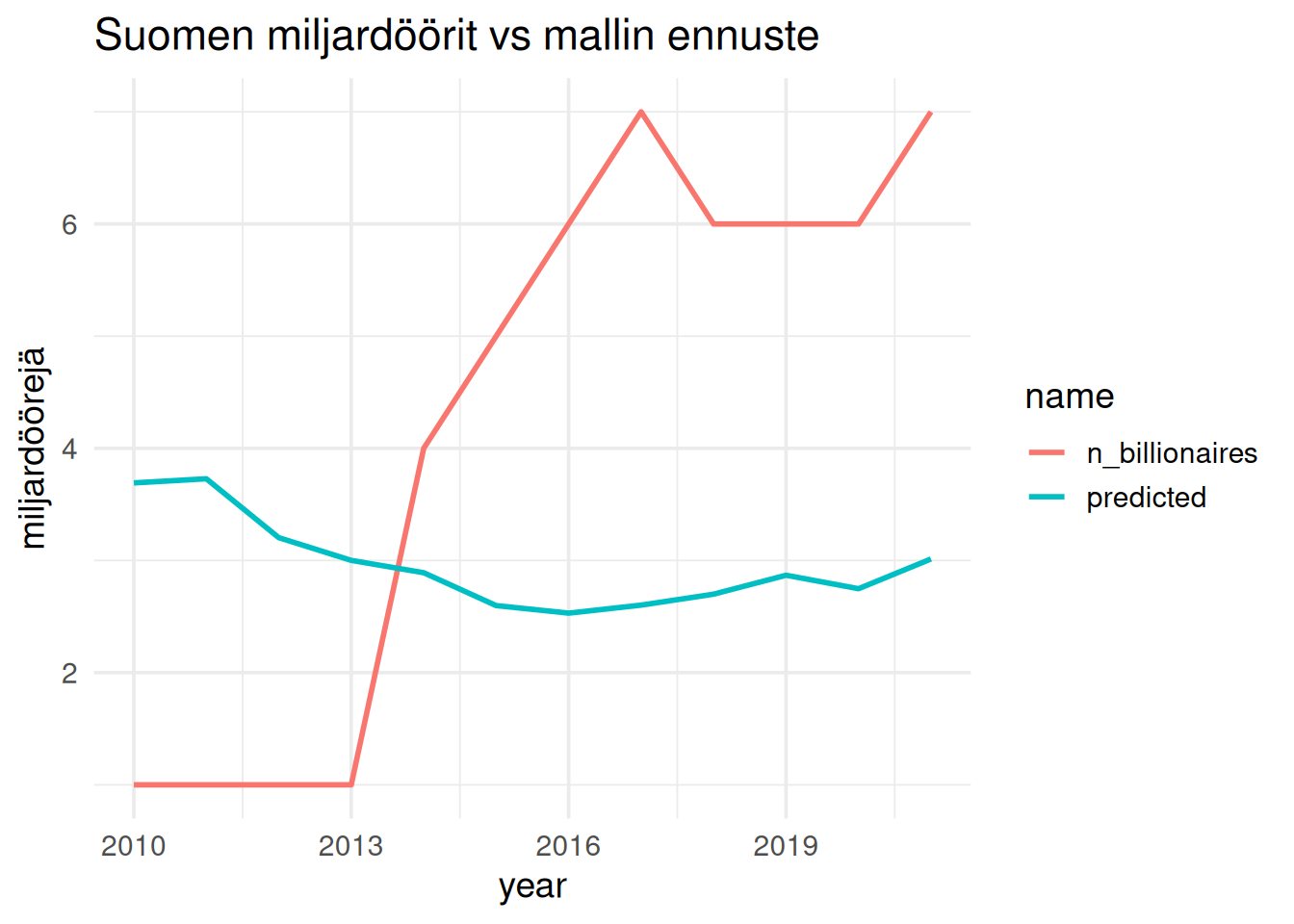
## Suomen ennuste
Entä sitten Suomi? Mitä malli näyttää Suomelle?
```{r}
finland <-
model_df |>
filter(
country_citizenship ==
"Finland"
)
finland |>
mutate(
predicted =
predict(
fit,
newdata = finland,
type = "response"
)
) |>
pivot_longer(
c(
n_billionaires,
predicted
)
) |>
ggplot(
aes(
year,
value,
colour = name
)
) +
geom_line(linewidth = 1) +
labs(
title =
"Suomen miljardöörit vs mallin ennuste",
y =
"miljardöörejä"
)
```
Malli ei näytä kovinkaaan toimivalta, mutta tämä tarkoittaa vain sitä, että testaamista pitää jatkaa, Otetaan seuraavaksi käyttöön bayeslainen malli, koska miljardöörit ovat harvinainen ilmiö ja lisäksi miljardööriksi päätymisessä on aina mukana aimo annos satunnaisuutta.
Lisäksi otetaan mukaan lag-parametri, joka kuvaa sitä, että jo olemassaolevat miljardöörit tuottavat lisää miljardöörejä, koska harva miljardööri istuu rahojensa päällä, kuten Roope Ankka, vaan hän yleensä sijoittaa niitä edelleen uusiin yrityksiin ja näiden perustajista taas tulee uusia miljardöörejä.
## Bayeslainen malli
```{r}
library(brms)
country_year <-
country_year |>
arrange(
country_citizenship,
year
) |>
group_by(
country_citizenship
) |>
mutate(
lag_billionaires =
lag(n_billionaires),
lag_billionaires =
coalesce(lag_billionaires, 0)
) |>
ungroup()
bayes_df <-
country_year |>
filter(
population > 1e6,
!is.na(gdp_pc),
!is.na(patents_pc),
!is.na(rd_gdp)
) |>
mutate(
log_pop =
log(population),
log_gdp =
log(gdp_pc),
log_pat =
log(patents_pc + 1),
rd =
rd_gdp / 100
)
fit_feedback <-
brm(
n_billionaires ~
log_pop
+ log_gdp
+ log_pat
+ rd
+ lag_billionaires
+ (1 | country_citizenship),
family = negbinomial(),
data = bayes_df,
chains = 4,
iter = 2000,
refresh = 0
)
```
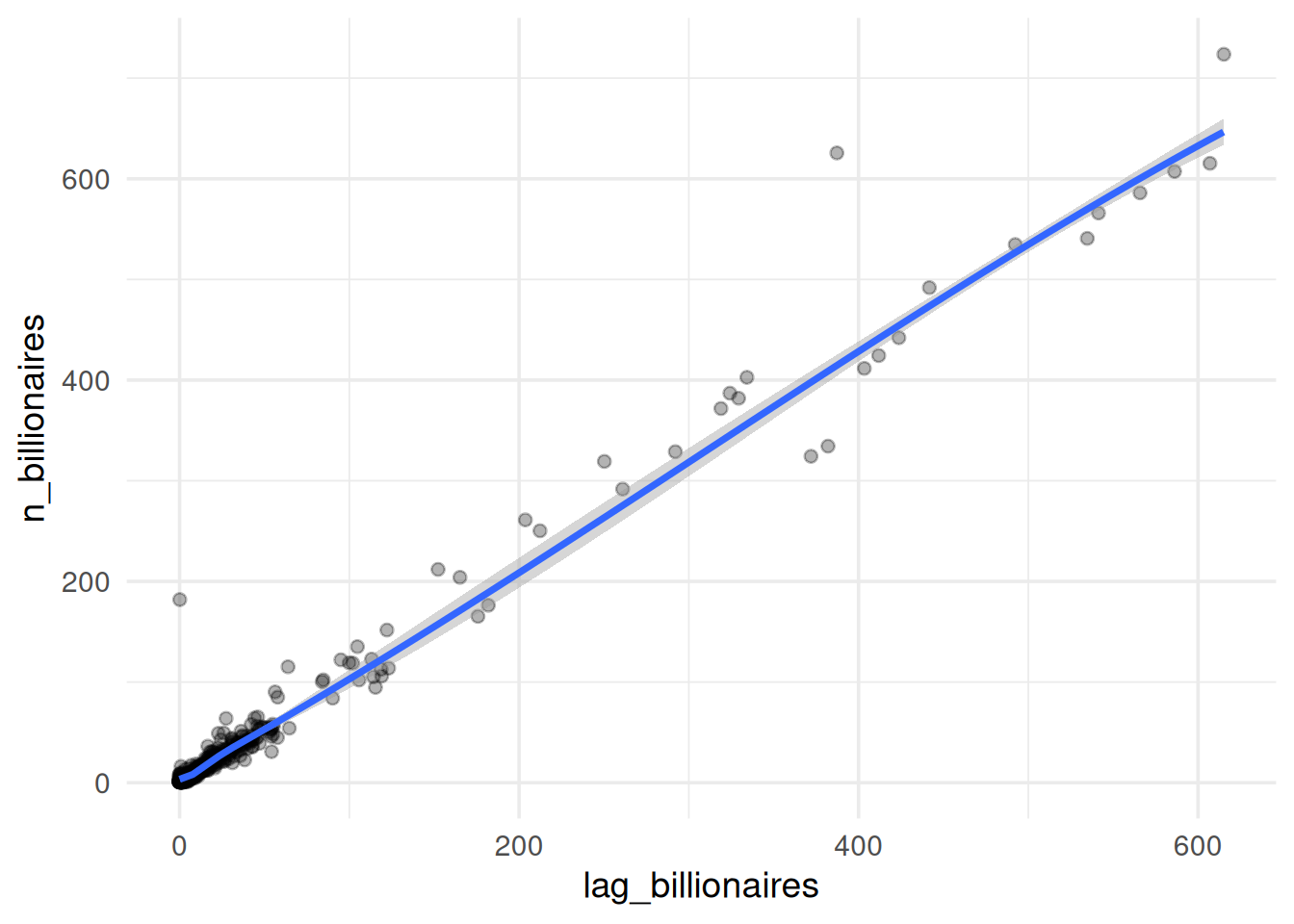
Visualisoidaan tämä malli.
```{r}
bayes_df |>
ggplot(
aes(
lag_billionaires,
n_billionaires
)
) +
geom_jitter(
alpha = 0.3
) +
geom_smooth()
```
Kuten nähdään, malli on huomattavasti parempi. Miljardöörit siis kasaantuvat sinne, missä niitä on ennestäänkin.
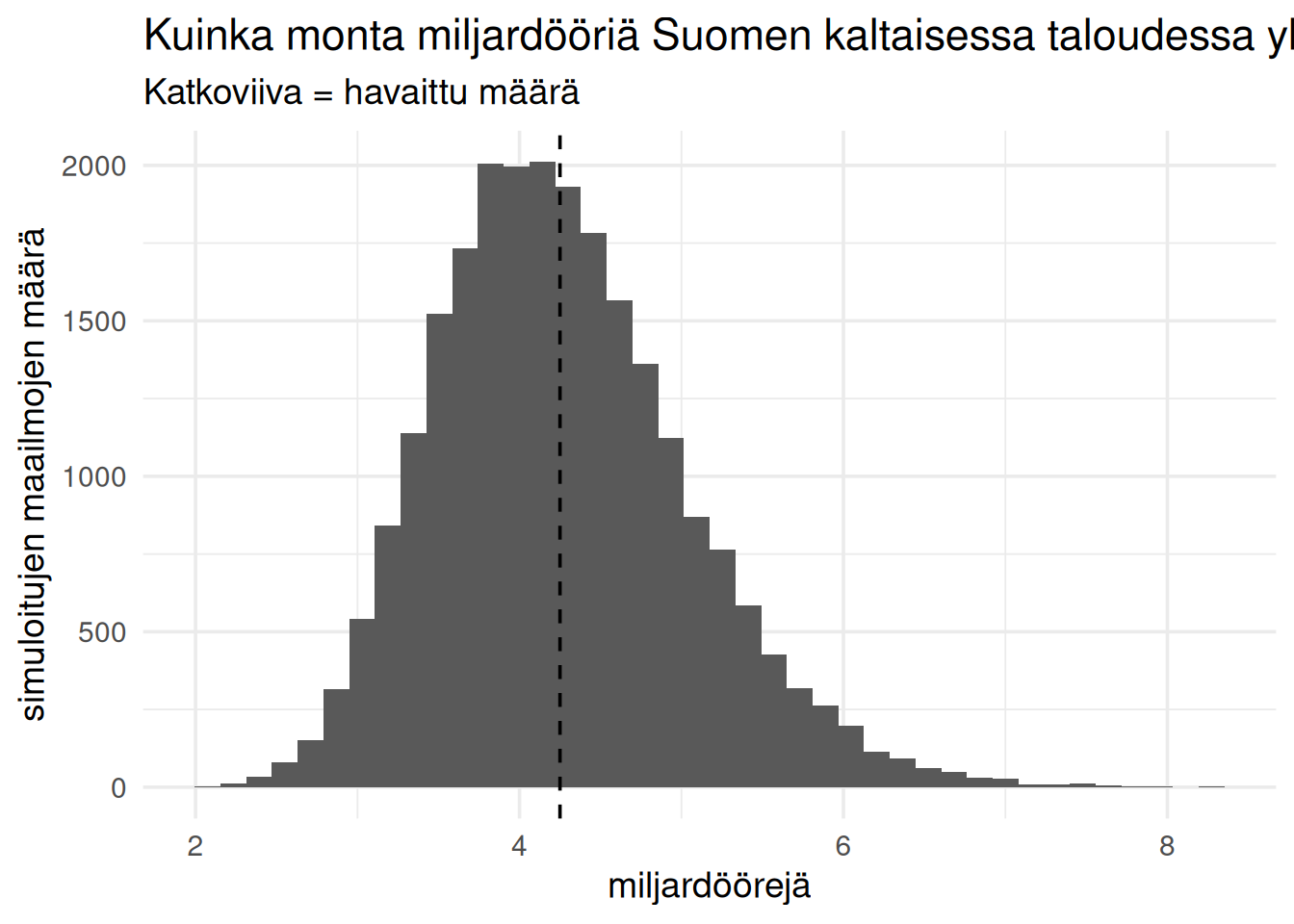
## Bayes-jakauma ja Suomi
Koska Bayes-jakauma näyttää toimivan hyvin koko maailmalle, on seuraava looginen askel kokeilla sitä Suomen osalta.
```{r}
finland <-
bayes_df |>
filter(
country_citizenship == "Finland"
)
observed_finland <-
mean(finland$n_billionaires)
library(tidybayes)
finland_post <-
add_epred_draws(
fit_feedback,
newdata = finland,
ndraws = 2000
)
finland_post |>
ggplot(
aes(.epred)
) +
geom_histogram(
bins = 40
) +
geom_vline(
xintercept = observed_finland,
linetype = "dashed"
) +
labs(
title =
"Kuinka monta miljardööriä Suomen kaltaisessa taloudessa yleensä on?",
subtitle =
"Katkoviiva = havaittu määrä",
x =
"miljardöörejä",
y =
"simuloitujen maailmojen määrä"
)
```
Kuvio ei näytä todennäköisyyttä siitä, että Suomi saisi miljardöörejä.
Kuvio näyttää, kuinka monta miljardööriä Suomen kaltaisessa taloudessa tyypillisesti esiintyy, kun huomioidaan epävarmuus datassa ja mallissa.
Malli simuloi tuhansia vaihtoehtoisia maailmoja, joissa Suomen talouden kehitys on hieman erilainen. Jokaisessa simuloidussa maailmassa syntyy tietty määrä miljardöörejä.
Histogrammi näyttää näiden mahdollisten maailmojen jakauman.
Jos jakauma keskittyy esimerkiksi välille 1–3, malli arvioi, että Suomen kokoinen ja rakenteinen talous tuottaa tyypillisesti muutaman miljardöörin.
Yksittäinen havaittu luku ei siis ole koko tarina.
Olennaista on, sijoittuuko Suomi jakauman keskelle vai sen reunoille.
Käytännössä siis:
*jos katkoviiva on keskellä jakaumaa*, niin Suomi ei poikkea odotetusta. Tällöin Suomen miljardöörien määrä on linjassa talouden rakenteen kanssa.
*jos katkoviiva on vasemmassa reunassa*, niin Suomi tuottaa vähemmän miljardöörejä kuin malli ennustaisi.
*jos katkoviiva on oikeassa reunassa*, niin Suomi tuottaa enemmän miljardöörejä kuin odotettaisiin.
Tämän mallin perusteella vaikuttaisi siis siltä, että Suomessa on se määrä miljardöörejä kuin tämänkokoisesa kansantaloudessa kuuluukin olla.
Kaipaatko analyysiä tai onko sinulla projekti, jonka haluat toteuttaa? Ota yhteyttä kristian.vepsalainen@proton.me . Olen käytettävissäsi.