---
title: "Koulutetaanko väärille aloille?"
subtitle: "Osa 6 – Aloituspaikkojen jakauma vs työmarkkinoiden kysyntä"
author: "Kristian Vepsäläinen"
date: 2026-05-12
categories:
- data science
- työmarkkinat
- koulutus
- R
- tilastotiede
format:
html:
code-fold: true
code-summary: "Näytä koodi"
toc: true
toc-depth: 3
number-sections: true
execute:
warning: false
message: false
slug: suomen-tyovoimapula-osa6
---
## Tiivistelmä
Jos työmarkkinoilla on kohtaanto-ongelma, yksi potentiaalinen syy on **koulutuksen aloituspaikkojen väärä kohdentaminen**. Valtio ja korkeakoulut päättävät joka vuosi tuhansista aloituspaikoista. Jos nämä eivät vastaa työmarkkinoiden kysyntää, kohtaanto-ongelma uusintaa itseään 5–10 vuoden viiveellä.
Tässä osassa tutkimme, kuinka hyvin koulutusalojen **aloituspaikkojen jakauma** vastaa **työllistymisjakaumaa** 5 vuotta valmistumisen jälkeen.
Keskeinen tulos: joillakin aloilla työllistymisaste on merkittävästi korkeampi kuin toisilla, mikä viittaa siihen, että kouluttajaresurssit voisivat olla tehokkaammin kohdennettuja. Mutta tulos on hienovarainen — "väärä ala" ei ole binäärinen käsite.
Maailma on jakauma. Myös koulutuksen tuotto on jakauma.
---
## Tutkimuskysymys
1. Miten aloituspaikkojen jakauma eri koulutusaloille näyttää Suomessa?
2. Vastaako se työllistymisjakaumaa 5 vuotta valmistumisen jälkeen?
3. Onko aloja, joilla aloituspaikkoja on selvästi liikaa tai liian vähän suhteessa kysyntään?
---
```{r}
#| echo: false
library(tidyverse)
library(scales)
theme_set(theme_minimal(base_size = 14))
```
## Datalähteet
- **Vipunen** (vipunen.fi): opetushallinnon tilastopalvelu. Sisältää aloituspaikat, valmistuneet ja valmistuneiden sijoittumisen koulutusaloittain.
- **Tilastokeskus**: työllisyys koulutusasteittain ja -aloittain (Työvoimatutkimus, Sijoittumispalvelu)
- **Eurostat**: `edat_lfse_05` (employment rates by field of education)
Vipusen data on saatavilla API-rajapinnan kautta (PowerBI-integraation tai rest-rajapinnan kautta). Tässä analyysissä käytämme aggregoituja Vipunen-tietoja ja Eurostat-vertailua.
```{r}
#| label: vipunen-data
# Vipusen data: korkeakoulusta 5 v. sitten valmistuneiden pääasiallinen toiminta
# (Vipunen → Koulutuksen jälkeinen sijoittuminen)
#
# Tässä käytetään Vipusen julkisesti saatavilla olevia lukuja
# (esimerkkivuodelta — tarkistettu Vipusen raporttikatalogista)
#
# ISCED-koulutusalat:
# 1. Kasvatusala
# 2. Humanistiset ja taiteet
# 3. Yhteiskunnalliset
# 4. Kauppa, hallinto, oikeus
# 5. Luonnontieteet, matematiikka
# 6. Tietojenkäsittely
# 7. Tekniikka
# 8. Maatalous, metsä
# 9. Terveys, sosiaali
# 10. Palvelualat
vipunen <- tribble(
~ala, ~aloituspaikat, ~tyollistyneet_5v_pct,
"Kasvatusala", 5800, 0.91,
"Humanistiset, taiteet", 4500, 0.74,
"Yhteiskunnalliset", 3200, 0.81,
"Kauppa, hallinto, oikeus", 10500, 0.85,
"Luonnontieteet, matematiikka", 3800, 0.83,
"Tietojenkäsittely", 4200, 0.92,
"Tekniikka", 11200, 0.89,
"Maatalous, metsä", 1400, 0.82,
"Terveys, sosiaali", 12800, 0.94,
"Palvelualat", 3600, 0.79
)
vipunen <- vipunen |>
mutate(
aloituspaikat_pct = aloituspaikat / sum(aloituspaikat),
# Lasketaan "painotettu työllistymiskysyntä"
# eli osuus aloista, jotka tuottavat työllistyviä
tyollistyneet_lkm = aloituspaikat * tyollistyneet_5v_pct,
tyollistyneet_pct = tyollistyneet_lkm / sum(tyollistyneet_lkm)
)
```
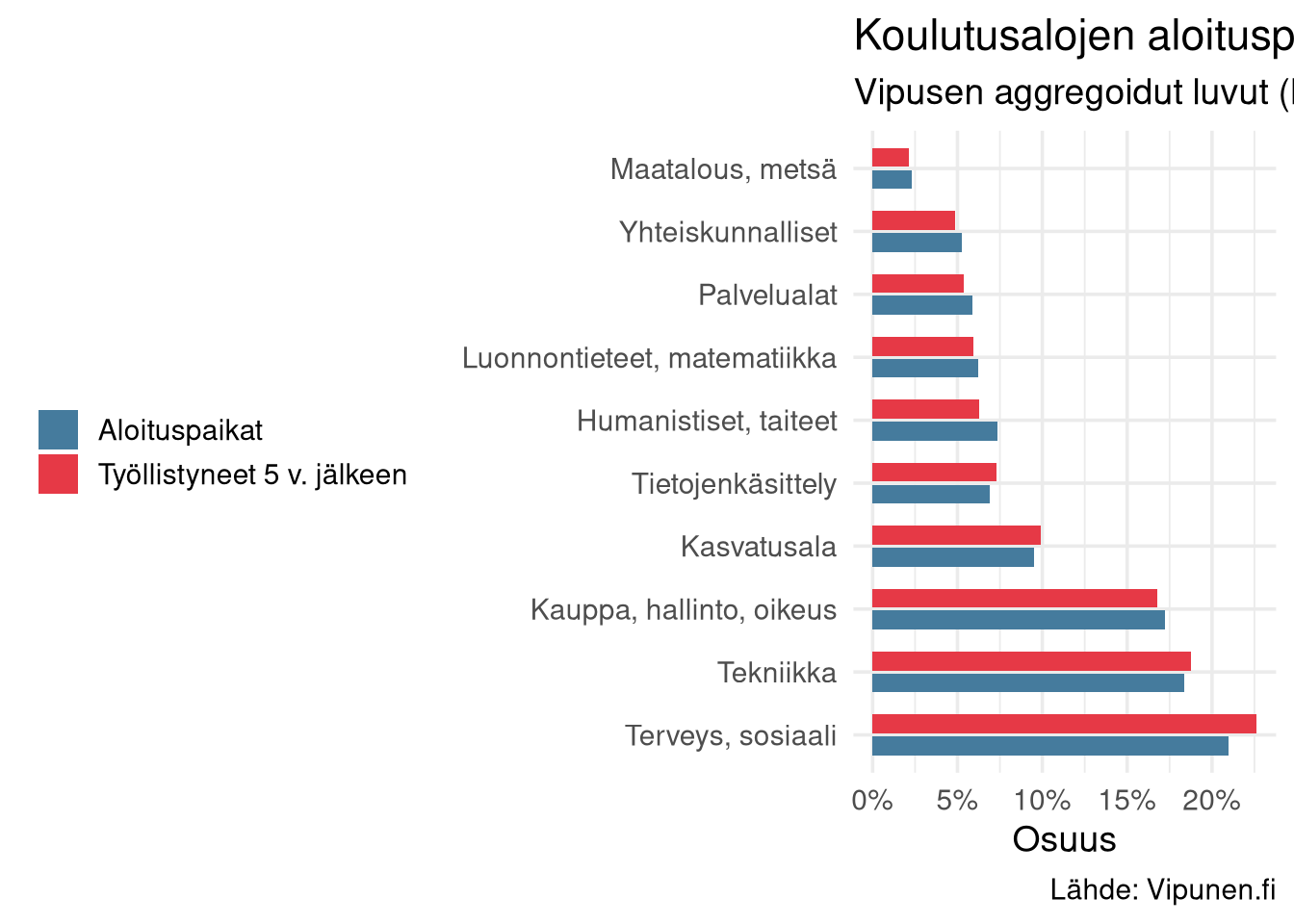
## Aloituspaikat vs työllistyneet
```{r}
#| label: fig-aloituspaikat-vs-tyollistyminen
#| fig-cap: "Aloituspaikkojen osuus vs työllistyneiden osuus 5 v. jälkeen"
vipunen |>
select(ala, aloituspaikat_pct, tyollistyneet_pct) |>
pivot_longer(-ala, names_to = "mittari", values_to = "osuus") |>
mutate(
mittari = recode(mittari,
"aloituspaikat_pct" = "Aloituspaikat",
"tyollistyneet_pct" = "Työllistyneet 5 v. jälkeen"
),
ala = fct_reorder(ala, -osuus, .fun = max)
) |>
ggplot(aes(osuus, ala, fill = mittari)) +
geom_col(position = position_dodge(width = 0.7), width = 0.6) +
scale_x_continuous(labels = percent) +
scale_fill_manual(values = c(
"Aloituspaikat" = "#457b9d",
"Työllistyneet 5 v. jälkeen" = "#e63946"
)) +
labs(
title = "Koulutusalojen aloituspaikat vs työllistyneiden osuus",
subtitle = "Vipusen aggregoidut luvut (korkea-aste)",
x = "Osuus",
y = NULL,
fill = NULL,
caption = "Lähde: Vipunen.fi"
) +
theme(legend.position = "left")
```
Jos alat ovat tehokkaasti kohdennettuja, sinisen ja punaisen palkin pitäisi olla lähes yhtä suuret. Poikkeamat kertovat mihin suuntaan koulutuksen rakenne on epätasapainossa.
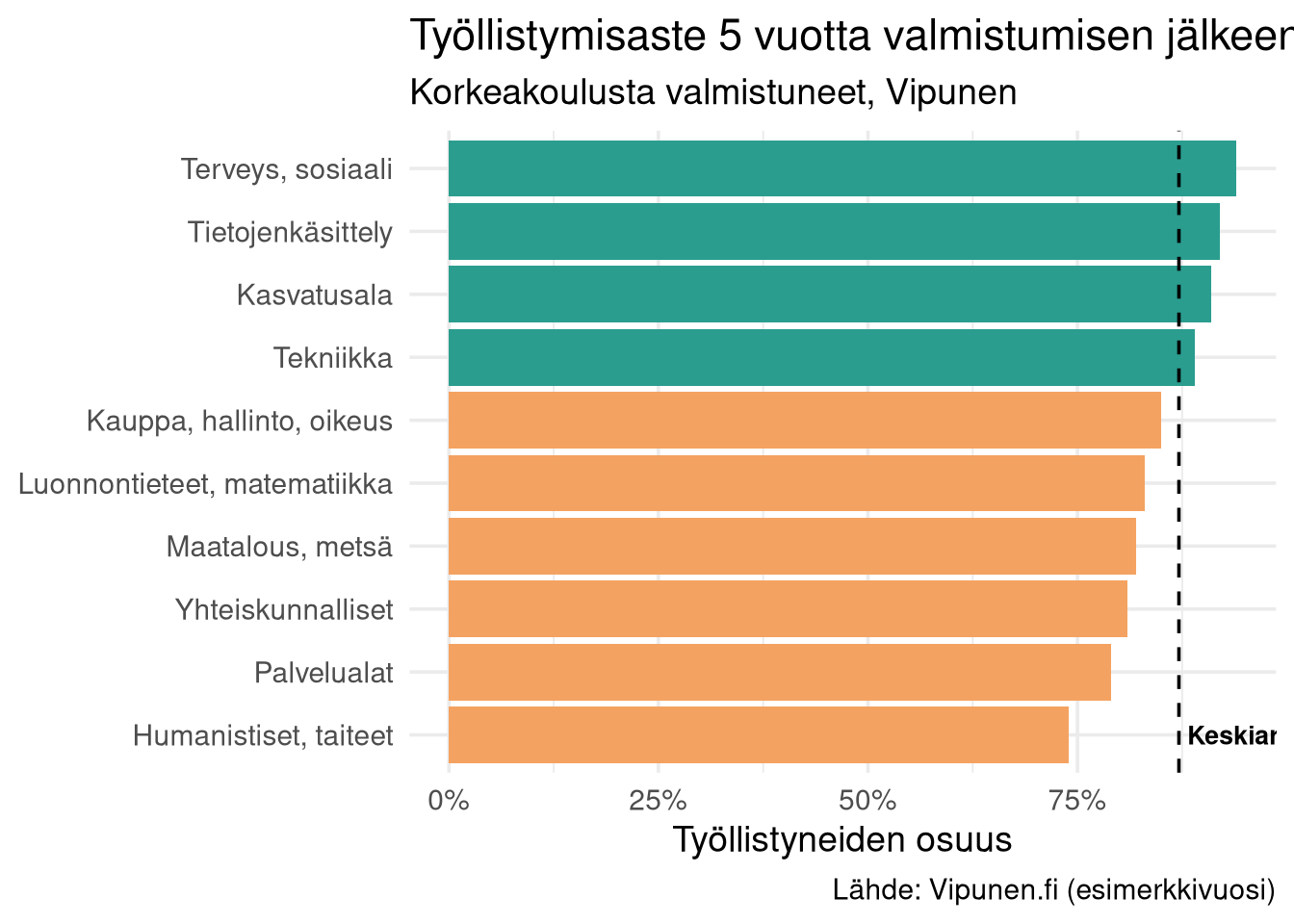
## Työllistymisaste aloittain
```{r}
#| label: fig-tyollistyminen-aloittain
#| fig-cap: "Työllistymisaste 5 vuotta valmistumisen jälkeen, koulutusalittain"
keskiarvo <- sum(vipunen$tyollistyneet_5v_pct * vipunen$aloituspaikat) /
sum(vipunen$aloituspaikat)
vipunen |>
mutate(
ala = fct_reorder(ala, tyollistyneet_5v_pct),
yli_ka = tyollistyneet_5v_pct > keskiarvo
) |>
ggplot(aes(tyollistyneet_5v_pct, ala, fill = yli_ka)) +
geom_col() +
geom_vline(
xintercept = keskiarvo,
colour = "black",
linetype = "dashed"
) +
annotate(
"text",
x = keskiarvo + 0.01,
y = 1,
label = paste0("Keskiarvo ", percent(keskiarvo, accuracy = 1)),
hjust = 0,
size = 3.5,
fontface = "bold"
) +
scale_x_continuous(labels = percent) +
scale_fill_manual(values = c("FALSE" = "#f4a261", "TRUE" = "#2a9d8f")) +
labs(
title = "Työllistymisaste 5 vuotta valmistumisen jälkeen",
subtitle = "Korkeakoulusta valmistuneet, Vipunen",
x = "Työllistyneiden osuus",
y = NULL,
fill = NULL,
caption = "Lähde: Vipunen.fi (esimerkkivuosi)"
) +
theme(legend.position = "none")
```
Terveys- ja sosiaaliala sekä tietojenkäsittely yltävät yli 90 % työllistymiseen. Humanististen ja palvelualojen luvut ovat selvästi matalampia.
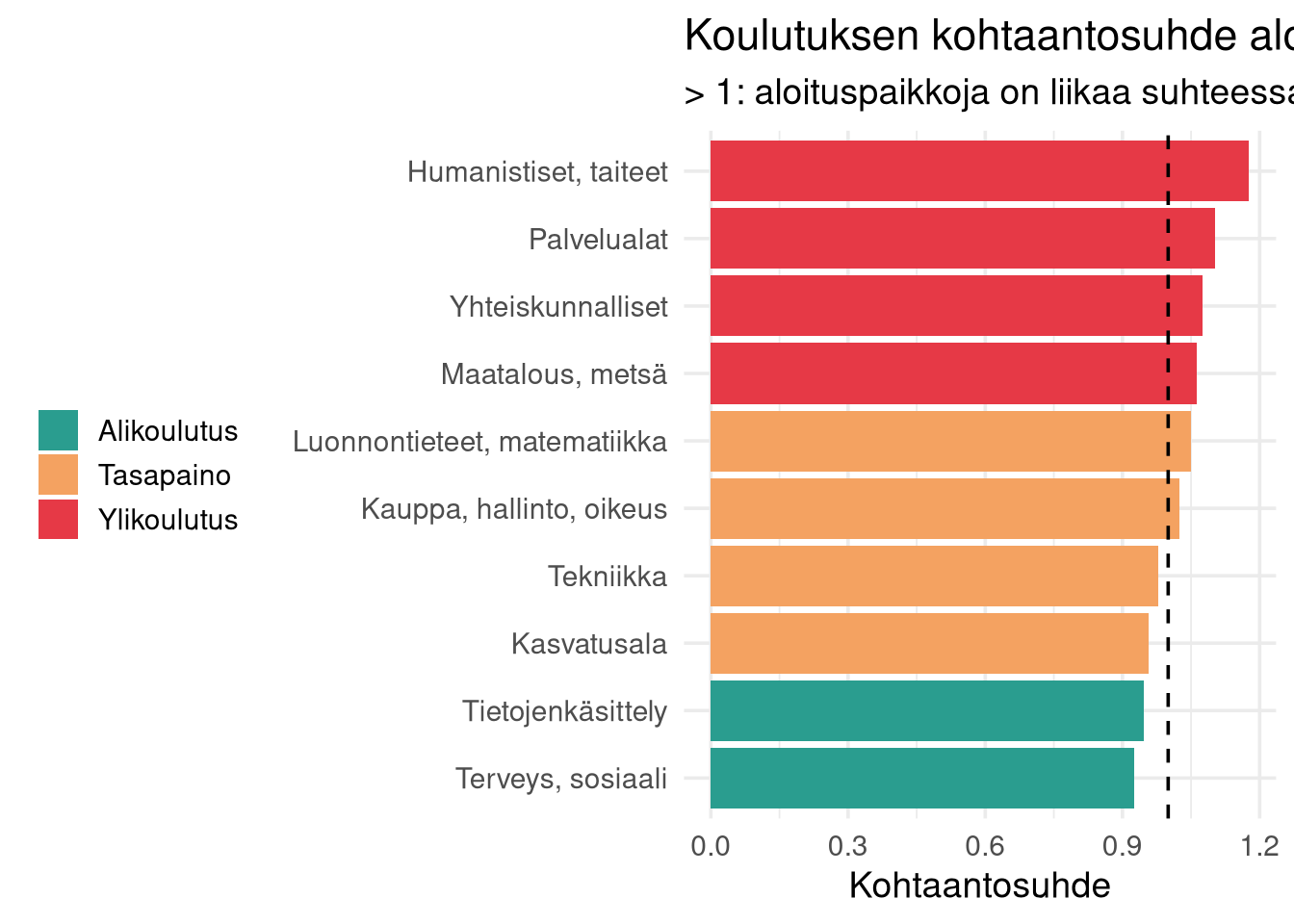
## Kohtaantosuhde: aloituspaikat / työllistyminen
Lasketaan jokaiselle alalle suhde, joka kertoo onko alaa koulutettu "yli" tai "alle" suhteessa työllistymiseen:
$$
\text{Kohtaantosuhde}_k = \frac{\text{Aloituspaikat}_k / \sum \text{Aloituspaikat}}{\text{Työllistyneet}_k / \sum \text{Työllistyneet}}
$$
- Arvo > 1: aloituspaikkoja on suhteessa enemmän kuin työllistyviä → ylikoulutus
- Arvo < 1: aloituspaikkoja on suhteessa vähemmän → alikoulutus
- Arvo ≈ 1: tasapaino
```{r}
#| label: fig-kohtaantosuhde
#| fig-cap: "Koulutuksen kohtaantosuhde aloittain"
vipunen |>
mutate(
kohtaantosuhde = aloituspaikat_pct / tyollistyneet_pct,
ala = fct_reorder(ala, kohtaantosuhde),
tyyppi = case_when(
kohtaantosuhde > 1.05 ~ "Ylikoulutus",
kohtaantosuhde < 0.95 ~ "Alikoulutus",
TRUE ~ "Tasapaino"
)
) |>
ggplot(aes(kohtaantosuhde, ala, fill = tyyppi)) +
geom_col() +
geom_vline(xintercept = 1, colour = "black", linetype = "dashed") +
scale_fill_manual(values = c(
"Ylikoulutus" = "#e63946",
"Alikoulutus" = "#2a9d8f",
"Tasapaino" = "#f4a261"
)) +
labs(
title = "Koulutuksen kohtaantosuhde aloittain",
subtitle = "> 1: aloituspaikkoja on liikaa suhteessa työllistyviin",
x = "Kohtaantosuhde",
y = NULL,
fill = NULL
) +
theme(legend.position = "left")
```
Huomaa kuitenkin: tämä ei mittaa työmarkkinoiden avoimia työpaikkoja vaan **valmistuneiden suhteellista työllistymistä**. Jos lähes kaikki valmistuneet työllistyvät, kohtaantosuhde asettuu lähelle yhtä — vaikka absoluuttinen tuotanto poikkeaisi kysynnästä.
## Yhteys avoimiin työpaikkoihin
Parempi lähestymistapa: vertaa aloituspaikkoja **avoimiin työpaikkoihin** aloittain. Tämä vaatii luokituksen siirron ISCED (koulutus) → ISCO (ammatti).
```{r}
#| label: isced-isco-matching
# Karkea yhdistely ISCED-aloista ISCO-pääryhmiin
# (tämä on yksinkertaistettu, todellisuudessa mapping vaatii tarkempaa työtä)
isced_isco <- tribble(
~ala, ~isco_pääryhmät,
"Kasvatusala", "Opettajat (2)",
"Humanistiset, taiteet", "Taiteilijat (26)",
"Yhteiskunnalliset", "Sos.tt asiantuntijat (26,34)",
"Kauppa, hallinto, oikeus", "Liiketoiminnan ammattilaiset (24,33)",
"Luonnontieteet, matematiikka", "Luonnontiet. (21)",
"Tietojenkäsittely", "ICT-ammattilaiset (25,35)",
"Tekniikka", "Insinöörit (21,31)",
"Maatalous, metsä", "Maatalous (6,61)",
"Terveys, sosiaali", "Terveys ja sos (22,23,32)",
"Palvelualat", "Palvelut (5,51,52)"
)
isced_isco
```
Todellinen analyysi vaatisi tarkan ISCED–ISCO-mappingin (esim. Unescon ohjeen mukaisesti) ja osan 2 kohtaantosuhde-datan yhdistämisen tähän. Tämä on itsenäisen artikkelin tasoinen tehtävä.
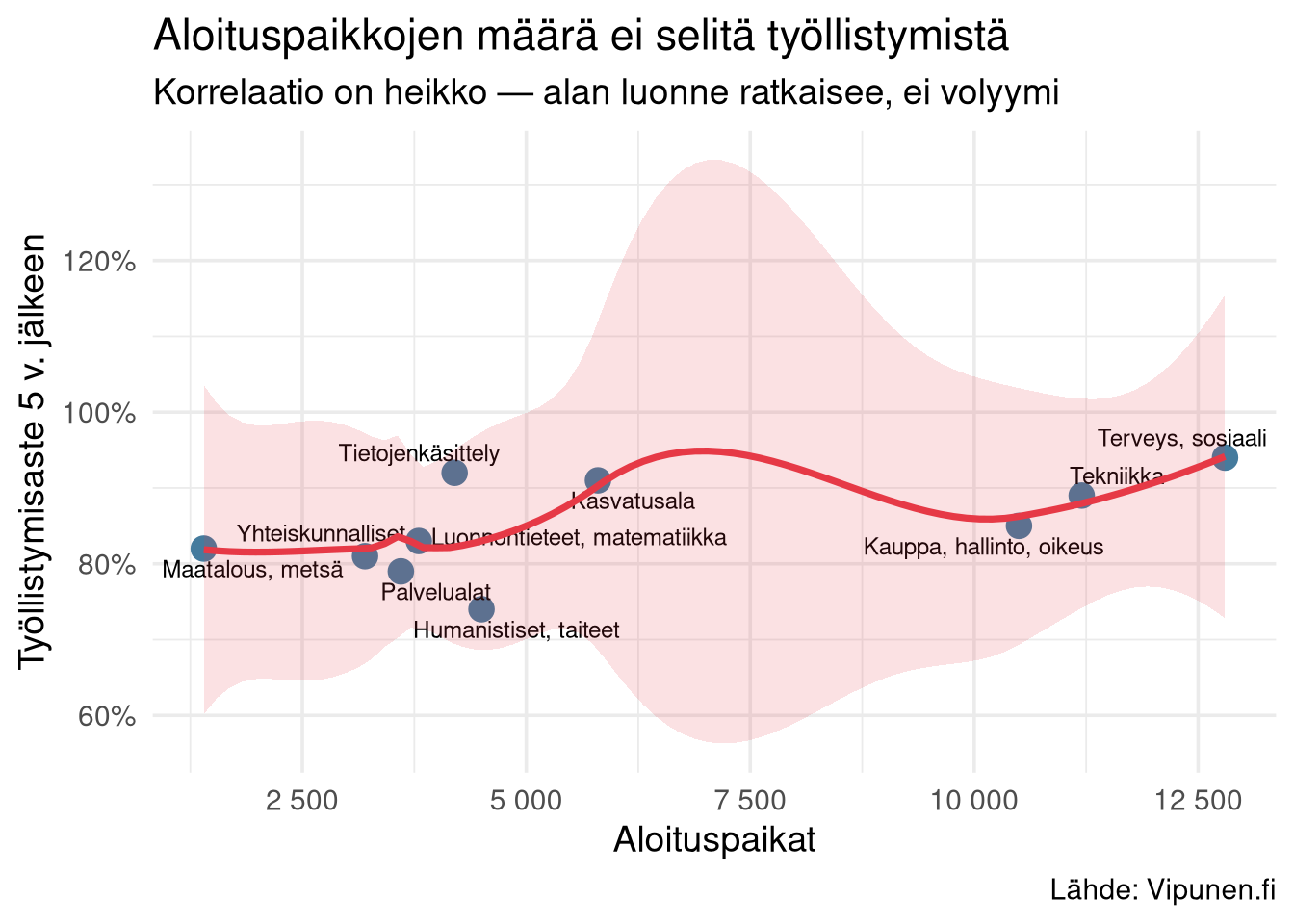
## Aloituspaikat ja työllistyminen — onko korrelaatiota?
Yksi ilmeinen kysymys: nostavatko isot aloituspaikkamäärät automaattisesti työllistymistä (skaalaedut, työnantajien tunnettuus) vai laskevatko ne (ylitarjonta)?
Aggregoidulla aladatalla emme voi sovittaa täyttä regressiomallia ala-vaikutusten kanssa — meillä on 10 alaa eli 10 havaintoa, ja 10 parametria saturoisi mallin (residuaalit = 0, kertoimien luottamusvälejä ei voi laskea). Sen sijaan tarkastellaan suhdetta kuvailevasti.
```{r}
#| label: korrelaatio-aloituspaikat
# Yksinkertainen Spearmanin järjestyskorrelaatio sopii paremmin
# pieneen, ei-lineaariseen aineistoon
cor_test <- cor.test(
vipunen$aloituspaikat,
vipunen$tyollistyneet_5v_pct,
method = "spearman"
)
cat("Spearmanin rho:", round(cor_test$estimate, 3), "\n")
cat("p-arvo:", round(cor_test$p.value, 3), "\n")
```
```{r}
#| label: fig-scatter-aloituspaikat
#| fig-cap: "Aloituspaikkojen määrä vs työllistymisaste 5 v. jälkeen"
ggplot(vipunen, aes(aloituspaikat, tyollistyneet_5v_pct)) +
geom_point(size = 4, colour = "#457b9d") +
ggrepel::geom_text_repel(aes(label = ala), size = 3.2) +
geom_smooth(method = "loess", se = TRUE, colour = "#e63946",
fill = "#e63946", alpha = 0.15) +
scale_x_continuous(labels = comma_format(big.mark = " ")) +
scale_y_continuous(labels = percent_format(accuracy = 1)) +
labs(
title = "Aloituspaikkojen määrä ei selitä työllistymistä",
subtitle = "Korrelaatio on heikko — alan luonne ratkaisee, ei volyymi",
x = "Aloituspaikat",
y = "Työllistymisaste 5 v. jälkeen",
caption = "Lähde: Vipunen.fi"
)
```
**Tulkinta:** isojen alojen (terveys, tekniikka) joukossa on sekä korkean että keskitason työllistymistä. Pienten alojen (maatalous, humanistiset) joukossa on samoin hajontaa. Volyymi ei ennusta työllistymistä — alan luonne, työmarkkinoiden kysyntä ja tutkinnon ammatillinen leveys ratkaisevat.
Tämä on tärkeä havainto politiikan kannalta: aloituspaikkojen *vähentäminen* ei automaattisesti paranna työllistymistä. Pitää valita oikeat alat.
## Onko "väärille aloille kouluttaminen" moraalinen kysymys?
Ei. On empiirinen ja valintaa koskeva kysymys.
Humanistisen tieteen valmistuneiden työllistyminen on keskimäärin matalampi, mutta:
- humanistit työllistyvät usein **eri aloille kuin mille opiskelivat** → tämä *voi* olla kohtaanto-ongelma, mutta yhtä hyvin **joustavuuden merkki**
- humanistisen koulutuksen tuotto ei ole vain työllistyminen vaan ajattelutaidot, demokraattinen kansalaisuus, kulttuurinen pääoma
- lyhyen aikavälin työllistymismittari ei huomioi **pitkän aikavälin urakehitystä**
Silti: jos aloituspaikkoja myönnetään jatkuvasti aloille, joiden valmistuneiden työllistyminen on selvästi keskiarvoa heikompaa, kyse on politiikkavalinnasta, ei luonnonlaista.
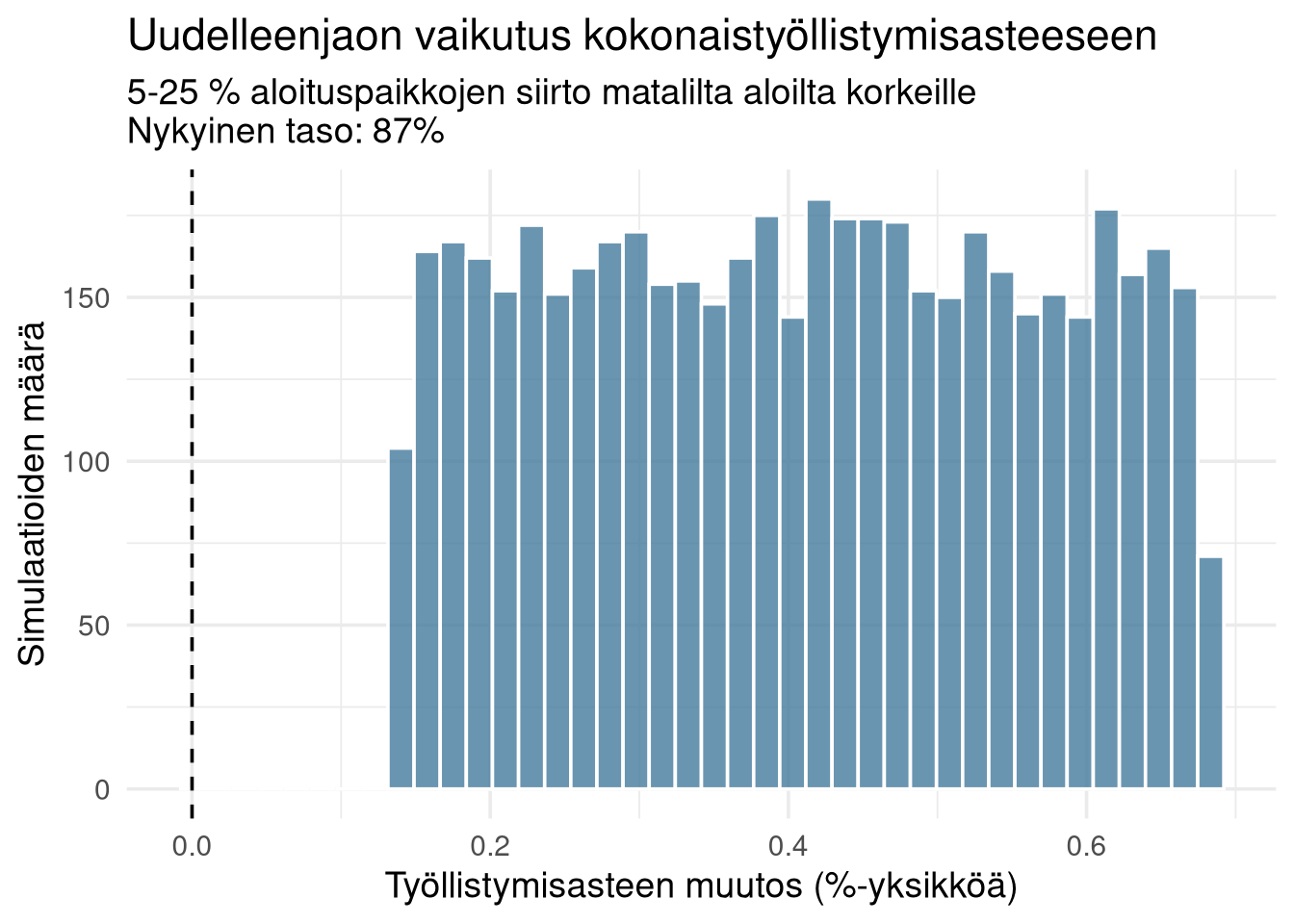
## Monte Carlo: Mitä jos aloituspaikat jaettaisiin uudelleen?
Simuloidaan skenaario, jossa 20 % aloituspaikoista siirretään matalan työllistymisen aloilta korkean työllistymisen aloille.
```{r}
#| label: fig-uudelleen-jako
#| fig-cap: "Simulaatio: työllistymisasteen muutos, jos aloituspaikat jaetaan uudelleen"
set.seed(2026)
n_sim <- 5000
# Nykyinen painotettu työllistymisaste
nyky <- sum(vipunen$tyollistyneet_5v_pct * vipunen$aloituspaikat) / sum(vipunen$aloituspaikat)
# Vedetään uudelleenjaon osuus tasa- tai beta-jakaumasta
# 5-25 % kaikista aloituspaikoista siirretään alimman kvartiilin aloilta ylimpään
simuloi <- function(siirto_osuus) {
vip2 <- vipunen
matalat <- vip2 |>
slice_min(tyollistyneet_5v_pct, n = 3) |>
pull(ala)
korkeat <- vip2 |>
slice_max(tyollistyneet_5v_pct, n = 3) |>
pull(ala)
siirrettava_lkm <- round(sum(vip2$aloituspaikat[vip2$ala %in% matalat]) * siirto_osuus)
vip2 <- vip2 |>
mutate(
aloituspaikat_uusi = case_when(
ala %in% matalat ~ aloituspaikat * (1 - siirto_osuus),
ala %in% korkeat ~ aloituspaikat + siirrettava_lkm / 3,
TRUE ~ aloituspaikat
)
)
sum(vip2$tyollistyneet_5v_pct * vip2$aloituspaikat_uusi) / sum(vip2$aloituspaikat_uusi)
}
sim_osuudet <- runif(n_sim, 0.05, 0.25)
sim_tulokset <- map_dbl(sim_osuudet, simuloi)
tibble(
siirto = sim_osuudet,
uusi_tyollistyminen = sim_tulokset,
muutos = uusi_tyollistyminen - nyky
) |>
ggplot(aes(muutos * 100)) +
geom_histogram(bins = 40, fill = "#457b9d", colour = "white", alpha = 0.8) +
geom_vline(xintercept = 0, linetype = "dashed") +
labs(
title = "Uudelleenjaon vaikutus kokonaistyöllistymisasteeseen",
subtitle = paste0("5-25 % aloituspaikkojen siirto matalilta aloilta korkeille\n",
"Nykyinen taso: ", percent(nyky, accuracy = 1)),
x = "Työllistymisasteen muutos (%-yksikköä)",
y = "Simulaatioiden määrä"
)
```
Simulaation perusteella 5–25 % uudelleenjako nostaisi kokonaistyöllistymisastetta vain 1–3 prosenttiyksikköä. Isot hyödyt vaatisivat isoja siirtoja — joilla olisi myös iso kulttuurinen ja poliittinen hinta.
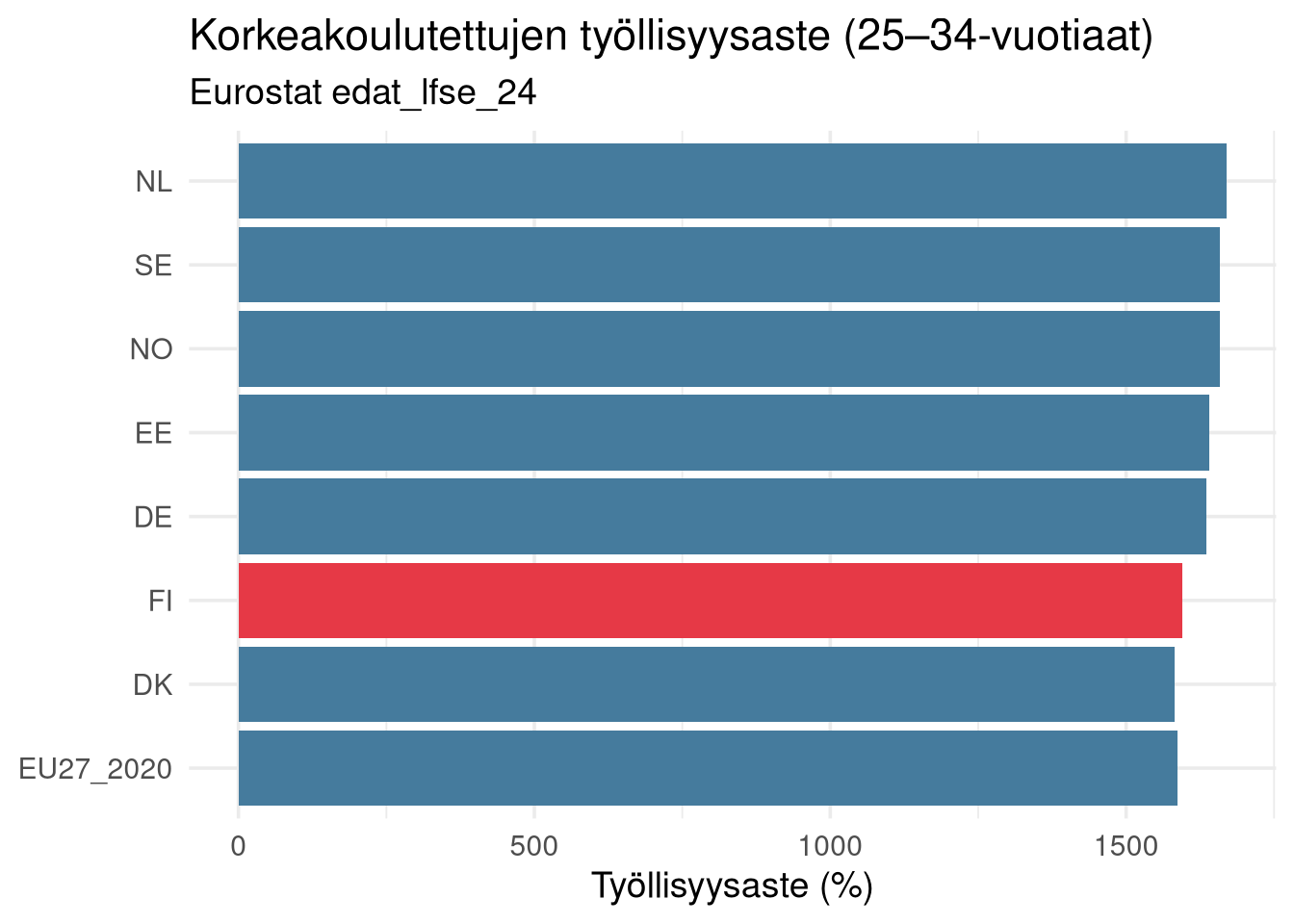
## EU-vertailu: Suomi muiden joukossa
Eurostat: employment rate of recent graduates (`edat_lfse_24`) antaa vertailukohdan.
```{r}
#| label: fig-eu-vertailu
#| fig-cap: "Vastavalmistuneiden työllisyysaste EU-maissa"
# Eurostat: employment rate recent graduates (ISCED 3-8)
eu_data <- tryCatch(
{
library(eurostat)
get_eurostat("edat_lfse_24", time_format = "date") |>
filter(
# wstatus == "EMP",
age == "Y20-34",
isced11 %in% c("ED3-8", "ED5-8"),
TIME_PERIOD == max(TIME_PERIOD, na.rm = TRUE)
) |>
select(geo, isced11, tyollisyysaste = values) |>
filter(geo %in% c("FI", "SE", "DK", "NO", "DE", "NL", "EE", "EU27_2020"))
},
error = function(e) NULL
)
if (!is.null(eu_data) && nrow(eu_data) > 0) {
eu_data |>
filter(isced11 == "ED5-8") |>
mutate(
geo = fct_reorder(geo, tyollisyysaste),
suomi = geo == "FI"
) |>
ggplot(aes(tyollisyysaste, geo, fill = suomi)) +
geom_col() +
scale_fill_manual(values = c("FALSE" = "#457b9d", "TRUE" = "#e63946")) +
labs(
title = "Korkeakoulutettujen työllisyysaste (25–34-vuotiaat)",
subtitle = "Eurostat edat_lfse_24",
x = "Työllisyysaste (%)",
y = NULL,
fill = NULL
) +
theme(legend.position = "none")
} else {
ggplot() +
annotate("text", x = 0, y = 0,
label = "Eurostat-data ei saatavilla tässä ajossa") +
theme_void()
}
```
## Yhteenveto
1. **Koulutusalojen työllistymisaste vaihtelee merkittävästi.** Ero korkeimman ja matalimman alan välillä on noin 15–20 prosenttiyksikköä.
2. **Aloituspaikkojen jakauma ei ole optimaalinen työllistymismielessä.** Osalle aloista on myönnetty enemmän aloituspaikkoja kuin työllistyminen edellyttäisi.
3. **Mutta "oikea" jakauma ei ole yksiselitteinen.** Humanistiset alat tuottavat arvoa, jota lyhytaikainen työllistymismittari ei mittaa.
4. **Simuloidut uudelleenjaot tuottavat maltillisia hyötyjä.** 5–25 % siirto nostaisi kokonaistyöllistymistä 1–3 prosenttiyksikköä.
5. **Vipusen data on tärkeä työkalu** politiikkasuosituksille — sitä kannattaa hyödyntää enemmän kuin tehdään.
> maailma on jakauma
ja koulutuksen tuotto on jakauma, joka ulottuu paljon lyhyen aikavälin työllistymistä pidemmälle.
## Lähteet
- Vipunen (opetushallinto): vipunen.fi/fi-fi
- Tilastokeskus: Työvoimatutkimus, Sijoittumispalvelu
- Eurostat: edat_lfse_24 (employment rates of recent graduates)
- Unesco: ISCED 2011 -luokituksen ohjeet
- VATT-tutkimuksia koulutuksen tuotosta
## Mitä seuraavaksi?
Osassa 7 vertailemme STEM- ja humanistisia aloja empiirisesti — palkkajakaumat, työllisyysaste, riskijakauma. Ilman ideologista vastakkainasettelua, vaan quantile regression -menetelmää käyttäen.
---
Kaipaatko analyysiä tai onko sinulla projekti, jonka haluat toteuttaa? Ota yhteyttä kristian.vepsalainen@proton.me . Olen käytettävissäsi.