---
title: "Työvoimapula on 10 ammatin ongelma"
subtitle: "Osa 2 – Kohtaanto-ongelmat ammattitasolla"
author: "Kristian Vepsäläinen"
date: 2026-04-17
categories:
- data science
- työmarkkinat
- talous
- R
- tilastotiede
format:
html:
code-fold: true
code-summary: "Näytä koodi"
toc: true
toc-depth: 3
number-sections: true
execute:
warning: false
message: false
slug: suomen-tyovoimapula-osa2
---
## Tiivistelmä
[Edellisessä osassa](../2024-04-08-osa1-tyomakkinat/index.html) osoitimme Beveridge-käyrällä, että Suomen työmarkkinoiden kohtaanto on heikentynyt vuoden 2020 jälkeen. Samalla työttömyystasolla on enemmän avoimia työpaikkoja kuin ennen pandemiaa.
Mutta tämä on edelleen aggregaattitason tulos. Se kertoo, **että** kohtaanto on heikentynyt, mutta ei **missä**.
Tässä osassa puramme kohtaanto-ongelman ammattitasolle.
Keskeinen tulos: Suomessa ei ole yleistä työvoimapulaa. On pieni joukko ammatteja, joissa kysyntä ylittää tarjonnan selvästi — ja suuri joukko ammatteja, joissa tilanne on päinvastainen.
Maailma on jakauma. Myös kohtaanto-ongelma on jakauma.
---
## Miten kohtaantoa mitataan ammattitasolla?
Edellisessä osassa käytimme makrotason mittareita: kokonaistyöttömyyttä ja avoimien työpaikkojen kokonaismäärää. Nyt tarvitsemme samat muuttujat ammattiryhmittäin.
Tilastokeskuksen työnvälitystilasto tarjoaa tämän. Se raportoi kuukausittain:
- työttömät työnhakijat ammattiryhmittäin (ISCO-08-luokitus)
- avoimet työpaikat ammattiryhmittäin
Näistä voimme laskea jokaiselle ammattiryhmälle **kohtaantosuhteen**:
$$
\text{Kohtaantosuhde} = \frac{\text{Avoimet työpaikat}}{\text{Työttömät työnhakijat}}
$$
Tulkinta:
- suhdeluku > 1 → avoimia työpaikkoja on enemmän kuin työttömiä → **pula**
- suhdeluku < 1 → työttömiä on enemmän kuin avoimia paikkoja → **ylitarjonta**
- suhdeluku ≈ 1 → suunnilleen tasapainossa
Yksi luku koko taloudelle peittää alleen sen, että eri ammateissa tilanne voi olla täysin päinvastainen.
---
```{r}
#| echo: false
library(tidyverse)
library(readxl)
library(here)
library(scales)
library(zoo)
theme_set(theme_minimal(base_size = 14))
```
## Ammattitason data Tilastokeskuksesta
Data on Tilastokeskuksen työnvälitystilastosta (taulukko 12ti). Se sisältää työttömät työnhakijat ja avoimet työpaikat ammattiryhmittäin kuukausittain vuodesta 2008 lähtien.
```{r}
#| label: data-luku
#| code-summary: "Datan luku ja muokkaus"
polku <- here("data", "raw", "unemployment", "tyopaikat_ja_tyottomat.xlsx")
# -----------------------------------------------------------
# 1. Luetaan headerit: kuukaudet riviltä 3
# -----------------------------------------------------------
rivi3 <- read_excel(polku, sheet = 1, range = cell_rows(3),
col_names = FALSE, col_types = "text") |>
unlist(use.names = FALSE)
# -----------------------------------------------------------
# 2. Luetaan data ilman headeria, kaikki tekstinä
# -----------------------------------------------------------
df_raw <- read_excel(polku, sheet = 1, skip = 4,
col_names = FALSE, col_types = "text")
# Annetaan geneerinen nimi joka sarakkeelle
names(df_raw) <- paste0("V", seq_len(ncol(df_raw)))
# -----------------------------------------------------------
# 3. Sarake 1 = alue, sarake 2 = ammattiryhmä,
# siitä eteenpäin parit: työttömät, avoimet, työttömät, avoimet...
# -----------------------------------------------------------
# Kuukaudet headerista: rivi3 sisältää kuukauden joka toisessa sarakkeessa
# alkaen sarakkeesta 3
kk_vec <- rivi3[seq(3, length(rivi3), by = 2)]
kk_vec <- kk_vec[!is.na(kk_vec)]
# Rakennetaan pitkä data käsin
alue_col <- df_raw$V1
amm_col <- df_raw$V2
# Täytetään alue
alue_col[alue_col == "" | is.na(alue_col)] <- NA_character_
alue_col <- zoo::na.locf(alue_col, na.rm = FALSE)
# Data-sarakkeet alkavat kolmannesta
data_cols <- df_raw[, 3:ncol(df_raw)]
# Joka pariton sarake = työttömät, parillinen = avoimet
n_pairs <- ncol(data_cols) %/% 2
rows <- list()
for (i in seq_len(n_pairs)) {
tyot_col <- data_cols[[2 * i - 1]]
avoi_col <- data_cols[[2 * i]]
kk_label <- if (i <= length(kk_vec)) kk_vec[i] else NA_character_
rows[[i]] <- tibble(
alue = alue_col,
ammattiryhma = amm_col,
kuukausi = kk_label,
tyottomat = suppressWarnings(as.numeric(tyot_col)),
avoimet = suppressWarnings(as.numeric(avoi_col))
)
}
df_long <- bind_rows(rows) |>
filter(
!is.na(kuukausi),
!is.na(ammattiryhma),
alue == "KOKO MAA",
!str_detect(ammattiryhma, "(?i)yhteensä")
) |>
mutate(
vuosi = as.integer(str_sub(kuukausi, 1, 4)),
kk = as.integer(str_sub(kuukausi, 6, 7)),
aika = make_date(vuosi, kk, 1),
ammatti_koodi = str_extract(ammattiryhma, "^\\d+"),
ammatti_nimi = str_trim(str_remove(ammattiryhma, "^\\d+\\s*")),
kohtaantosuhde = avoimet / tyottomat
) |>
filter(!is.na(ammatti_koodi))
df <- df_long
# -----------------------------------------------------------
# 4. Aggregoidaan 2-numerotasolle
# -----------------------------------------------------------
df_2nro <- df |>
mutate(isco2 = str_sub(ammatti_koodi, 1, 2)) |>
group_by(isco2, aika, vuosi) |>
summarise(
tyottomat = sum(tyottomat, na.rm = TRUE),
avoimet = sum(avoimet, na.rm = TRUE),
n_ammatteja = n(),
.groups = "drop"
) |>
mutate(kohtaantosuhde = avoimet / tyottomat)
# 2-numerotason nimet (suurimman ammatin nimi per ryhmä)
isco2_nimet <- df |>
filter(aika == max(aika)) |>
mutate(isco2 = str_sub(ammatti_koodi, 1, 2)) |>
group_by(isco2) |>
slice_max(n = 1, order_by = tyottomat, with_ties = FALSE) |>
ungroup() |>
select(isco2, isco2_nimi = ammatti_nimi) |>
distinct(isco2, .keep_all = TRUE)
df_2nro <- df_2nro |>
left_join(isco2_nimet, by = "isco2")
```
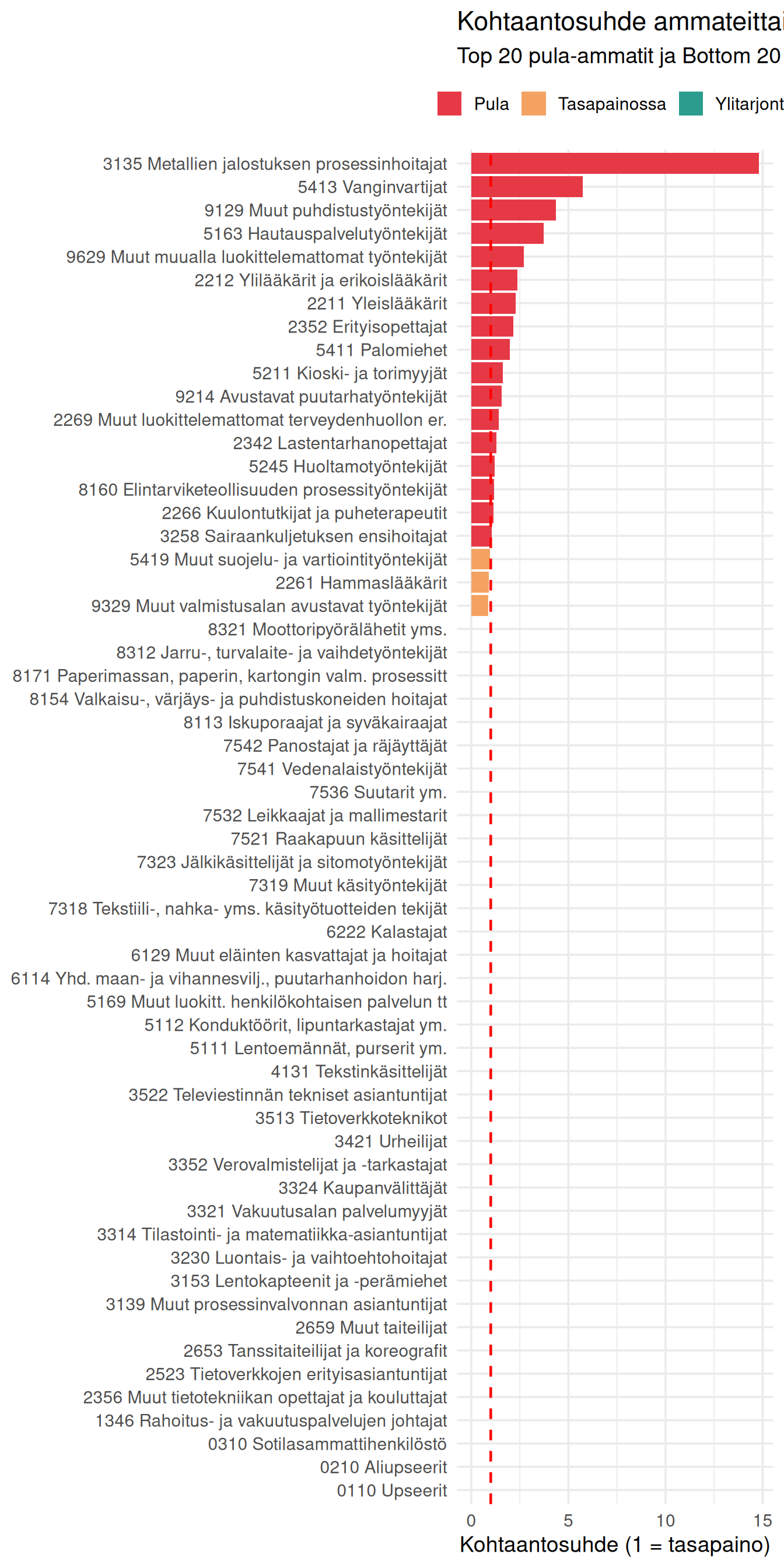
## Kohtaantosuhde ammattitasolla (4-numerotaso)
Tarkastellaan ensin kohtaantosuhdetta **yksittäisten ammattien** tasolla tuoreimmalla datalla. Käytämme 4-numeron ISCO-08-luokitusta, joka erottelee ammatit tarkimmin.
```{r}
#| label: fig-kohtaanto-4nro
#| fig-cap: "Kohtaantosuhde ammateittain (uusin kuukausi, 4-numerotaso). Punainen viiva = tasapaino."
#| fig-height: 14
df_uusin <- df |>
filter(
aika == max(aika),
tyottomat > 30, # poistetaan hyvin pienet ammattiryhmät
!is.na(kohtaantosuhde),
is.finite(kohtaantosuhde)
) |>
arrange(desc(kohtaantosuhde))
uusin_kk <- format(max(df_uusin$aika), "%m/%Y")
# Näytetään top ja bottom 20
top20 <- slice_max(df_uusin, kohtaantosuhde, n = 20)
bot20 <- slice_min(df_uusin, kohtaantosuhde, n = 20)
bind_rows(top20, bot20) |>
mutate(
label = paste0(ammatti_koodi, " ", ammatti_nimi),
label = fct_reorder(label, kohtaantosuhde),
tyyppi = case_when(
kohtaantosuhde > 1 ~ "Pula",
kohtaantosuhde > 0.5 ~ "Tasapainossa",
TRUE ~ "Ylitarjonta"
)
) |>
ggplot(aes(kohtaantosuhde, label, fill = tyyppi)) +
geom_col() +
geom_vline(
xintercept = 1,
colour = "red",
linetype = "dashed",
linewidth = 0.8
) +
scale_fill_manual(
values = c(
"Pula" = "#e63946",
"Tasapainossa" = "#f4a261",
"Ylitarjonta" = "#2a9d8f"
)
) +
labs(
title = paste0("Kohtaantosuhde ammateittain (", uusin_kk, ")"),
subtitle = "Top 20 pula-ammatit ja Bottom 20 ylitarjonta-ammatit",
x = "Kohtaantosuhde (1 = tasapaino)",
y = NULL,
fill = NULL
) +
theme(legend.position = "top")
```
Tämä on se kuva, joka puuttuu julkisesta keskustelusta.
Kun poliitikko sanoo "Suomessa on työvoimapula", hän tarkoittaa punaisia palkkeja. Mutta vihreitä palkkeja on todennäköisesti enemmän. Keskiarvo ei kerro tätä. Jakauma kertoo.
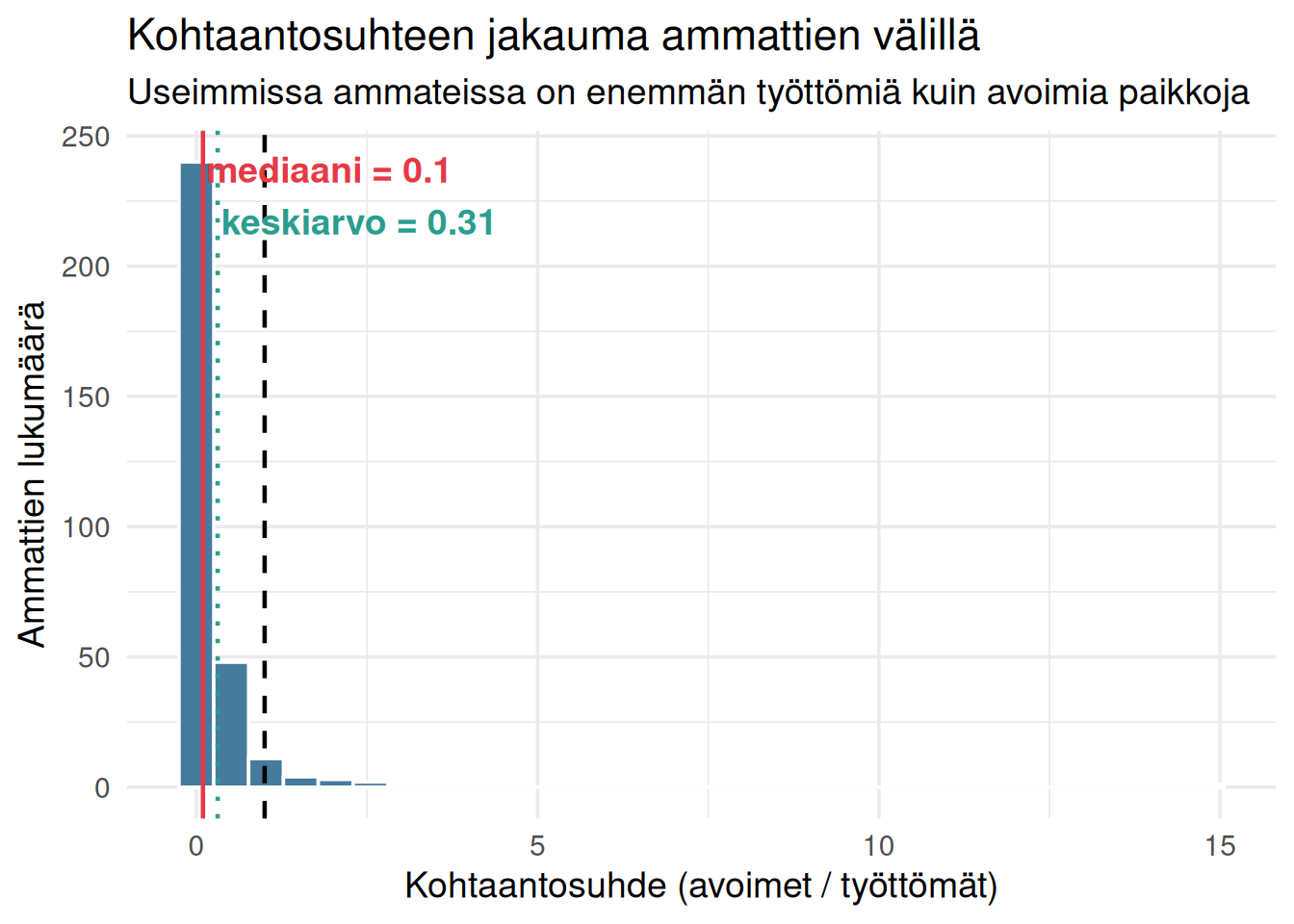
## Kohtaantosuhteen jakauma
Yksittäisten ammattien sijaan tarkastellaan kohtaantosuhteen **jakaumaa**. Jos jakauma on lähellä yhtä, työmarkkina kohtaa hyvin. Jos jakauma on laaja ja vinoutunut, kohtaanto on epätasainen.
```{r}
#| label: fig-kohtaanto-jakauma
#| fig-cap: "Kohtaantosuhteen jakauma ammattien välillä"
med_val <- median(df_uusin$kohtaantosuhde, na.rm = TRUE)
ka_val <- mean(df_uusin$kohtaantosuhde, na.rm = TRUE)
df_uusin |>
ggplot(aes(kohtaantosuhde)) +
geom_histogram(bins = 30, fill = "#457b9d", colour = "white") +
geom_vline(
xintercept = 1,
colour = "black",
linetype = "dashed",
linewidth = 0.8
) +
geom_vline(
xintercept = med_val,
colour = "#e63946",
linewidth = 0.8
) +
geom_vline(
xintercept = ka_val,
colour = "#2a9d8f",
linewidth = 0.8,
linetype = "dotted"
) +
annotate(
"text",
x = med_val + 0.05,
y = Inf,
vjust = 2,
hjust = 0,
label = paste0("mediaani = ", round(med_val, 2)),
colour = "#e63946",
fontface = "bold"
) +
annotate(
"text",
x = ka_val + 0.05,
y = Inf,
vjust = 4,
hjust = 0,
label = paste0("keskiarvo = ", round(ka_val, 2)),
colour = "#2a9d8f",
fontface = "bold"
) +
labs(
title = "Kohtaantosuhteen jakauma ammattien välillä",
subtitle = "Useimmissa ammateissa on enemmän työttömiä kuin avoimia paikkoja",
x = "Kohtaantosuhde (avoimet / työttömät)",
y = "Ammattien lukumäärä"
)
```
Jakaumasta nähdään todennäköisesti, että:
- mediaani on selvästi alle yhden
- jakauma on oikealle vinoutunut: muutama ammatti vetää keskiarvoa ylöspäin
- suurimmassa osassa ammatteja on ylitarjontaa
Tämä on tyypillinen esimerkki siitä, miksi keskiarvo johtaa harhaan. Muutama pula-ammatti nostaa keskiarvoa, mutta tyypillisessä ammatissa tilanne on päinvastainen.
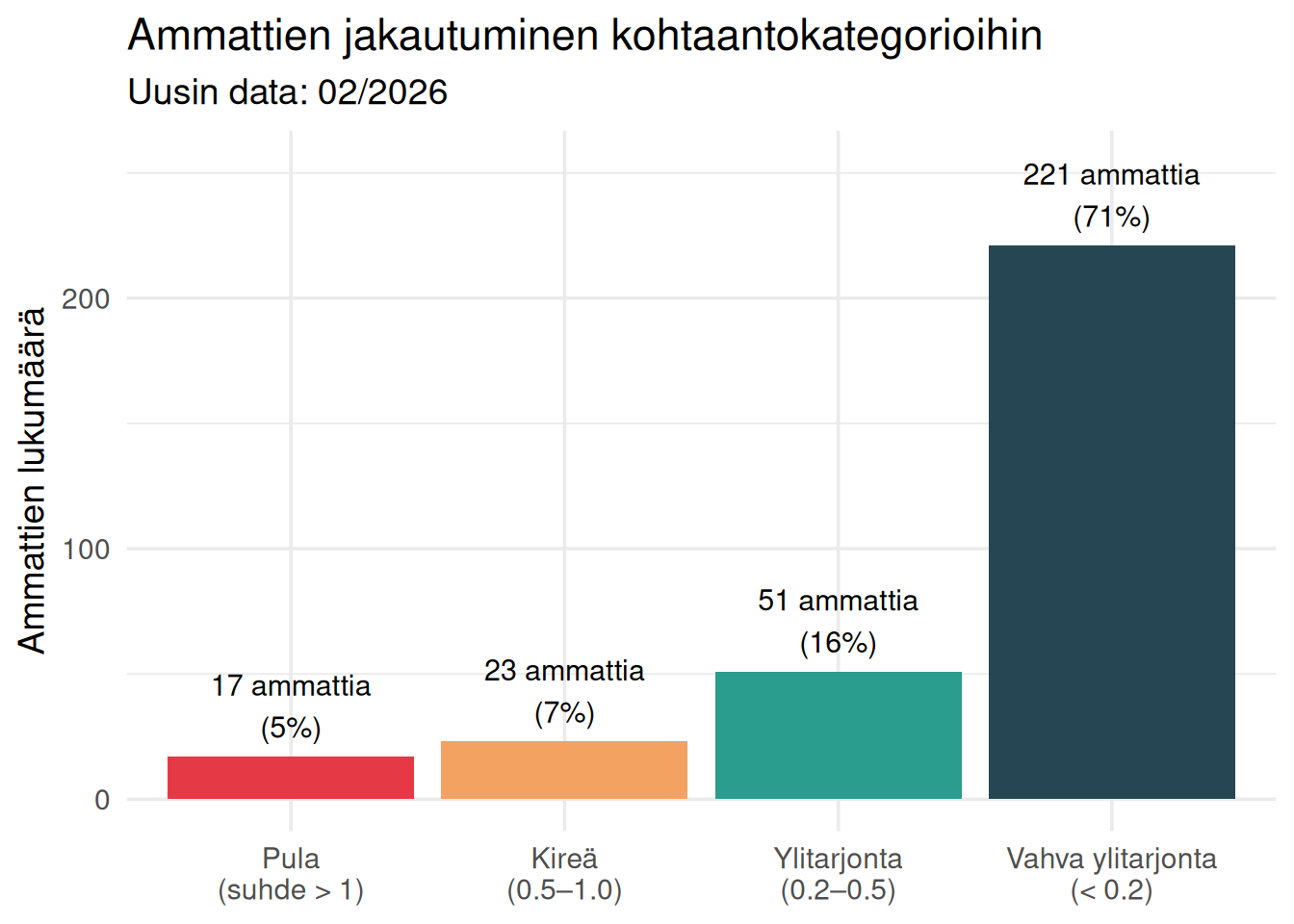
## Ammattien jakautuminen kategorioihin
Kuinka suuri osa ammateista on pula-ammatteja, kuinka suuri osa ylitarjonnassa?
```{r}
#| label: fig-kategoria-osuudet
#| fig-cap: "Ammattien jakautuminen kohtaantokategorioihin"
df_uusin |>
mutate(
tyyppi = case_when(
kohtaantosuhde > 1 ~ "Pula\n(suhde > 1)",
kohtaantosuhde > 0.5 ~ "Kireä\n(0.5–1.0)",
kohtaantosuhde > 0.2 ~ "Ylitarjonta\n(0.2–0.5)",
TRUE ~ "Vahva ylitarjonta\n(< 0.2)"
),
tyyppi = factor(tyyppi, levels = c(
"Pula\n(suhde > 1)",
"Kireä\n(0.5–1.0)",
"Ylitarjonta\n(0.2–0.5)",
"Vahva ylitarjonta\n(< 0.2)"
))
) |>
count(tyyppi) |>
mutate(
osuus = n / sum(n),
label = paste0(n, " ammattia\n(", percent(osuus, accuracy = 1), ")")
) |>
ggplot(aes(tyyppi, n, fill = tyyppi)) +
geom_col() +
geom_text(aes(label = label), vjust = -0.3, size = 4) +
scale_fill_manual(
values = c(
"Pula\n(suhde > 1)" = "#e63946",
"Kireä\n(0.5–1.0)" = "#f4a261",
"Ylitarjonta\n(0.2–0.5)" = "#2a9d8f",
"Vahva ylitarjonta\n(< 0.2)" = "#264653"
)
) +
labs(
title = "Ammattien jakautuminen kohtaantokategorioihin",
subtitle = paste0("Uusin data: ", uusin_kk),
x = NULL,
y = "Ammattien lukumäärä",
fill = NULL
) +
theme(legend.position = "none") +
expand_limits(y = max(table(cut(
df_uusin$kohtaantosuhde,
c(-Inf, 0.2, 0.5, 1, Inf)
))) * 1.15)
```
Tämä kuva tiivistää koko keskustelun yhteen kuvaan: suurin osa ammateista on ylitarjonnassa.
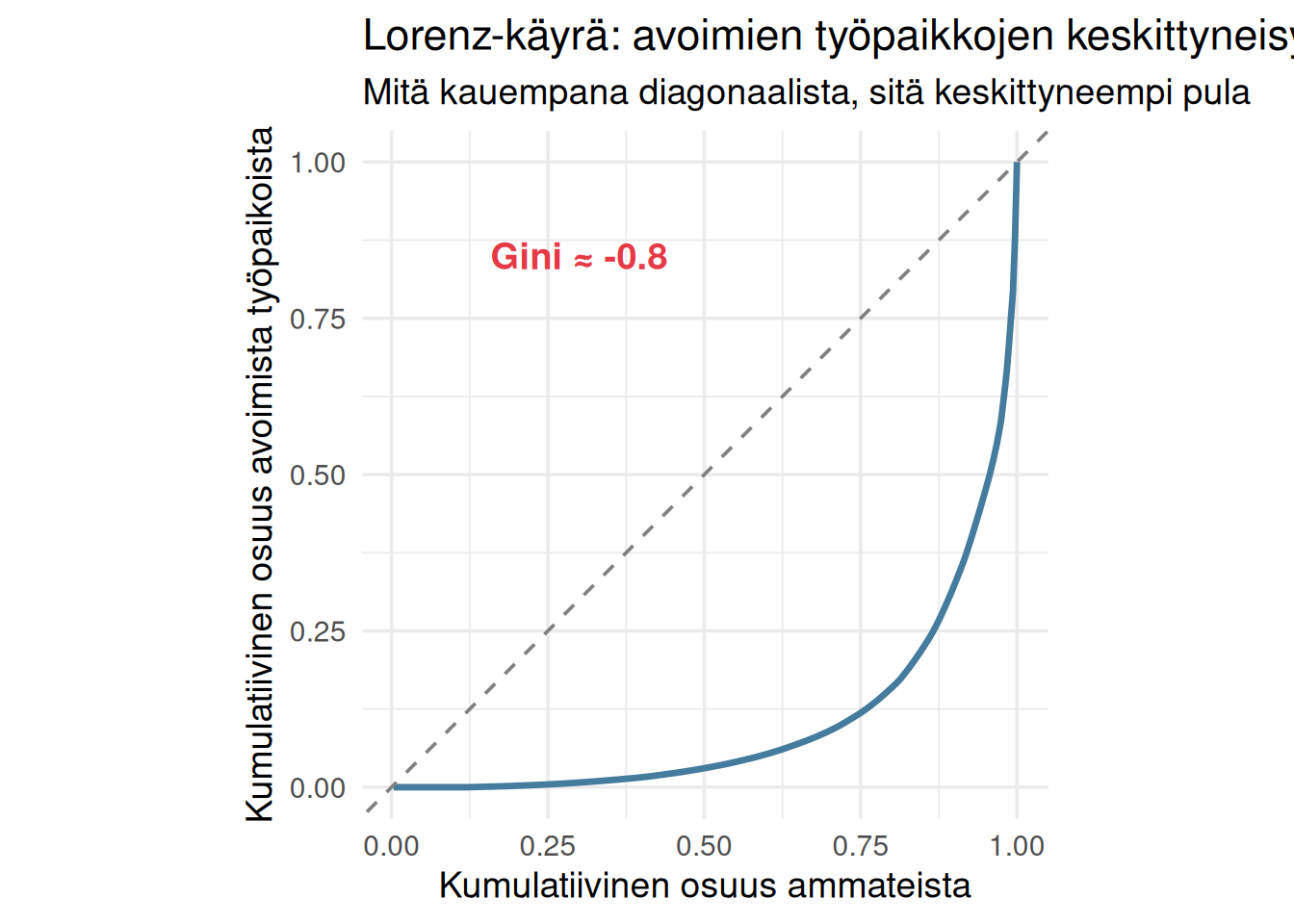
## Lorenz-käyrä: kuinka keskittynyttä pula on?
Jos työvoimapula olisi koko talouden ongelma, avoimien työpaikkojen pitäisi jakautua tasaisesti ammattien välille. Jos se taas on keskittynyt pieneen joukkoon ammatteja, Lorenz-käyrä kaareutuu kauas diagonaalista.
```{r}
#| label: fig-lorenz
#| fig-cap: "Lorenz-käyrä: avoimien työpaikkojen kumulatiivinen jakautuminen ammattien välillä"
lorenz_data <- df_uusin |>
arrange(avoimet) |>
mutate(
kum_ammatit = row_number() / n(),
kum_avoimet = cumsum(avoimet) / sum(avoimet)
)
# Gini-kerroin (trapezoidi-approksimaatio)
gini <- lorenz_data |>
summarise(
gini = 1 - 2 * sum(
(kum_avoimet - lag(kum_avoimet, default = 0)) *
(kum_ammatit + lag(kum_ammatit, default = 0)) / 2
)
) |>
pull(gini)
ggplot(lorenz_data, aes(kum_ammatit, kum_avoimet)) +
geom_line(linewidth = 1.2, colour = "#457b9d") +
geom_abline(
slope = 1,
intercept = 0,
linetype = "dashed",
colour = "grey50"
) +
annotate(
"text",
x = 0.3,
y = 0.85,
label = paste0("Gini ≈ ", round(gini, 2)),
size = 5,
fontface = "bold",
colour = "#e63946"
) +
labs(
title = "Lorenz-käyrä: avoimien työpaikkojen keskittyneisyys",
subtitle = "Mitä kauempana diagonaalista, sitä keskittyneempi pula",
x = "Kumulatiivinen osuus ammateista",
y = "Kumulatiivinen osuus avoimista työpaikoista"
) +
coord_equal()
```
Gini-kerroin kertoo, kuinka epätasaisesti avoimet työpaikat jakautuvat ammattien välillä. Jos Gini on lähellä nollaa, kaikissa ammateissa on suunnilleen yhtä paljon avoimia paikkoja. Jos Gini on lähellä yhtä, pula keskittyy muutamaan ammattiin.
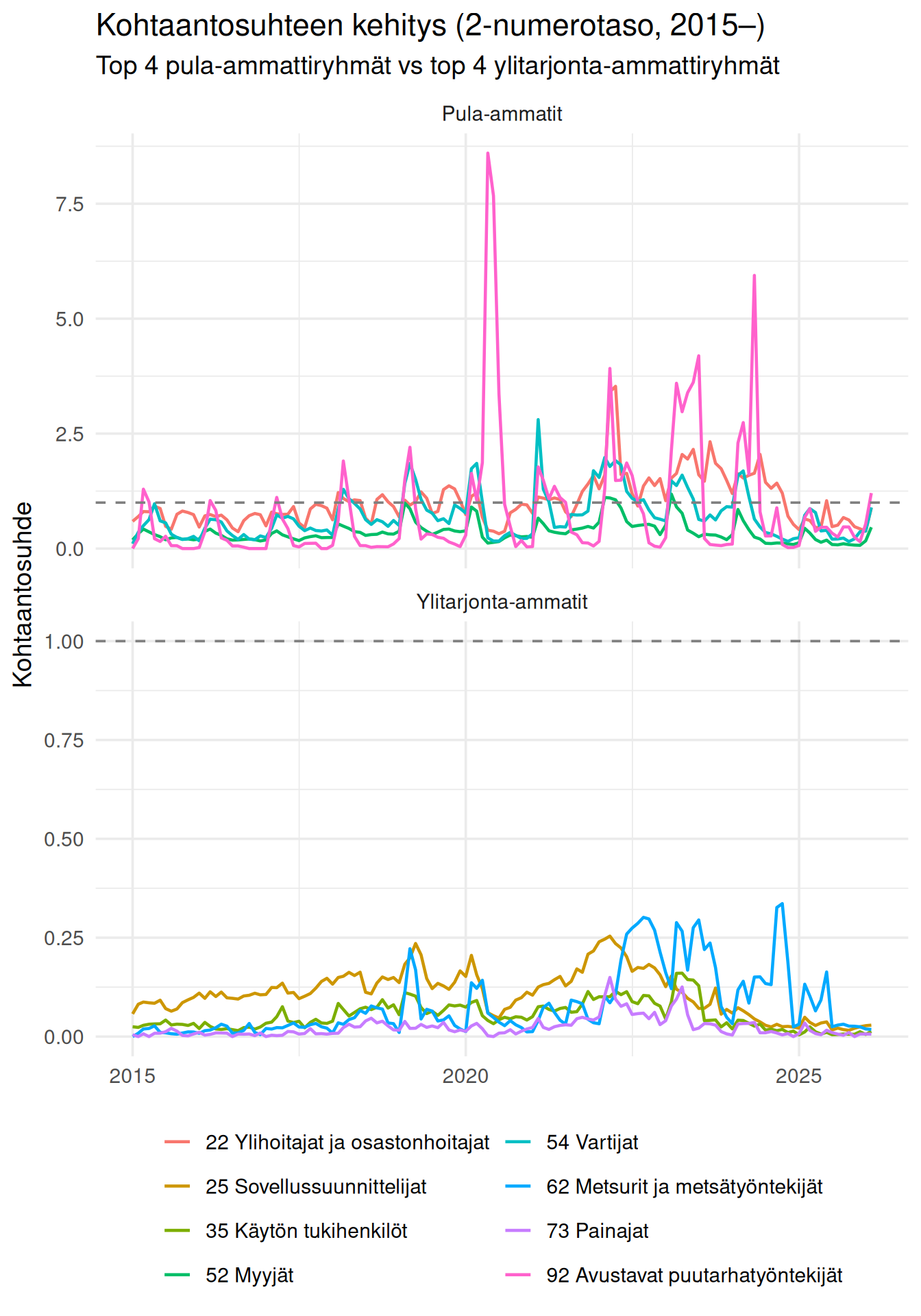
## Kohtaantosuhteen kehitys ajassa
Onko tilanne muuttunut? Tarkastellaan kohtaantosuhdetta muutamassa ammattiryhmässä ajan yli. Käytetään ISCO-08 2-numerotasoa, jotta kuvaajat ovat luettavia.
```{r}
#| label: fig-aikasarja
#| fig-cap: "Kohtaantosuhteen kehitys valituissa ammattiryhmissä (2-numerotaso)"
#| fig-height: 10
# Valitaan esimerkkejä: suurimmat ja pienimmät kohtaantosuhteet 2-numerotasolla
df_2nro_uusin <- df_2nro |>
filter(
aika == max(aika),
tyottomat > 100
)
top_isco2 <- df_2nro_uusin |>
slice_max(kohtaantosuhde, n = 4) |>
pull(isco2)
bot_isco2 <- df_2nro_uusin |>
slice_min(kohtaantosuhde, n = 4) |>
pull(isco2)
df_2nro |>
filter(
isco2 %in% c(top_isco2, bot_isco2),
vuosi >= 2015
) |>
mutate(
tyyppi = if_else(
isco2 %in% top_isco2,
"Pula-ammatit",
"Ylitarjonta-ammatit"
),
label = paste0(isco2, " ", isco2_nimi)
) |>
ggplot(aes(aika, kohtaantosuhde, colour = label)) +
geom_line(linewidth = 0.8) +
geom_hline(yintercept = 1, linetype = "dashed", colour = "grey50") +
facet_wrap(~tyyppi, scales = "free_y", ncol = 1) +
labs(
title = "Kohtaantosuhteen kehitys (2-numerotaso, 2015–)",
subtitle = "Top 4 pula-ammattiryhmät vs top 4 ylitarjonta-ammattiryhmät",
x = NULL,
y = "Kohtaantosuhde",
colour = NULL
) +
theme(legend.position = "bottom") +
guides(colour = guide_legend(ncol = 2))
```
Kuvaajasta nähdään, että kohtaantosuhde vaihtelee voimakkaasti myös ajan suhteen. Pula-ammateissa suhde nousi jyrkästi vuosina 2021–2022 ja on sen jälkeen hieman laskenut. Ylitarjonta-ammateissa suhde on pysynyt vakaasti alle yhden.
Tämä tarkoittaa, että kohtaanto-ongelma on sekä **ammattikohtainen** että **suhdanneherkkä**.
## Monte Carlo -simulaatio: mitä jos kohtaanto paranisi?
Entä jos kohtaanto paranisi? Simuloidaan tilannetta, jossa osa ylitarjonta-ammattien työttömistä siirtyisi pula-ammatteihin.
```{r}
#| label: fig-simulaatio
#| fig-cap: "Simulaatio: työttömyyden vähenemä, jos kohtaanto paranee"
set.seed(42)
n_sim <- 5000
# Lasketaan nykytilanne
pula_ammatit <- df_uusin |>
filter(kohtaantosuhde > 1)
ylitarjonta_ammatit <- df_uusin |>
filter(kohtaantosuhde <= 1)
tayttamaton_kysynta <- sum(
pmax(pula_ammatit$avoimet - pula_ammatit$tyottomat, 0),
na.rm = TRUE
)
tyottomia_ylitarjonnassa <- sum(
pmax(ylitarjonta_ammatit$tyottomat - ylitarjonta_ammatit$avoimet, 0),
na.rm = TRUE
)
kokonais_tyottomat <- sum(df_uusin$tyottomat, na.rm = TRUE)
# Simuloidaan: kuinka moni voisi siirtyä, jos siirtymätodennäköisyys vaihtelee?
simuloi <- function(siirtyma_tn) {
siirtyjat <- rbinom(
n_sim,
size = round(tyottomia_ylitarjonnassa),
prob = siirtyma_tn
)
# ei voi siirtyä enempää kuin on paikkoja
pmin(siirtyjat, tayttamaton_kysynta)
}
sim_results <- tibble(
siirtyma_tn = rep(c(0.05, 0.10, 0.15, 0.20), each = n_sim),
siirtyjat = c(
simuloi(0.05),
simuloi(0.10),
simuloi(0.15),
simuloi(0.20)
)
) |>
mutate(
tyottomyyden_vahenema_pct = siirtyjat / kokonais_tyottomat * 100,
label = paste0(siirtyma_tn * 100, " % siirtyy")
)
ggplot(sim_results, aes(tyottomyyden_vahenema_pct, fill = label)) +
geom_histogram(bins = 40, alpha = 0.7, colour = "white") +
facet_wrap(~label, ncol = 2) +
labs(
title = "Monte Carlo -simulaatio: kohtaannon paranemisen vaikutus",
subtitle = paste0(
"Simuloitu ", format(n_sim, big.mark = " "), " kertaa per skenaario\n",
"Täyttämätön kysyntä: ", format(tayttamaton_kysynta, big.mark = " "),
" paikkaa | Ylitarjonnassa: ",
format(tyottomia_ylitarjonnassa, big.mark = " "), " työtöntä"
),
x = "Työttömyyden vähenemä (%)",
y = "Simulaatioiden lukumäärä",
fill = NULL
) +
theme(legend.position = "none")
```
Simulaatio osoittaa, että vaikka kohtaanto paranisi merkittävästi, vaikutus kokonaistyöttömyyteen on rajallinen. Tämä johtuu siitä, että täyttämätön kysyntä on pieni suhteessa kokonaistyöttömyyteen.
Toisin sanoen: **kohtaanto-ongelman ratkaiseminen ei ratkaise Suomen työttömyysongelmaa**, koska suurin osa työttömyydestä ei johdu kohtaannosta vaan kysynnän puutteesta.
## Yhteenveto
Tässä osassa osoitimme ammattitason datalla, että:
1. **Työvoimapula keskittyy pieneen joukkoon ammatteja.** Suurimmassa osassa ammattiryhmiä työttömiä on enemmän kuin avoimia paikkoja.
2. **Kohtaantosuhteen jakauma on voimakkaasti oikealle vinoutunut.** Mediaani on selvästi alle yhden. Muutama pula-ammatti vetää keskiarvoa ylöspäin — mutta tyypillisessä ammatissa on ylitarjontaa.
3. **Lorenz-käyrä vahvistaa: avoimet työpaikat keskittyvät.** Korkea Gini-kerroin tarkoittaa, ettei kyse ole tasaisesta ongelmasta.
4. **Monte Carlo -simulaatio osoittaa: kohtaannon paraneminen ei yksin riitä.** Vaikka kaikki pula-ammattien paikat täytettäisiin, kokonaistyöttömyys laskisi vain vähän.
Julkinen keskustelu kärsii samasta perusvirheestä kuin makrotalouden yksinkertaistukset yleensä: yritetään kuvata monimutkaista ilmiötä yhdellä luvulla. Mutta
> maailma on jakauma
ja myös kohtaanto-ongelma on jakauma. Politiikka, joka perustuu yhteen lukuun, ei voi ratkaista jakaumaongelmaa.
## Mitä seuraavaksi?
Seuraavassa osassa tarkastelemme kohtaanto-ongelmaa **alueellisesti**: onko työvoimapula Helsingin ongelma vai koko Suomen?
---
Kaipaatko analyysiä tai onko sinulla projekti, jonka haluat toteuttaa? Ota yhteyttä kristian.vepsalainen@proton.me . Olen käytettävissäsi.