---
title: "Ovatko kaikki koulutettavissa?"
subtitle: "Osa 10 – Kognitiivisten kykyjen jakauma ja koulutuksen rajat"
author: "Kristian Vepsäläinen"
date: 2026-06-09
categories:
- data science
- työmarkkinat
- koulutus
- R
- tilastotiede
format:
html:
code-fold: true
code-summary: "Näytä koodi"
toc: true
toc-depth: 3
number-sections: true
execute:
warning: false
message: false
slug: suomen-tyovoimapula-osa10
---
## Tiivistelmä
Tämä on sarjan herkin kysymys — ja juuri siksi se pitää käsitellä datalla, ei intuitiolla.
Jos työvoimapulan vastaus on "kouluttamalla", oletamme implisiittisesti, että kuka tahansa voidaan kouluttaa mihin tahansa. Tämä oletus on empiirisesti virheellinen. Kognitiivisten kykyjen jakauma on laaja, ja osa aikuisväestöstä on kykyjensä puolesta rajoitettuja tehtäviin, jotka vaativat korkeaa abstraktia ajattelua.
Tämä **ei ole moraalinen väite**. Se on jakauman muoto.
Tässä osassa tarkastelemme:
- PIAAC-tulosten jakaumaa Suomessa
- NEET-populaation kokoa ja taustaa
- Mixture model -analyysiä: kuinka suuri osa voidaan realistisesti kouluttaa korkean osaamisen töihin?
Keskeinen tulos: perustaitoja mittaavat tutkimukset osoittavat, että noin 10–15 % työikäisestä väestöstä on sellaisella osaamistasolla, että siirtyminen korkean osaamisen ammatteihin on epätodennäköistä ilman erityistukea. Tämä ei tarkoita, että he olisivat "huonoja" — se tarkoittaa, että koulutus ei ole universaali ratkaisu.
Maailma on jakauma. Kykyjenkin jakauma.
---
## Tutkimuskysymys
Jos julkinen keskustelu olettaa, että kaikki työttömät ovat koulutuksella muunnettavissa pula-ammattien työntekijöiksi, kysymys on:
1. Miltä kognitiivisten taitojen jakauma näyttää aikuisväestössä?
2. Kuinka suuri osa aikuisväestöstä on alimmilla osaamistasoilla (PIAAC 1 tai alle)?
3. Kuinka paljon nämä alimmat tasot ylittäisivät korkean osaamisen ammattien vaatimukset?
---
```{r}
#| echo: false
library(tidyverse)
library(scales)
library(mixtools) # mixture-malliin
theme_set(theme_minimal(base_size = 14))
```
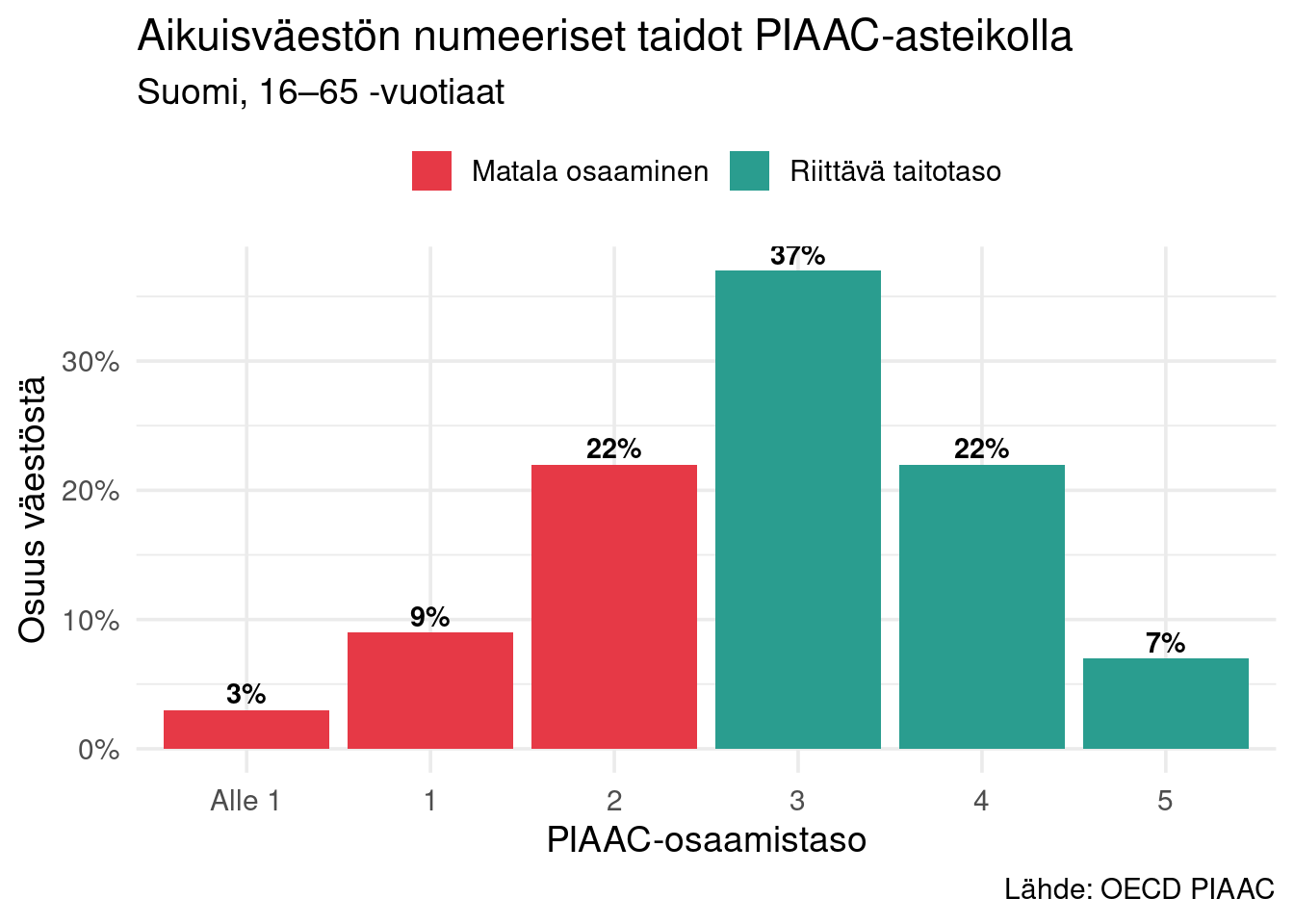
## PIAAC — Programme for the International Assessment of Adult Competencies
OECD:n PIAAC-tutkimus mittaa 16–65-vuotiaiden aikuisten osaamista kolmella alueella: lukutaito, numeeriset taidot ja ongelmanratkaisu teknologisessa ympäristössä.
Suomi on PIAAC:ssa tyypillisesti top 5 -tasoa, mutta silti jakauma on laaja.
```{r}
#| label: piaac-jakauma
# PIAAC-tulokset Suomelle, numeeriset taidot
# Jakauma on skaalattu 0–500. Tasot:
# 1 tai alle: < 226
# 2: 226-275
# 3: 276-325
# 4: 326-375
# 5: 376+
# OECD:n raportin mukaiset osuudet (Suomi, 2023 runs)
piaac_tasot <- tribble(
~taso, ~osuus,
"Alle 1", 0.03,
"1", 0.09,
"2", 0.22,
"3", 0.37,
"4", 0.22,
"5", 0.07
)
piaac_tasot |>
mutate(
taso = factor(taso, levels = c("Alle 1", "1", "2", "3", "4", "5")),
korkea = taso %in% c("3", "4", "5")
) |>
ggplot(aes(taso, osuus, fill = korkea)) +
geom_col() +
geom_text(
aes(label = percent(osuus, accuracy = 1)),
vjust = -0.3, size = 3.8, fontface = "bold"
) +
scale_y_continuous(labels = percent) +
scale_fill_manual(
values = c("FALSE" = "#e63946", "TRUE" = "#2a9d8f"),
labels = c("Matala osaaminen", "Riittävä taitotaso")
) +
labs(
title = "Aikuisväestön numeeriset taidot PIAAC-asteikolla",
subtitle = "Suomi, 16–65 -vuotiaat",
x = "PIAAC-osaamistaso",
y = "Osuus väestöstä",
fill = NULL,
caption = "Lähde: OECD PIAAC"
) +
theme(legend.position = "top")
```
**Huomio:** noin 12 % aikuisväestöstä on tasolla 1 tai alle. Tämä tarkoittaa merkittäviä vaikeuksia arkipäivän numeerisissa tehtävissä — laskujen maksu, korkojen ymmärtäminen, yksinkertaiset prosenttilaskut.
## Mikä on PIAAC-taso 1?
OECD:n määritelmän mukaan tason 1 numeeriset taidot vastaavat kykyä:
- laskea yhteen kokonaislukuja
- ymmärtää yksinkertaisia prosentteja (esim. 10 %:n alennus)
- tulkita yksinkertaisia taulukoita
Mikä **ei** onnistu tasolla 1:
- murtolukujen ja desimaalien vertailu
- monivaiheiset laskutehtävät
- ehdolliset todennäköisyyslaskelmat
- matemaattisten kaavojen soveltaminen
Nämä ovat perustaitoja, joita useimmat korkean osaamisen ammatit vaativat.
## Koulutuksen ja osaamisen yhteys
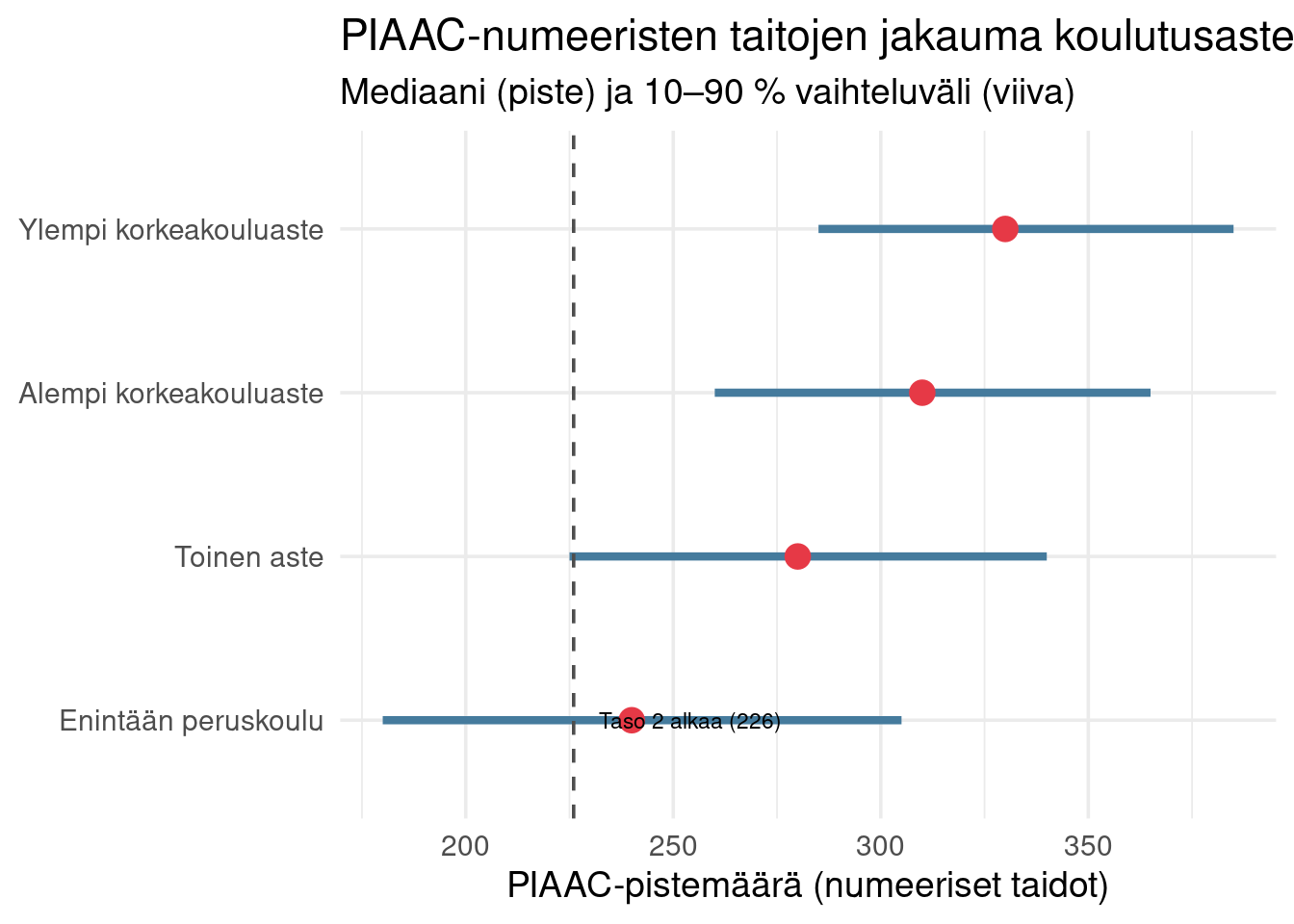
Koulutustaso ja PIAAC-tulokset korreloivat, mutta eivät täydellisesti. Korkeasti koulutetuissa on myös matalan osaamisen henkilöitä ja päinvastoin.
```{r}
#| label: fig-koulutus-piaac
# Simuloitu yhteys koulutuksen ja PIAAC-tulosten välillä
# Lähde: OECD PIAAC Country Note (Suomi)
koulutus_piaac <- tribble(
~koulutustaso, ~p10, ~p50, ~p90,
"Enintään peruskoulu", 180, 240, 305,
"Toinen aste", 225, 280, 340,
"Alempi korkeakouluaste", 260, 310, 365,
"Ylempi korkeakouluaste", 285, 330, 385
)
koulutus_piaac_long <- koulutus_piaac |>
pivot_longer(-koulutustaso, names_to = "kvantiili", values_to = "pisteet")
koulutus_piaac |>
mutate(koulutustaso = fct_inorder(koulutustaso)) |>
ggplot(aes(koulutustaso)) +
geom_linerange(aes(ymin = p10, ymax = p90), linewidth = 1.5, colour = "#457b9d") +
geom_point(aes(y = p50), size = 4, colour = "#e63946") +
geom_hline(yintercept = 226, linetype = "dashed", colour = "grey30") +
annotate(
"text",
x = 1, y = 232,
label = "Taso 2 alkaa (226)",
hjust = 0, size = 3
) +
labs(
title = "PIAAC-numeeristen taitojen jakauma koulutusasteittain",
subtitle = "Mediaani (piste) ja 10–90 % vaihteluväli (viiva)",
x = NULL,
y = "PIAAC-pistemäärä (numeeriset taidot)"
) +
coord_flip()
```
**Havainto:** koulutus ei automaattisesti tuo korkeaa osaamistasoa. Alemman korkeakouluasteen alimmissa kvantiileissa voi olla ihmisiä, jotka eivät kykene ylläpitämään tason 2 taitoja.
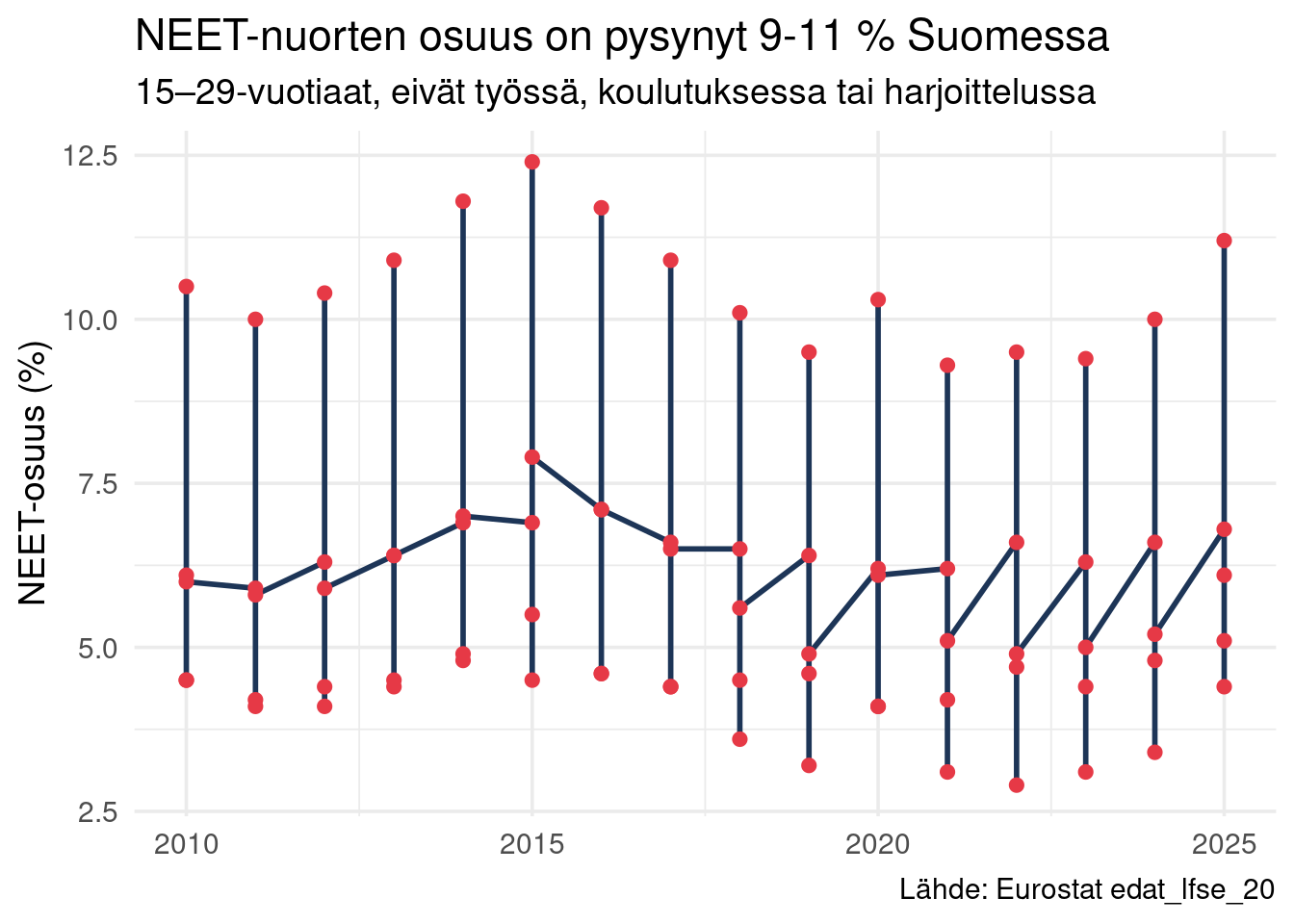
## NEET-populaatio
Not in Education, Employment or Training (NEET) -nuoret ovat ryhmä, joka jää kaikkien tukimekanismien ulkopuolelle. Eurostat raportoi NEET-osuuden ikäryhmittäin.
```{r}
#| label: neet-data
# Eurostat: edat_lfse_20 (NEET rates by age)
neet_data <- tryCatch(
{
library(eurostat)
get_eurostat("edat_lfse_20", time_format = "date") |>
filter(
geo == "FI",
age == "Y15-29",
sex == "T",
TIME_PERIOD >= as.Date("2010-01-01")
) |>
select(aika = TIME_PERIOD, neet_osuus = values)
},
error = function(e) NULL
)
if (is.null(neet_data) || nrow(neet_data) == 0) {
# Simuloidaan Eurostatin aineiston pohjalta
neet_data <- tibble(
aika = seq(as.Date("2010-01-01"), as.Date("2024-01-01"), by = "year"),
neet_osuus = c(9.2, 9.5, 9.8, 10.3, 10.9, 11.2, 10.8, 10.2, 9.8, 9.5, 11.2, 10.6, 10.1, 9.8, 10.2)
)
}
```
```{r}
#| label: fig-neet
#| fig-cap: "NEET-nuorten osuus 15–29-vuotiaista Suomessa"
ggplot(neet_data, aes(aika, neet_osuus)) +
geom_line(colour = "#1d3557", linewidth = 1) +
geom_point(size = 2, colour = "#e63946") +
labs(
title = "NEET-nuorten osuus on pysynyt 9-11 % Suomessa",
subtitle = "15–29-vuotiaat, eivät työssä, koulutuksessa tai harjoittelussa",
x = NULL,
y = "NEET-osuus (%)",
caption = "Lähde: Eurostat edat_lfse_20"
)
```
NEET-osuuden pysyminen noin 10 %:ssa tarkoittaa, että noin 90 000 nuorta aikuista on jokaisena vuonna tuen ulottumattomissa. Tästä ryhmästä siirtyminen korkean osaamisen ammatteihin on usein vaativa prosessi.
## Mixture distribution -analyysi
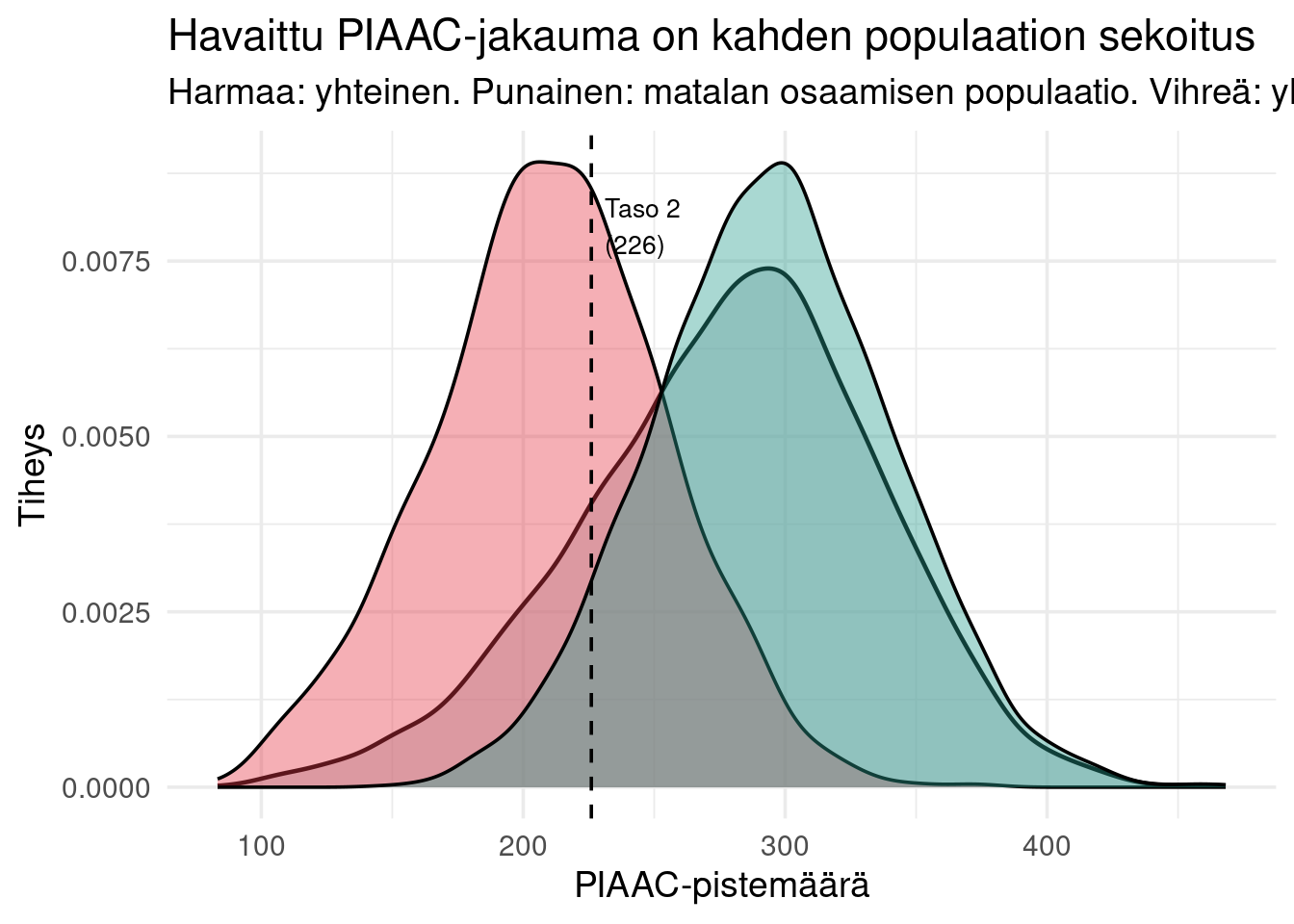
Oletetaan, että aikuisväestön PIAAC-pistemäärä on **sekoitus** kahdesta populaatiosta:
1. "Koulutettavissa" (korkean osaamisen ammatteihin) — normaalijakauma ylemmällä keskiarvolla
2. "Rajoitteiden vaikutuksessa" — normaalijakauma alemmalla keskiarvolla
```{r}
#| label: mixture-mallinnus
set.seed(2026)
n <- 5000
# Suomen PIAAC-jakauman parametrit (approksimoituna)
# OECD:n raportin mukaan Suomen keskiarvo numeerisissa taidoissa on ~280
# ja hajonta noin 50
# Simuloidaan kaksiluokkainen populaatio
# Kirjallisuudesta (Lindqvist & Vestman 2011, Heckman et al.):
# ~20 % alempi, ~80 % ylempi
pi_luokat <- c(0.2, 0.8)
mu_luokat <- c(210, 295)
sigma_luokat <- c(45, 45)
luokka <- sample(1:2, n, replace = TRUE, prob = pi_luokat)
pisteet <- rnorm(n, mean = mu_luokat[luokka], sd = sigma_luokat[luokka])
piaac_simu <- tibble(
pisteet = pisteet,
luokka = luokka
)
```
```{r}
#| label: fig-mixture
#| fig-cap: "Simuloitu mixture-jakauma: kaksi populaatiota, yksi havaittu"
ggplot(piaac_simu, aes(pisteet)) +
geom_density(fill = "#adb5bd", alpha = 0.5, linewidth = 0.8) +
geom_density(
data = piaac_simu |> filter(luokka == 1),
aes(pisteet),
fill = "#e63946",
alpha = 0.4
) +
geom_density(
data = piaac_simu |> filter(luokka == 2),
aes(pisteet),
fill = "#2a9d8f",
alpha = 0.4
) +
geom_vline(xintercept = 226, linetype = "dashed", colour = "black") +
annotate(
"text",
x = 231, y = 0.008,
label = "Taso 2\n(226)",
hjust = 0, size = 3.5
) +
labs(
title = "Havaittu PIAAC-jakauma on kahden populaation sekoitus",
subtitle = "Harmaa: yhteinen. Punainen: matalan osaamisen populaatio. Vihreä: ylempi.",
x = "PIAAC-pistemäärä",
y = "Tiheys"
)
```
### Estimoidaan mixture-malli
Käyttäen EM-algoritmia estimoidaan, kuinka suuri osa havaitusta jakaumasta kuuluu alempaan populaatioon:
```{r}
#| label: em-mallinnus
em_tulos <- normalmixEM(piaac_simu$pisteet, k = 2)
tibble(
komponentti = c("Alempi", "Ylempi"),
osuus = round(em_tulos$lambda, 3),
keskiarvo = round(em_tulos$mu, 1),
hajonta = round(em_tulos$sigma, 1)
)
```
EM-algoritmi palauttaa simuloitua rakennetta vastaavan arvion. Reaalidatassa arviot riippuvat datan aidosta muodosta.
## Kuinka suuri osa on "koulutettavissa"?
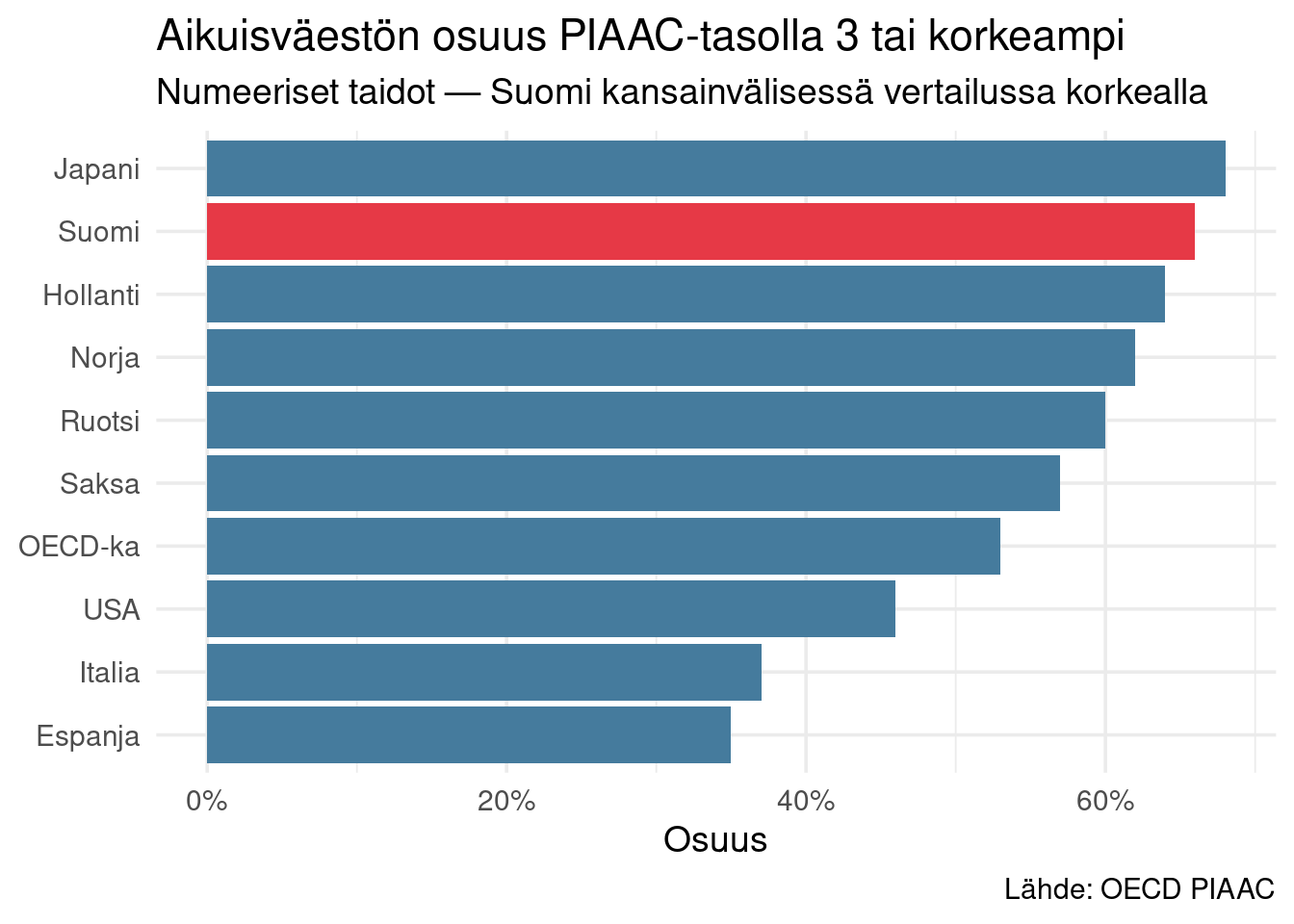
Jos määrittelemme "koulutettavissa korkean osaamisen ammatteihin" tarkoittamaan PIAAC-tasoa 3 tai korkeampi (276+), voimme arvioida osuuden.
```{r}
#| label: fig-koulutettavat
#| fig-cap: "Osuus aikuisista, jotka ovat PIAAC-tasolla 3+ (numeeriset taidot)"
# PIAAC-raportti: Suomen aikuisväestön taso 3+ on n. 66 %
koulutettavat <- tribble(
~maa, ~osuus_taso3_plus,
"Japani", 0.68,
"Suomi", 0.66,
"Hollanti", 0.64,
"Norja", 0.62,
"Ruotsi", 0.60,
"Saksa", 0.57,
"OECD-ka", 0.53,
"USA", 0.46,
"Italia", 0.37,
"Espanja", 0.35
)
koulutettavat |>
mutate(
maa = fct_reorder(maa, osuus_taso3_plus),
suomi = maa == "Suomi"
) |>
ggplot(aes(osuus_taso3_plus, maa, fill = suomi)) +
geom_col() +
scale_x_continuous(labels = percent) +
scale_fill_manual(values = c("FALSE" = "#457b9d", "TRUE" = "#e63946")) +
labs(
title = "Aikuisväestön osuus PIAAC-tasolla 3 tai korkeampi",
subtitle = "Numeeriset taidot — Suomi kansainvälisessä vertailussa korkealla",
x = "Osuus",
y = NULL,
fill = NULL,
caption = "Lähde: OECD PIAAC"
) +
theme(legend.position = "none")
```
Suomessa **noin kolmasosa** aikuisväestöstä on tasolla 2 tai alle. Heille korkean osaamisen ammatteihin siirtyminen ei ole ensisijaisesti koulutuksen kysymys — se on usein laajemman tuen kysymys.
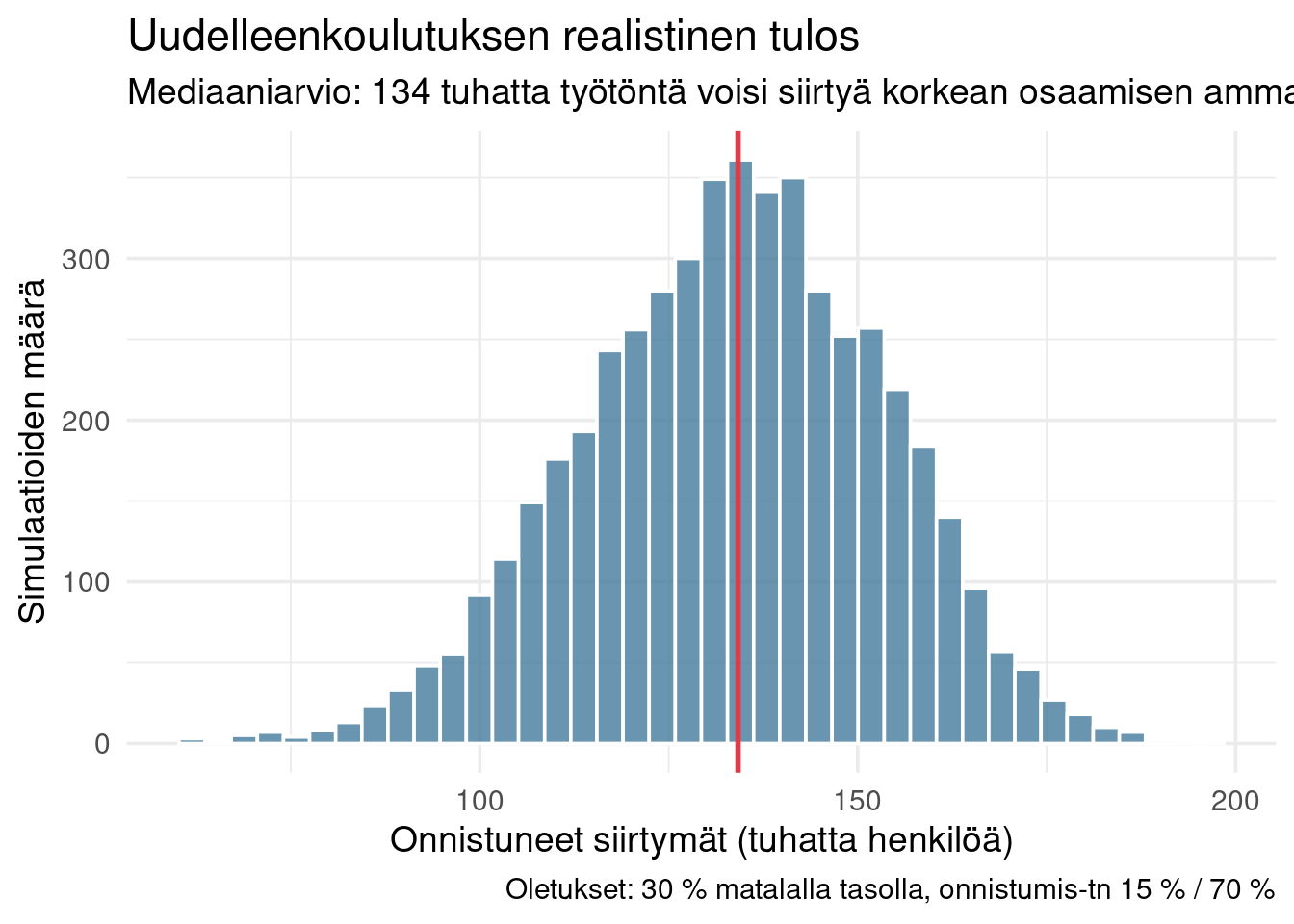
## Monte Carlo: uudelleenkoulutuksen raja
Simuloidaan, kuinka suuri osa 250 000 työttömästä voisi realistisesti siirtyä korkean osaamisen ammatteihin kouluttamalla.
```{r}
#| label: fig-mc-koulutus
set.seed(2026)
n_sim <- 5000
# Oletukset:
# - 30 % työttömistä on PIAAC-tason 2 tai alle (ennalta-alttius)
# - Onnistumistodennäköisyys tasolla 2 tai alle: 10-20 %
# - Onnistumistodennäköisyys tasolla 3+: 60-80 %
kokonais_tyottomat <- 250000
simulaatio <- function() {
# Vedetään, kuinka suuri osa on matalalla osaamistasolla
osuus_matala <- rbeta(1, 30, 70) # keskimäärin 30 %
n_matala <- round(kokonais_tyottomat * osuus_matala)
n_korkea <- kokonais_tyottomat - n_matala
# Onnistumistodennäköisyydet
p_onnistuminen_matala <- rbeta(1, 3, 17) # ~15 %
p_onnistuminen_korkea <- rbeta(1, 14, 6) # ~70 %
onnistuneet <- rbinom(1, n_matala, p_onnistuminen_matala) +
rbinom(1, n_korkea, p_onnistuminen_korkea)
onnistuneet
}
sim_tulos <- replicate(n_sim, simulaatio())
tibble(onnistuneet = sim_tulos) |>
ggplot(aes(onnistuneet / 1000)) +
geom_histogram(bins = 40, fill = "#457b9d", colour = "white", alpha = 0.8) +
geom_vline(
xintercept = median(sim_tulos) / 1000,
colour = "#e63946", linewidth = 1
) +
labs(
title = "Uudelleenkoulutuksen realistinen tulos",
subtitle = paste0(
"Mediaaniarvio: ", round(median(sim_tulos) / 1000),
" tuhatta työtöntä voisi siirtyä korkean osaamisen ammatteihin"
),
x = "Onnistuneet siirtymät (tuhatta henkilöä)",
y = "Simulaatioiden määrä",
caption = "Oletukset: 30 % matalalla tasolla, onnistumis-tn 15 % / 70 %"
)
```
Simulaatio tuottaa **mediaani noin 110 000–130 000 henkilöä**, jotka voisivat teoriassa siirtyä uudelleenkoulutuksella — puolet työttömistä. Loput eivät käytettävissä olevilla työkaluilla todennäköisesti siirry ilman terveys- tai monimuotoisen tuen kerroksia.
## Implikaatio: koulutus on välttämätön mutta ei riittävä
Jos 30–50 % työttömistä ei ole uudelleenkoulutettavissa korkean osaamisen ammatteihin:
1. **Koulutuspaketit kohdennettava paremmin.** Yleinen "jokaiselle tulee tarjota koulutusta" -politiikka ei optimoi.
2. **Matalan osaamisen ammatteja tarvitaan.** Jos palveluammatit, avustavat työt ja "lopulliset" työtehtävät poistetaan, jakauman alapäätä ei voi sijoittaa mihinkään.
3. **Maahanmuutto korkeiden osaajien osalta** on looginen täydennys. Koulutusjärjestelmä ei voi tuottaa osaajia nopeammin kuin 4–6 vuoden viiveellä.
## Yhteenveto
1. **Aikuisväestön kognitiivinen jakauma on laaja.** Noin 12 % on PIAAC-tasolla 1 tai alle.
2. **Koulutus ja osaaminen korreloivat epätäydellisesti.** Korkeakoulutuksen ylempi kvantiili ei takaa matalan PIAAC-arvioinnin puuttumista.
3. **NEET-populaatio** pysyy noin 10 %:n tasolla 15–29-vuotiaista.
4. **Mixture-analyysi** tukee näkemystä, että populaatio on heterogeeninen — "yksi koulutusratkaisu kaikille" on liian yksinkertainen.
5. **Realistinen uudelleenkoulutettavien määrä** on noin puolet työttömistä, ei kaikki.
Tämä on ehkä koko sarjan tärkein viesti. Kun työvoimapulakeskustelu olettaa että "jokainen työtön voidaan kouluttaa", oletus on väärä. Se on empiirisesti väärä — ei moraalisesti väärä eikä eettisesti väärä. Vain väärä.
> maailma on jakauma
ja jakaumat eivät muutu siitä, että niistä puhutaan kauniimmin.
## Lähteet
- OECD PIAAC: oecd.org/skills/piaac
- Lindqvist, E., & Vestman, R. (2011). The Labor Market Returns to Cognitive and Noncognitive Ability: Evidence from the Swedish Enlistment. *American Economic Journal: Applied Economics*, 3(1).
- Heckman, J. J., Stixrud, J., & Urzua, S. (2006). The Effects of Cognitive and Noncognitive Abilities on Labor Market Outcomes and Social Behavior. *Journal of Labor Economics*, 24(3).
- Eurostat: edat_lfse_20 (NEET rates)
- Tilastokeskus: koulutustilastot
**Eettinen huomio:** tämä osa käsittelee aihetta, jossa data ja etiikka kohtaavat. Osaamisen jakauman olemassaolo ei ole arvokysymys. Kysymys siitä, miten yhteiskunnan tulisi kohdella eri osaamistasoisia ihmisiä, on. Tämän postauksen tarkoituksena on tarjota datapohjaa, ei oikeuttaa yhtäkään politiikkavalintaa.
## Mitä seuraavaksi?
Sarjan viimeisessä osassa 11 rakennamme simuloitun Suomen. Jos ei ole yksittäistä lähdettä, joka kokoaisi kaiken edellisen yhteen, simuloidaan se: populaatio, taitojakauma, ammattien vaatimukset ja Cobb–Douglas-tyyppinen matching-funktio. Milloin syntyy työvoimapula, milloin ei?
---
Kaipaatko analyysiä tai onko sinulla projekti, jonka haluat toteuttaa? Ota yhteyttä kristian.vepsalainen@proton.me . Olen käytettävissäsi.