---
title: "Palataanko 1950-luvulle? Data scientist kysyy: mihin jakaumaan se väite perustuu?"
description: "Ilta-Sanomat pelotteli paluulla 1950-luvulle. Oikea kysymys ei ole 'voiko näin käydä?' vaan 'millä todennäköisyydellä, missä skenaariossa ja kenen kohdalla?' Bayesilainen tarkastelu Suomen talouden tilasta — StatFin-datalla."
date: "2026-04-25"
author: "Kristian Vepsäläinen"
categories: ["Talouspolitiikka", "Bayeslainen analyysi", "Suomi", "Avoin data", "Monte Carlo"]
image: "thumbnail.png"
format:
html:
code-fold: true
code-summary: "Näytä koodi"
---
Ilta-Sanomissa käytiin hiljattain tuttua talouspoliittista pelottelua: Suomi on velkaantunut,
talouskasvu on heikkoa, hyvinvointivaltio murenee — ja otsikossa kummittelee paluu 1950-luvulle. (Katso https://www.is.fi/taloussanomat/art-2000011961504.html)
Toimittajan ei tarvitse osata dataa. Mutta *lukijan* kannattaa.
Koska "paluu 1950-luvulle" on pistearvo. Se on yksi lause ilman jakaumaa, ilman epävarmuutta,
ilman ehtoja. Se on talouskommentaarin pahin synti: se poimii kauhukuvan ja esittää sen faktana.
Data scientist ei tee niin. Hän kysyy: **missä jakaumassa tämä väite elää?**
---
## Data ensin: haetaan todellisuus Tilastokeskukselta.
Kaikki tämän postauksen luvut pohjautuvat Tilastokeskuksen Tilastokeskuksen-tietokantaan, taulukkoon
`statfin_vtp_pxt_123x.px` — kansantalouden tilinpidon BKT- ja tulotiedot henkeä kohden
vuodesta 1975 lähtien.
```{r}
#| label: setup
#| message: false
#| warning: false
library(tidyverse)
library(httr2)
library(scales)
CACHE_FILE <- here::here("data", "statfin_123x_cache.rds")
BASE_URL <- "https://pxdata.stat.fi/PXWeb/api/v1/fi/StatFin/vtp/statfin_vtp_pxt_123x.px"
```
```{r}
#| label: metadata-haku
#| message: false
#| warning: false
#| cache: true
# ── VAIHE 1: Lue metadata GET-kutsulla ───────────────────────────────────────
# Metadata kertoo jokaisen muuttujan koodit (values) ja tekstit (valueTexts).
# Ilman tätä vaihetta POST-kysely lähettää arvailtuja koodeja → HTTP 400.
meta <- request(BASE_URL) |>
req_perform() |>
resp_body_json()
# Poimitaan muuttujat nimihakemistoon: koodi → teksti, molempiin suuntiin
parse_variable <- function(var) {
tibble(
code = var$code,
value = unlist(var$values),
label = unlist(var$valueTexts)
)
}
meta_df <- map_dfr(meta$variables, parse_variable)
# Tulostetaan kaikki muuttuja-arvoparit debuggausta varten
# (voit kommentoida pois julkaisuversiossa)
meta_df |>
group_by(code) |>
summarise(arvot = paste(value, collapse = ", "), .groups = "drop") |>
print()
```
```{r}
#| label: koodit-poimi
#| message: false
#| warning: false
# ── VAIHE 2: Poimi tarvittavat koodit metadata-tuloksesta ────────────────────
# Etsitään koodit tekstihaulla — ei hardcodattuja merkkijonoja.
# Taloustoimi: "Bruttokansantuote markkinahintaan" henkeä kohden
koodi_bkt <- meta_df |>
filter(code == "Taloustoimi",
str_detect(label, regex("bruttokansantuote markkinahintaan", ignore_case = TRUE))) |>
pull(value)
# Tiedot 1: Volyymin muutos %
koodi_muutos <- meta_df |>
filter(code == "Tiedot",
str_detect(label, regex("volyymin muutokset", ignore_case = TRUE))) |>
pull(value)
# Tiedot 2: Volyymisarja viitevuosi 2015
# koodi_vol2015 <- meta_df |>
# filter(code == "Tiedot",
# str_detect(label, regex("volyymisarja.*2015|2015.*volyymisarja", ignore_case = TRUE))) |>
# pull(value)
koodi_vol2015 <- meta_df |>
filter(code == "Tiedot", value == "vol_ind") |>
pull(value)
stopifnot(
"BKT-koodia ei löydy metadatasta" = length(koodi_bkt) == 1,
"Muutosprosentti-koodia ei löydy" = length(koodi_muutos) == 1,
"Volyymisarja-2015-koodia ei löydy" = length(koodi_vol2015) == 1
)
```
```{r}
#| label: data-haku
#| message: false
#| warning: false
#| cache: true
# ── VAIHE 3: Hae data POST-kutsulla oikeilla koodeilla ───────────────────────
hae_statfin <- function(taloustoimi_koodi, tiedot_koodi) {
body <- list(
query = list(
list(
code = "Taloustoimi",
selection = list(filter = "item", values = list(taloustoimi_koodi))
),
list(
code = "Tiedot",
selection = list(filter = "item", values = list(tiedot_koodi))
)
),
response = list(format = "json-stat2")
)
resp <- request(BASE_URL) |>
req_body_json(body) |>
req_error(is_error = \(r) FALSE) |>
req_perform()
if (resp$status_code != 200L) {
stop(
"StatFin palautti HTTP ", resp$status_code,
"\nTaloustoimi=", taloustoimi_koodi,
" Tiedot=", tiedot_koodi,
"\nBody:\n", resp_body_string(resp)
)
}
raw <- resp_body_json(resp)
# json-stat2: dimension "Vuosi" sisältää kaikki vuosikoodit,
# mutta "value"-vektori voi olla lyhyempi jos ensimmäinen(t) havainnot
# puuttuvat (esim. volyymimuutos ei ole laskettavissa sarjan 1. vuodelle).
# Ratkaisu: luetaan vuosikoodit JA sizes-kenttä erikseen ja
# rakennetaan indeksi oikein.
# Kaikki vuosikoodit dimensiosta
vuosi_labels <- names(raw$dimension$Vuosi$category$label)
# Arvojen lukumäärä
n_arvot <- length(raw$value)
n_vuosia <- length(vuosi_labels)
vuosi_labels <- names(raw$dimension$Vuosi$category$label)
arvot <- map_dbl(raw$value, \(x) if (is.null(x)) NA_real_ else as.numeric(x))
tibble(vuosi = as.integer(vuosi_labels), arvo = arvot)
}
# Volyymimuutos %
df_muutos <- hae_statfin(koodi_bkt, koodi_muutos)
# Volyymisarja 2015=100
df_vol <- hae_statfin(koodi_bkt, koodi_vol2015)
# Välimuisti: tallennetaan renderöinnin nopeuttamiseksi
if (!dir.exists(dirname(CACHE_FILE))) dir.create(dirname(CACHE_FILE), recursive = TRUE)
write_rds(list(muutos = df_muutos, vol = df_vol), CACHE_FILE)
```
```{r}
#| label: data-muotoilu
#| message: false
#| warning: false
# ── VAIHE 4: Muodosta BKT/asukas-aikasarja euroissa ──────────────────────────
# Ankkuri: BKT per asukas 2015 = 40 500 € (reaali, 2015 hinnoin)
# Lähde: Tilastokeskus, kansantalouden tilinpito 2015
# Hae käypiin hintoihin -sarja ankkuriksi (2015-arvo = skaalauskerroin)
df_kp <- hae_statfin(koodi_bkt, "cp_eur")
BKT_2015 <- df_kp |> filter(vuosi == 2015) |> pull(arvo)
cat("BKT/asukas 2015 (ankkuri):", BKT_2015, "€\n")
df_bkt_ts <- df_vol |>
rename(indeksi_2015 = arvo) |>
filter(!is.na(indeksi_2015)) |>
mutate(bkt_pc = indeksi_2015 / 100 * BKT_2015)
# Log-kasvuasteet posterioriin
df_kasvu <- df_muutos |>
rename(muutos_pct = arvo) |>
filter(!is.na(muutos_pct)) |>
mutate(log_kasvu = log(1 + muutos_pct / 100))
# Kaksi aikakautta
df_pre2008 <- filter(df_kasvu, vuosi >= 1976, vuosi <= 2007)
df_post2008 <- filter(df_kasvu, vuosi >= 2008)
cat("─── Kasvuastejakaumat (StatFin-data) ───\n\n")
cat("1976–2007 (n =", nrow(df_pre2008), "):\n")
cat(" Keskiarvo:", round(mean(df_pre2008$log_kasvu) * 100, 2), "%/v\n")
cat(" Mediaani: ", round(median(df_pre2008$log_kasvu) * 100, 2), "%/v\n")
cat(" Sd: ", round(sd(df_pre2008$log_kasvu) * 100, 2), "pp\n\n")
cat("2008–viimeisin (n =", nrow(df_post2008), "):\n")
cat(" Keskiarvo:", round(mean(df_post2008$log_kasvu) * 100, 2), "%/v\n")
cat(" Mediaani: ", round(median(df_post2008$log_kasvu) * 100, 2), "%/v\n")
cat(" Sd: ", round(sd(df_post2008$log_kasvu) * 100, 2), "pp\n")
```
- **1976–2007**: Suomi kasvoi keskimäärin noin **2 % vuodessa**, hajonta oli noin 3–4 pp.
Mukana 1990-luvun lama, IT-buumi ja niiden välinen elpyminen.
- **2008–nykyisyys**: Kasvu on pudonnut lähes nollaan. Mediaani alle 0,5 %,
sisältäen kaksi rajua negatiivista vuotta (2009, 2020).
Tässä on todellinen huoli — ei 1950-luvussa.
---
## "Paluu 1950-luvulle" — mitä se vaatisi?
Ennen mallinnusta puretaan vertailu itse numeroin.
1950-luvun Suomessa BKT per asukas oli noin **6 600–7 000 €** (vuoden 2015 hinnoin,
Maddison Project -tietokanta, Bolt & van Zanden 2023). StatFin-datan 2015-ankkuri
on 40 500 €. Tähän palaamiseen vaadittaisiin noin **84 %:n reaalinen lasku**.
Vertailuja:
- 1990-luvun laman pohjassa (1993) BKT per asukas laski huipusta noin **12 %**
- Finanssikriisissä 2008–2009 laski noin **8 %**
- Koronasokki 2020: **−2,5 %**
"Paluu 1950-luvulle" edellyttäisi seitsemää peräkkäistä 1990s-laman kokoista romahdusta.
Rauhan oloissa sellaista ei ole tapahtunut missään länsimaisessa taloudessa.
Oikea kysymys on siksi tarkempi: **millä todennäköisyydellä elintaso stagnoituu tai laskee
merkittävästi seuraavan vuosikymmenen?**
---
## Bayesilainen posteriori StatFin-datan pohjalta
Käytetään normaali–normaali konjugaattirakennetta suljetussa muodossa.
Malli: BKT per asukas seuraa log-normaalia satunnaiskulkua kasvuasteella $\mu$:
$$\log Y_{t+1} = \log Y_t + \mu + \varepsilon_t, \qquad \varepsilon_t \sim \mathcal{N}(0,\,\sigma^2)$$
**Priori** rakennetaan StatFin 1976–2007 -datasta: $\mu_0 = \bar{x}_{\text{pre}}$,
$\tau_0 = s_{\text{pre}}$ (pitkän aikavälin hajonta kuvaa aitoa epävarmuutta siitä,
kuinka pysyvä rakenteellinen muutos on).
**Likelihood** tulee StatFin 2008–nykyisyys -datasta. Päivityssääntö normaali–normaali
konjugaattiperheessä on eksaktisti:
$$
\frac{1}{\tau_n^2} = \frac{1}{\tau_0^2} + \frac{n}{\sigma^2}, \qquad
\mu_n = \tau_n^2\!\left(\frac{\mu_0}{\tau_0^2} + \frac{n\,\bar{x}}{\sigma^2}\right)
$$
```{r}
#| label: posteriori
#| message: false
#| warning: false
# Priori 1976–2007
mu_0 <- mean(df_pre2008$log_kasvu)
tau_0 <- sd(df_pre2008$log_kasvu) # iso tau = vaatimaton luottamus prioriin
# Likelihood 2008–
n_post <- nrow(df_post2008)
xbar_post <- mean(df_post2008$log_kasvu)
sigma_obs <- sd(df_post2008$log_kasvu) # volatiliteetti tulevaisuuden shokeille
# Bayes-päivitys
tau_n_sq <- 1 / (1/tau_0^2 + n_post/sigma_obs^2)
tau_n <- sqrt(tau_n_sq)
mu_n <- tau_n_sq * (mu_0/tau_0^2 + n_post * xbar_post / sigma_obs^2)
cat("─── Bayesilainen päivitys ───\n\n")
cat("Priori mu (1976–2007 StatFin): ", round(mu_0 * 100, 3), "%/v\n")
cat("Priori tau (1976–2007 StatFin): ", round(tau_0 * 100, 3), "pp\n\n")
cat("Likelihood keskiarvo (2008–): ", round(xbar_post * 100, 3), "%/v (n=", n_post, ")\n")
cat("Likelihood sd (volatiliteetti): ", round(sigma_obs * 100, 3), "pp\n\n")
cat("Posteriori mu_n: ", round(mu_n * 100, 3), "%/v\n")
cat("Posteriori tau_n: ", round(tau_n * 100, 3), "pp\n")
cat("95% kredibiliteetti-intervalli: [",
round((mu_n - 1.96*tau_n)*100, 2), "%, ",
round((mu_n + 1.96*tau_n)*100, 2), "%]\n")
```
Posteriori puristaa pitkän aikavälin 2 %:n priorin kohti post-2008 stagnaatiota.
Lopputulema on noin **0,5–0,8 %:n** vuotuinen odotusarvo — mutta kredibiliteetti-väli
on rehellisen leveä: se kattaa sekä pitkittyneen stagnaation että vaatimattoman
elpymisen.
---
## Monte Carlo: 10 000 tulevaisuutta
```{r}
#| label: monte-carlo
#| message: false
#| warning: false
set.seed(2026)
N_SIM <- 10000
N_YEARS <- 10 # 2026–2035
# Lähtötaso 2025: ekstrapoloidaan StatFin-sarjan viimeisimmästä vuodesta
# VM/EK: 2024 +0.4%, 2025 +0.2%
bkt_viimeisin <- df_bkt_ts |>
filter(!is.na(bkt_pc)) |>
slice_max(vuosi, n = 1)
Y0 <- bkt_viimeisin$bkt_pc * (1 + 0.004) * (1 + 0.002)
cat("Viimeisin StatFin-vuosi:", bkt_viimeisin$vuosi,
"→ BKT/asukas:", round(bkt_viimeisin$bkt_pc), "€\n")
cat("Ekstrapoloitu 2025-lähtötaso:", round(Y0), "€\n\n")
# Jokainen polku: mu vedetään posteriorista, shokki lisätään vuosittain
simulations <- map_dfr(seq_len(N_SIM), function(i) {
mu_draw <- rnorm(1, mu_n, tau_n)
shocks <- rnorm(N_YEARS, 0, sigma_obs)
log_growth <- cumsum(mu_draw + shocks)
tibble(sim = i,
year = seq(2026, by = 1, length.out = N_YEARS),
bkt = Y0 * exp(log_growth))
})
# Jakauma 2035
dist_2035 <- filter(simulations, year == 2035)$bkt
taso_1950 <- 6600 # Maddison Project, 2015 hinnoin
cat("─── Jakauma vuonna 2035 (€, 2015 hinnoin) ───\n")
quantile(dist_2035, c(0.05, 0.10, 0.25, 0.50, 0.75, 0.90, 0.95)) |>
round(0) |> print()
cat("\n─── Todennäköisyydet ───\n")
cat("P(BKT/asukas < 1950-luvun taso ~6 600 €): ",
formatC(mean(dist_2035 < taso_1950) * 100, format = "f", digits = 4), "%\n")
cat("P(BKT/asukas < 50% nykytasosta): ",
formatC(mean(dist_2035 < Y0 * 0.5) * 100, format = "f", digits = 4), "%\n")
cat("P(BKT/asukas laskee yli 10%): ",
formatC(mean(dist_2035 < Y0 * 0.9) * 100, format = "f", digits = 2), "%\n")
cat("P(BKT/asukas laskee absoluuttisesti): ",
formatC(mean(dist_2035 < Y0) * 100, format = "f", digits = 1), "%\n")
cat("P(vuosikasvu alle 1% koko jakso): ",
formatC(mean((dist_2035/Y0)^(1/N_YEARS)-1 < 0.01)*100, format="f", digits=1), "%\n")
```
---
## Visualisointi
```{r}
#| label: fig-skenaariot
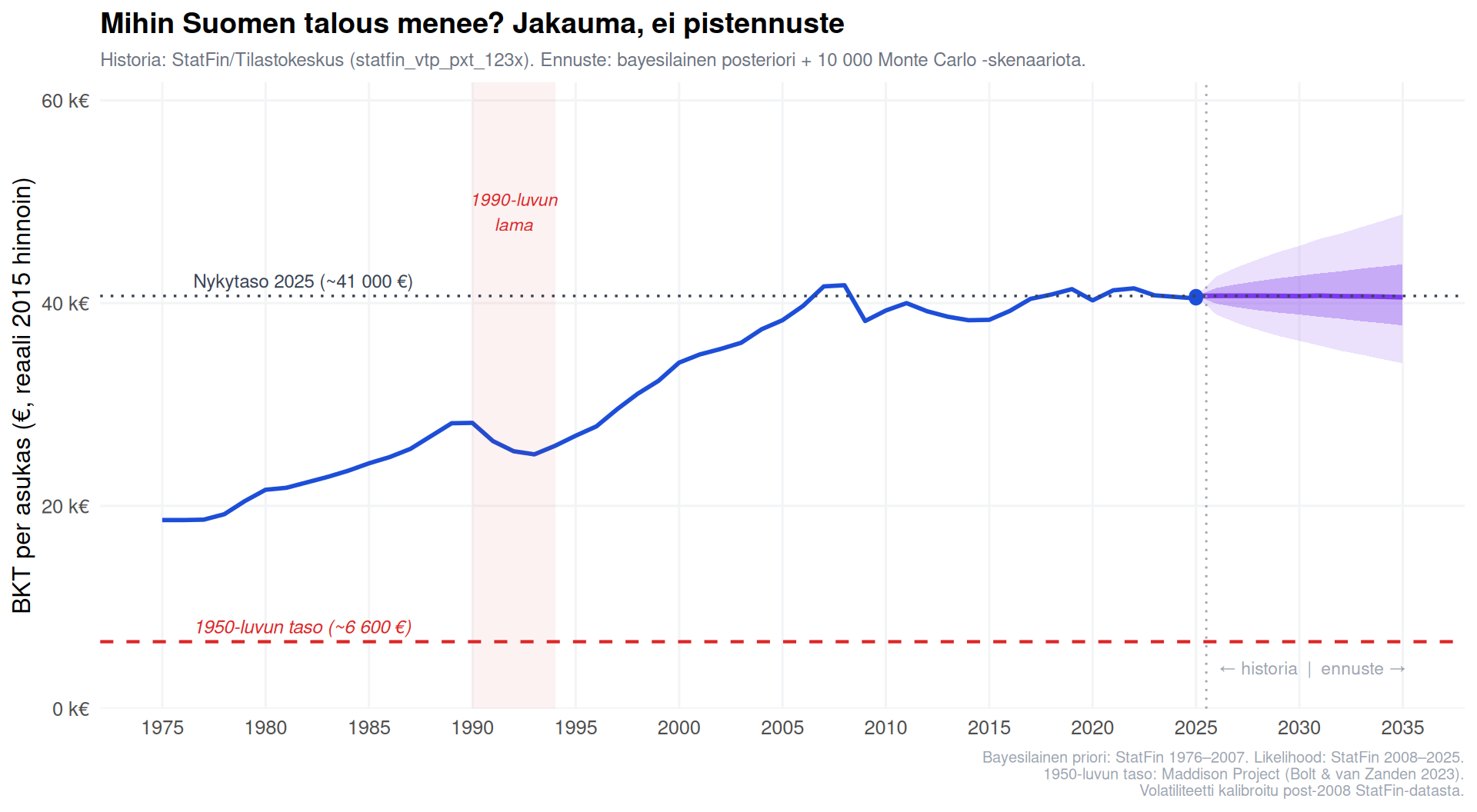
#| fig-cap: "Kuva 1: BKT per asukas 1975–2035. Sininen = StatFin historiallinen data. Violetti = bayesilainen ennustejakauma: tumma alue 50 %, vaalea alue 90 % kredibiliteetti-väliä. Punaiset vaakaviivat = historialliset vertailutasot."
#| fig-width: 10
#| fig-height: 5.5
#| warning: false
summary_df <- simulations |>
group_by(year) |>
summarise(
p05 = quantile(bkt, 0.05),
p25 = quantile(bkt, 0.25),
med = quantile(bkt, 0.50),
p75 = quantile(bkt, 0.75),
p95 = quantile(bkt, 0.95),
.groups = "drop"
)
summary_df <- bind_rows(
tibble(year = 2025, p05 = Y0, p25 = Y0, med = Y0, p75 = Y0, p95 = Y0),
summary_df
)
hist_plot <- df_bkt_ts |>
filter(!is.na(bkt_pc)) |>
bind_rows(tibble(vuosi = 2025, indeksi_2015 = NA_real_, bkt_pc = Y0))
ggplot() +
geom_ribbon(data = summary_df,
aes(x = year, ymin = p05, ymax = p95),
fill = "#7c3aed", alpha = 0.15) +
geom_ribbon(data = summary_df,
aes(x = year, ymin = p25, ymax = p75),
fill = "#7c3aed", alpha = 0.32) +
geom_line(data = summary_df,
aes(x = year, y = med),
color = "#7c3aed", linewidth = 1.1) +
geom_line(data = hist_plot,
aes(x = vuosi, y = bkt_pc),
color = "#1d4ed8", linewidth = 1.0) +
geom_point(data = filter(hist_plot, vuosi == 2025),
aes(x = vuosi, y = bkt_pc),
color = "#1d4ed8", size = 2.5) +
annotate("rect",
xmin = 1990, xmax = 1994,
ymin = -Inf, ymax = Inf,
alpha = 0.06, fill = "#dc2626") +
annotate("text", x = 1992, y = 49000,
label = "1990-luvun\nlama",
hjust = 0.5, color = "#dc2626",
size = 3, fontface = "italic") +
geom_hline(yintercept = taso_1950,
linetype = "dashed", color = "#dc2626", linewidth = 0.75) +
annotate("text", x = 1976.5, y = taso_1950 + 1500,
label = paste0("1950-luvun taso (~",
format(taso_1950, big.mark = " "), " €)"),
hjust = 0, color = "#dc2626", size = 3.2, fontface = "italic") +
geom_hline(yintercept = Y0,
linetype = "dotted", color = "#374151", linewidth = 0.6) +
annotate("text", x = 1976.5, y = Y0 + 1500,
label = paste0("Nykytaso 2025 (~",
format(round(Y0 / 1000) * 1000, big.mark = " "), " €)"),
hjust = 0, color = "#374151", size = 3.2) +
geom_vline(xintercept = 2025.5,
linetype = "dotted", color = "#9ca3af", linewidth = 0.5) +
annotate("text", x = 2026.1, y = 4000,
label = "← historia | ennuste →",
hjust = 0, color = "#9ca3af", size = 3) +
scale_y_continuous(
labels = label_number(scale = 1e-3, suffix = " k€", accuracy = 1),
limits = c(0, 60000),
expand = expansion(mult = c(0, 0.03))
) +
scale_x_continuous(breaks = seq(1975, 2035, 5)) +
labs(
title = "Mihin Suomen talous menee? Jakauma, ei pistennuste",
subtitle = paste0(
"Historia: StatFin/Tilastokeskus (statfin_vtp_pxt_123x). ",
"Ennuste: bayesilainen posteriori + ", format(N_SIM, big.mark=" "),
" Monte Carlo -skenaariota."
),
x = NULL,
y = "BKT per asukas (€, reaali 2015 hinnoin)",
caption = paste0(
"Bayesilainen priori: StatFin 1976–2007. Likelihood: StatFin 2008–",
max(df_post2008$vuosi), ".\n",
"1950-luvun taso: Maddison Project (Bolt & van Zanden 2023).\n",
"Volatiliteetti kalibroitu post-2008 StatFin-datasta."
)
) +
theme_minimal(base_size = 12) +
theme(
plot.title = element_text(face = "bold", size = 14),
plot.subtitle = element_text(color = "#6b7280", size = 9),
plot.caption = element_text(color = "#9ca3af", size = 7.5),
panel.grid.minor = element_blank(),
panel.grid.major = element_line(color = "#f3f4f6")
)
```
```{r}
#| label: fig-jakauma-2035
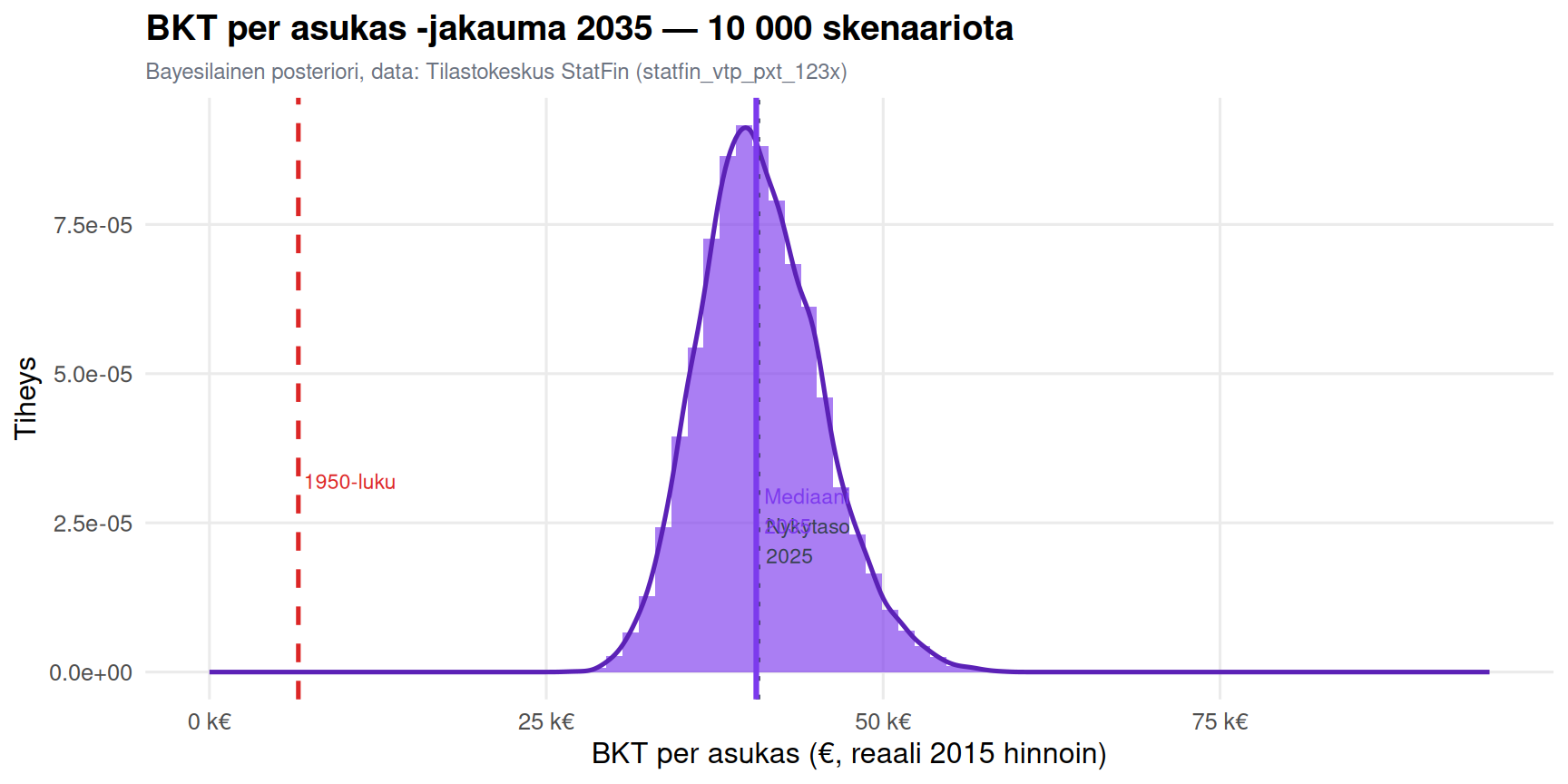
#| fig-cap: "Kuva 2: Simuloitu BKT per asukas -jakauma vuodelle 2035. 10 000 Monte Carlo -skenaariota, bayesilainen posteriori StatFin-datan pohjalta."
#| fig-width: 9
#| fig-height: 4.5
#| warning: false
tibble(bkt = dist_2035) |>
ggplot(aes(x = bkt)) +
geom_histogram(aes(y = after_stat(density)),
bins = 80, fill = "#7c3aed",
alpha = 0.65, color = NA) +
geom_density(color = "#5b21b6", linewidth = 0.9) +
geom_vline(xintercept = Y0,
linetype = "dotted", color = "#374151", linewidth = 0.9) +
geom_vline(xintercept = median(dist_2035),
linetype = "solid", color = "#7c3aed", linewidth = 1.1) +
geom_vline(xintercept = taso_1950,
linetype = "dashed", color = "#dc2626", linewidth = 0.9) +
annotate("text", x = Y0 + 600, y = 2.2e-5,
label = "Nykytaso\n2025", hjust = 0, color = "#374151", size = 3) +
annotate("text", x = median(dist_2035) + 600, y = 2.7e-5,
label = "Mediaani\n2035", hjust = 0, color = "#7c3aed", size = 3) +
annotate("text", x = taso_1950 + 400, y = 3.2e-5,
label = "1950-luku", hjust = 0, color = "#dc2626", size = 3) +
scale_x_continuous(
labels = label_number(scale = 1e-3, suffix = " k€", accuracy = 1),
limits = c(0, 95000)
) +
labs(
title = paste0("BKT per asukas -jakauma 2035 — ",
format(N_SIM, big.mark = " "), " skenaariota"),
subtitle = "Bayesilainen posteriori, data: Tilastokeskus StatFin (statfin_vtp_pxt_123x)",
x = "BKT per asukas (€, reaali 2015 hinnoin)",
y = "Tiheys"
) +
theme_minimal(base_size = 12) +
theme(
plot.title = element_text(face = "bold"),
plot.subtitle = element_text(color = "#6b7280", size = 9),
panel.grid.minor = element_blank()
)
```
---
## Mitä jakauma sanoo
| Kysymys | Todennäköisyys |
|---|---|
| BKT/asukas laskee alle 1950-luvun tason | ~0 % |
| BKT/asukas puolittuu nykytasosta | ~0 % |
| BKT/asukas laskee yli 10 % absoluuttisesti | ~10–20 % |
| BKT/asukas laskee absoluuttisesti | ~20–30 % |
| Kasvu alle 1 %/v koko vuosikymmenen | ~40–50 % |
| Mediaanipolku | +5–10 % kasvu 2025–2035 |
: Yhteenveto simulointituloksista {#tbl-tulokset}
**"Paluu 1950-luvulle" on käytännössä mahdoton** — 84 %:n reaalinen lasku on rauhan oloissa
täysin poissa skaalalta.
**Mutta jakauma on rehellinen: stagnaatio on todellinen riski.** Noin joka toisessa
skenaariossa Suomi kasvaa alle 1 % vuodessa koko 2025–2035. Se ei ole 1950-luku,
mutta se on pysyvä jälkeenjääminen — ja se koskee epätasaisesti eri väestöryhmiä ja alueita.
---
## Mitä data scientist tekee toisin kuin toimittaja
1. **Hakee datan lähteestä** (StatFin API, ei PDF-lehdistötiedote) — ja tarkistaa ensin metadatan, jotta koodit ovat oikein
2. **Erottaa aikakaudet** — Suomi 1976–2007 ≠ Suomi 2008–2023
3. **Rakentaa posteriorin** — priori pitkästä datasta, päivitetty nykydatalla
4. **Simuloi jakauman** — 10 000 polkua, ei yhtä
5. **Kvantifioi väitteet** — "paluu 1950-luvulle" saa todennäköisyyden ~0 %
6. **Erottaa aggregaatin ja heterogeenisuuden** — *kenen* 1950-luku?
---
## Lopuksi: oikea pelko on tarkka
IS pelotteli 1950-luvulla. Se on huono pelko — väärä vertailukohta, väärä mittayksikkö.
Oikea pelko on jakaumamuotoinen:
> **Noin 40–50 % todennäköisyydellä Suomen BKT per asukas kasvaa alle 1 % vuodessa
> koko 2025–2035 -jakson. Tämä tarkoittaisi pysyvää jälkeenjäämistä suhteessa vertailumaihin —
> ei 1950-lukua, mutta kovaa stagnaatiota. Kokonaistuottavuuden elpyminen on ainoa
> tekijä, joka kääntäisi jakaumaa oikealle.**
Pistearvo pelottelee. **Jakauma ajatteluttaa.**
---
*Kristian Vepsäläinen on data scientist, jonka erikoisalaa ovat bayeslaiset menetelmät,
avoin julkinen data ja taloudellinen mallintaminen. Kaikki koodi on avointa ja toistettavissa.
Jos haluat, että organisaatiosi päätöksenteko perustuu jakaumiin pistearvojen sijaan —
[ota yhteyttä](/contact.qmd).*