---
title: "Kun merikotka saa henkilötietosuojaa — ja mitä oikeasta tietosuojasta voisi oppia"
subtitle: "Differentiaalinen yksityisyys ja bayeslainen anonymisointi selitettynä"
description: |
Suomen pelastuslaitos kieltäytyi kertomasta merikotkan pelastamisesta vedoten henkilötietolakiin — lakiin, joka koskee vain ihmisiä, ei eläimiä. Tapaus on hauska, mutta se paljastaa jotain vakavaa: emme osaa puhua julkisessa hallinnossa tietosuojasta täsmällisesti. Tässä postauksessa näytän, miten tietosuoja todella toimii — jakaumien, ei kieltojen kautta.
author: "Kristian Vepsäläinen"
date: 2026-06-12
categories:
- tietosuoja
- bayeslaiset menetelmät
- avoimen datan analytiikka
- differentiaalinen yksityisyys
image: "thumbnail.png"
format:
html:
code-fold: true
code-summary: "Näytä koodi"
toc: true
toc-depth: 3
execute:
echo: true
warning: false
message: false
cache: true
---
```{r setup}
#| include: false
library(tidyverse)
library(ggplot2)
library(patchwork)
set.seed(42)
# Väripaletti
col_red <- "#e63946"
col_teal <- "#2a9d8f"
col_orange <- "#f4a261"
col_navy <- "#1d3557"
col_blue <- "#457b9d"
theme_kv <- function() {
theme_minimal(base_size = 13) +
theme(
plot.background = element_rect(fill = "#0d1117", color = NA),
panel.background = element_rect(fill = "#0d1117", color = NA),
text = element_text(color = "#e8e8e8"),
axis.text = element_text(color = "#c0c0c0"),
panel.grid.major = element_line(color = "#2a2a3a"),
panel.grid.minor = element_blank(),
plot.title = element_text(size = 15, face = "bold", color = "#e8e8e8"),
plot.subtitle = element_text(size = 11, color = "#a0a0b0"),
legend.background = element_rect(fill = "#0d1117", color = NA),
legend.text = element_text(color = "#e8e8e8")
)
}
```
## Tapaus: merikotka, automaattisalaus ja algoritmi joka ei osaa lukea lakia
Toukokuussa 2026 merikotka törmäsi tuulivoimalaan Kalajoella ja menetti osan siivestään. Pelastuslaitos kävi paikalla. Helsingin Sanomat pyysi nähtäväkseen tapauksen onnettomuusselosteen eli teki aivan normaalin viranomaistietopyynnön, sillä Suomessa viranomaisasiakirjat ovat julkisuuslain mukaan lähtökohtaisesti julkisia.
Seloste saapui. Keskeiset kohdat, kuten onnettomuuden kulku ja pelastuslaitoksen toiminta, oli mustattu. Salausta perusteltiin viittaamalla Pelastuslakiin (379/2011) 86 §:ään, Henkilötietolakiin (523/1999) 11 §:ään ja Julkisuuslakiin (621/1999) 24 §:ään.
Asianosaisena oli merikotka eli *Haliaeetus albicilla.* Henkilötietolaki koskee luonnollisia henkilöitä, ei lintuja.
Pohjois-Pohjanmaan pelastuslaitoksen johto myöntää virheellisen salauksen. Kehityspäällikkö Matti Virtanen selittää: taustalla on Pelastusopiston kehittämä **Pronto-järjestelmä**, joka on mustanut onnettomuusselosteista aina samat kohdat automaattisesti, riippumatta siitä, onko kussakin tapauksessa yhtään salattavaa. "Automaatin mukaan mennään", Virtanen tiivistää. "Voihan siellä olla sitten tilanne, että siellä ei olekaan mitään salattavaa."
Hallinto-oikeuden emeritusprofessori **Olli Mäenpää** pitää tilannetta suoraan lainvastaisena: "Ei ole mitään yleistä ehdotonta salassapitoperustetta, jonka perusteella voisi kaikki tiedot automaattisesti salata, vaan ne pitää arvioida tieto kerrallaan."
Pronto korvataan tänä vuonna uudella Kivijalka-järjestelmällä. Vanhaa järjestelmää ei Virtasen mukaan aiottu kehittää tähän suuntaan, mutta sitä ei myöskään kehitetty pois tästä suunnasta.
---
Tämä tapaus on hauska. Mutta se ei ole vain koominen väärinkäsitys; se on **oire algoritmisesta päätöksenteosta ilman ihmisarviointia**. Järjestelmä tekee salauksia, koska se on ohjelmoitu tekemään salauksia. Kukaan ei tarkista, onko salaukselle perustetta. Tulos: merikotka saa henkilötietosuojaa.
Nyt tulee se kiinnostava kysymys: **jos laki velvoittaa arvioimaan jokaisen salauksen erikseen, miten se tehtäisiin oikein?** Ja mitä teknisiä menetelmiä oikeaan tietosuojaan ylipäätään on, kun asianosaisena on ihminen eikä kotka?
Tässä kirjoituksessa näytän, miten **moderni tietosuoja oikeasti toimii** juuri tässä kontekstissa: yksittäisessä onnettomuusselosteessa, jossa voi olla sensitiivisiä tekstikenttiä kuten osoitteita tai nimiä. Käyn läpi kaksi menetelmää ja demonstroin ne koodilla: ensin **NLP-pohjaisen sensitiivisyysluokittelun**, jolla kone tunnistaa, mikä teksti vaatii salauksen, ja sitten **differentiaalisen yksityisyyden**, jolla pelastuslaitoksen tilastot voidaan julkaista turvallisesti.
Loppuun vedän yhteen sen, mitä Pronto-järjestelmän voisi korvata. ei automaattisalauksen, vaan **automaattisen arvioinnin**, jossa kone tunnistaa sensitiivisyyden ja salaus kohdistuu juuri oikeaan kohtaan.
---
## Automaattisalaus on algoritminen päätös ilman arviointia ja miksi se on ongelma
Pronto-järjestelmän logiikka on ymmärrettävä insinööriratkaisuna: salauksen automatisointi säästää aikaa. Mutta oikeudellisesti se on väärässä lähtökohdassa. Julkisuuslaki lähtee avoimuusolettamasta — salaus on poikkeus, joka vaatii perusteen. Kun järjestelmä automaattisesti mustaa samat kentät jokaisessa selosteessa, se kääntää tämän logiikan nurinpäin: salaus on oletus, avoimuus on poikkeus.
Tämä on tuttu ongelma koneoppimisessa ja algoritmisessa päätöksenteossa yleisemmin. **Algoritmi optimoi sen, mitä se on opetettu optimoimaan.** Jos Pronto on rakennettu niin, että salaus on turvallinen oletusasetus, se tuottaa ylisalauksia eli salaa tämän esimerkkimme kotkatapauksen.
Moderni tietosuojateoria lähtee aivan toisesta suunnasta. Keskeinen kysymys ei ole "salaako vai ei?" vaan **"miten paljon lisätietoa tämä julkaisu antaa yksittäisestä henkilöstä verrattuna siihen, mitä ulkopuolinen jo tietää?"**
Tähän kysymykseen voi vastata matemaattisesti ja sen perusteella tehdä perusteltu päätös tapauskohtaisesti.
---
## Differentiaalinen yksityisyys: matemaattinen tietosuoja
### Idea lyhyesti
Differentiaalinen yksityisyys (DP) on vuonna 2006 Cynthia Dworkin ym. kehittämä tietosuojamenetelmä, jolla on tiukka matemaattinen takuu. Se toimii lisäämällä dataan harkittua kohinaa niin, että **yksittäistä henkilöä koskeva johtopäätös ei ole tilastollisesti mahdollinen** tietyn tarkkuuden yli.
Muodollisesti: algoritmi $\mathcal{M}$ on $\varepsilon$-differentially private, jos kaikille kahdelle tietokannalle $D$ ja $D'$, jotka eroavat yhdellä rivillä, ja kaikille tuloksille $S$:
$$\Pr[\mathcal{M}(D) \in S] \leq e^\varepsilon \cdot \Pr[\mathcal{M}(D') \in S]$$
Parametri $\varepsilon$ (epsilon) on **yksityisyysbudjetti**. Pieni $\varepsilon$ = tiukka suoja, enemmän kohinaa. Suuri $\varepsilon$ = löysempi suoja, tarkempi data.
### Miksi tämä on tärkeää
Ilman DP:tä pelkkä "anonymisointi" eli esimerkiksi nimien poistaminen tai aggregointi, ei suojaa. On hyvin dokumentoitua, että pienistä tilastoista voi "re-identifioida" henkilöitä, kun yhdistää useita datalähteitä. DP estää tämän matemaattisesti.
### Konkreetti esimerkki: Laplace-kohina
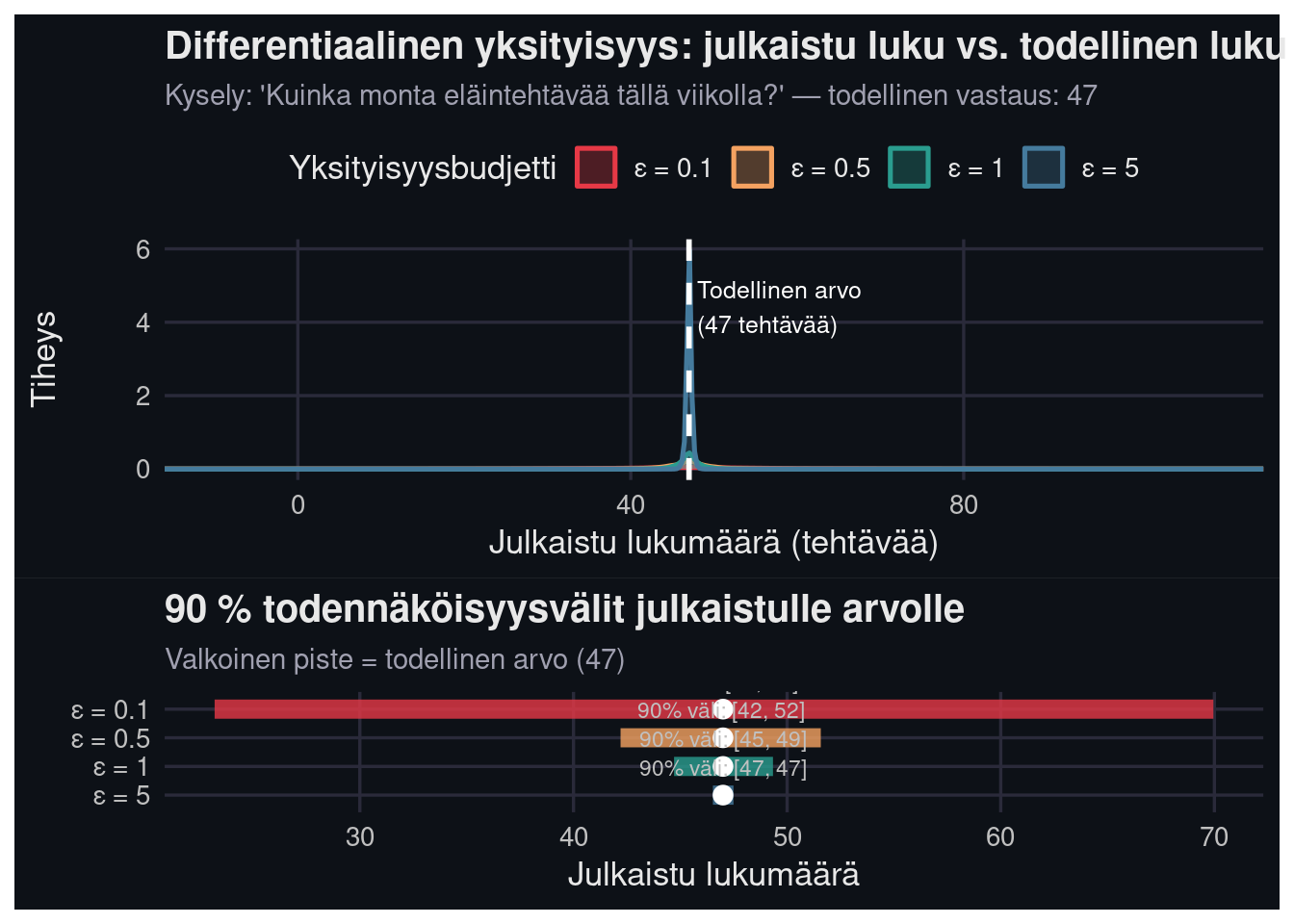
Yksinkertaisin DP-mekanismi on lisätä Laplace-jakaumasta vedettyä kohinaa. Jos haluamme julkaista kyselyn herkkyydellä $\Delta f$ yksityisyysbudjetilla $\varepsilon$, lisäämme kohinaa skaalalla $b = \Delta f / \varepsilon$.
```{r dp-laplace}
#| fig-cap: "Differentiaalinen yksityisyys käytännössä: sama kysely eri yksityisyysbudjeteilla"
#| fig-height: 5
# Esimerkki: "Kuinka monta eläintehtävää tällä viikolla?"
# Todellinen vastaus: 47 tehtävää
# Count-kyselyn herkkyys = 1 (yksi rivi voi muuttaa vastausta yhdellä)
true_count <- 47
sensitivity <- 1 # count query: aina 1
# Laplace-mekanismi: lisätään kohinaa skaalalla b = sensitivity / epsilon
laplace_noise <- function(sensitivity, epsilon, n = 1) {
b <- sensitivity / epsilon
u <- runif(n, -0.5, 0.5)
-b * sign(u) * log(1 - 2 * abs(u))
}
epsilons <- c(0.1, 0.5, 1.0, 5.0)
n_sims <- 8000
dp_results <- map_dfr(epsilons, function(eps) {
noisy_estimates <- true_count + laplace_noise(sensitivity, eps, n = n_sims)
tibble(
epsilon = eps,
estimate = noisy_estimates,
eps_label = paste0("ε = ", eps)
)
})
stopifnot(nrow(dp_results) == length(epsilons) * n_sims)
stopifnot(all(c("epsilon", "estimate", "eps_label") %in% names(dp_results)))
dp_results <- dp_results |>
mutate(eps_label = factor(eps_label,
levels = paste0("ε = ", sort(epsilons))))
# Lasketaan 90%-välit per epsilon näytettäväksi
dp_intervals <- dp_results |>
group_by(eps_label, epsilon) |>
summarise(
lo = quantile(estimate, 0.05),
hi = quantile(estimate, 0.95),
.groups = "drop"
) |>
mutate(label = sprintf("90%% väli: [%.0f, %.0f]", lo, hi))
# Pääkuvaaja: jakaumat
p_main <- ggplot(dp_results,
aes(x = estimate, fill = eps_label, color = eps_label)) +
geom_density(alpha = 0.30, linewidth = 0.9) +
geom_vline(xintercept = true_count, linetype = "dashed",
color = "white", linewidth = 1.0) +
annotate("text", x = true_count + 1, y = Inf,
label = paste0("Todellinen arvo\n(", true_count, " tehtävää)"),
vjust = 1.8, hjust = 0, color = "white", size = 3.3) +
scale_fill_manual(values = c(col_red, col_orange, col_teal, col_blue),
name = "Yksityisyysbudjetti") +
scale_color_manual(values = c(col_red, col_orange, col_teal, col_blue),
name = "Yksityisyysbudjetti") +
coord_cartesian(xlim = c(-10, 110)) +
labs(
title = "Differentiaalinen yksityisyys: julkaistu luku vs. todellinen luku",
subtitle = "Kysely: 'Kuinka monta eläintehtävää tällä viikolla?' — todellinen vastaus: 47",
x = "Julkaistu lukumäärä (tehtävää)",
y = "Tiheys"
) +
theme_kv() +
theme(legend.position = "top")
# Alataulukko: 90%-välit selkeyttämään eroa
p_intervals <- ggplot(dp_intervals,
aes(x = lo, xend = hi,
y = reorder(eps_label, -epsilon),
yend = reorder(eps_label, -epsilon),
color = eps_label)) +
geom_segment(linewidth = 3.5, alpha = 0.8) +
geom_point(aes(x = true_count), color = "white",
size = 3, shape = 21, fill = "white") +
geom_text(aes(x = (lo + hi) / 2, label = label),
vjust = -1.2, size = 3.0, color = "#c0c0c0") +
scale_color_manual(values = c(col_red, col_orange, col_teal, col_blue),
guide = "none") +
labs(
title = "90 % todennäköisyysvälit julkaistulle arvolle",
subtitle = "Valkoinen piste = todellinen arvo (47)",
x = "Julkaistu lukumäärä",
y = NULL
) +
theme_kv()
p_main / p_intervals + plot_layout(heights = c(2, 1))
```
Kuviossa näkyy selkeästi yksityisyyden ja tarkkuuden välinen jännitys eli **jakauma**. Ei ole olemassa yhtä "oikeaa" vastausta siihen, paljonko kohinaa lisätään; on olemassa *valintatilanne*, jossa eri arvot johtavat eri riskiprofiileihin.
Tämä on "maailma on jakauma" -periaate tietosuojaan sovellettuna: yksityisyys ei ole kytkintä. Se on parametri, jonka arvo valitaan tietoisesti.
---
## Menetelmä 2: NLP-pohjainen sensitiivisyysluokittelu — kohdista salaus oikeaan paikkaan
### Ongelma: Pronto mustaa liikaa
Pronton automaattilogiikka mustaa kenttiä rakenteen perusteella; "tässä kentässä *saattaa* olla henkilötieto". Se on sama kuin sanoa: "tässä kirjekuoressa *saattaa* olla salainen asiakirja, joten mustaamme sen varmuuden vuoksi." Oikeaoppinen tietosuoja toimii toisin: ensin arvioidaan, onko sensitiivistä tietoa, sitten päätetään toimenpiteestä.
Tähän tehtävään sopii **nimettyjen entiteettien tunnistus** (Named Entity Recognition, NER). Se on yksi luonnollisen kielen käsittelyn perusmenetelmiä. Se tunnistaa tekstistä henkilönimet, organisaatiot, osoitteet ja muut vastaavat tunnistetiedot.
### Idea simuloituna
Alla simuloin kuvitteellisia onnettomuusselosteen tekstikatkelmia ja lasken niille sensitiivisyyspisteet. Oikeassa järjestelmässä käytettäisiin esimerkiksi Spacy- tai Hugging Face -kirjastoja; tässä simuloin tuloksen R:ssä säännöllisillä lausekkeilla, jotka edustavat samaa logiikkaa.
```{r nlp-luokittelu}
#| fig-cap: "NLP-sensitiivisyysluokittelu: mitkä tekstikentät tarvitsevat salauksen?"
#| fig-height: 5
selosteet <- tibble(
id = 1:12,
kentta = c(
rep("Kuvaus onnettomuuden kulusta", 4),
rep("Selvitys pelastuslaitoksen toiminnasta", 4),
rep("Muut tiedot", 4)
),
teksti = c(
"Maastossa kulkija oli havainnut merikotkan liikkuvan maassa, eikä se ollut lähtenyt lentoon.",
"Asukas Matti Virtanen, s. 12.3.1975, soitti hätänumeroon klo 14:23 kertoakseen löytäneensä haavoittuneen linnun.",
"Kohteessa Metsätie 4, 85100 Kalajoki havaittu lintuvahinkopaikka tuulivoimalan juurella.",
"Yksikkö P231 saapui kohteeseen 8 minuutin kuluttua hälytyksestä. Kotka oli loukkaantunut siipeen.",
"Lintua yritetty saada kiinni, mutta se ei onnistu. Jätettiin metsään, JoKe ilmoittaa eteenpäin.",
"Pelastusryhmä koostui kahdesta henkilöstä. Varustuksena eläintensiirtolaatikko ja suojakäsineet.",
"Potilaan nimi: Hanna Korhonen, hetu 150489-XXXX. Erillinen tehtävä samana päivänä.",
"Toiminta-aika kohteessa 23 minuuttia. Kotka evakuoitiin Keski-Pohjanmaan luontokeskukseen.",
"Sää: puolipilvinen, tuuli 6 m/s lounaasta. Näkyvyys hyvä.",
"Yhteystiedot: pelastuspäällikkö Juha Mäkinen, p. 040-123 4567.",
"Tapaukseen ei liity henkilövahinkoja. Merikotka on rauhoitettu laji (lsl 42 §).",
"Tehtävä kirjattu numerolla 2026-05-1847. Ei jatkotoimenpiteitä."
)
)
# Sensitiivisyyspisteytys: simuloi NER-mallin tunnistusta
laske_sensitiivisyys <- function(teksti) {
pisteet <- 0L
# Henkilötunnus tai syntymäaika
if (grepl("\\d{6}[-+A]\\d{3}[A-Z0-9]|s\\.\\s*\\d{1,2}\\.\\d{1,2}\\.\\d{4}", teksti))
pisteet <- pisteet + 40L
# Puhelinnumero
if (grepl("\\d{3}[-\\s]\\d{3,4}\\s\\d{4}|04\\d[-\\s]\\d{3}", teksti))
pisteet <- pisteet + 25L
# Osoite
if (grepl("\\b\\d{5}\\b|[A-ZÄÖÅ][a-zäöå]+(tie|katu|väylä)\\s+\\d", teksti))
pisteet <- pisteet + 20L
# Henkilönimi (kaksi isolla alkavaa sanaa — ei organisaatioita)
if (grepl("\\b[A-ZÄÖÅ][a-zäöå]+\\s+[A-ZÄÖÅ][a-zäöå]+\\b", teksti) &&
!grepl("^(Pelastus|Pohjois|Keski|Länsi|Itä|Etelä|Merikotka)", teksti))
pisteet <- pisteet + 15L
min(as.integer(pisteet), 100L)
}
selosteet <- selosteet |>
mutate(
sensitiivisyys = map_int(teksti, laske_sensitiivisyys),
suositellaan_salaus = sensitiivisyys >= 20L,
sensitiivisyys_lk = case_when(
sensitiivisyys == 0L ~ "Ei sensitiivinen",
sensitiivisyys < 20L ~ "Matala",
sensitiivisyys < 50L ~ "Kohtalainen",
TRUE ~ "Korkea"
) |> factor(levels = c("Ei sensitiivinen", "Matala", "Kohtalainen", "Korkea"))
)
stopifnot(nrow(selosteet) == 12L)
stopifnot(all(selosteet$sensitiivisyys >= 0L & selosteet$sensitiivisyys <= 100L))
n_salattavia <- sum(selosteet$suositellaan_salaus)
ggplot(selosteet,
aes(x = sensitiivisyys,
y = reorder(paste0("Rivi ", id, ": ", str_trunc(teksti, 48)),
sensitiivisyys),
fill = sensitiivisyys_lk)) +
geom_col(width = 0.7) +
geom_vline(xintercept = 20, linetype = "dashed",
color = col_orange, linewidth = 0.9) +
annotate("text", x = 22, y = 0.7,
label = "Salausraja", hjust = 0,
color = col_orange, size = 3.2) +
scale_fill_manual(
values = c("Ei sensitiivinen" = col_teal,
"Matala" = col_blue,
"Kohtalainen" = col_orange,
"Korkea" = col_red),
name = "Sensitiivisyysluokka"
) +
labs(
title = "NLP-sensitiivisyysluokittelu: mitkä rivit tarvitsevat salauksen?",
subtitle = paste0(n_salattavia, "/", nrow(selosteet),
" rivistä ylittää salausrajan — loput julkaistaan sellaisenaan"),
x = "Sensitiivisyyspisteet (0–100)",
y = NULL
) +
theme_kv() +
theme(axis.text.y = element_text(size = 8))
```
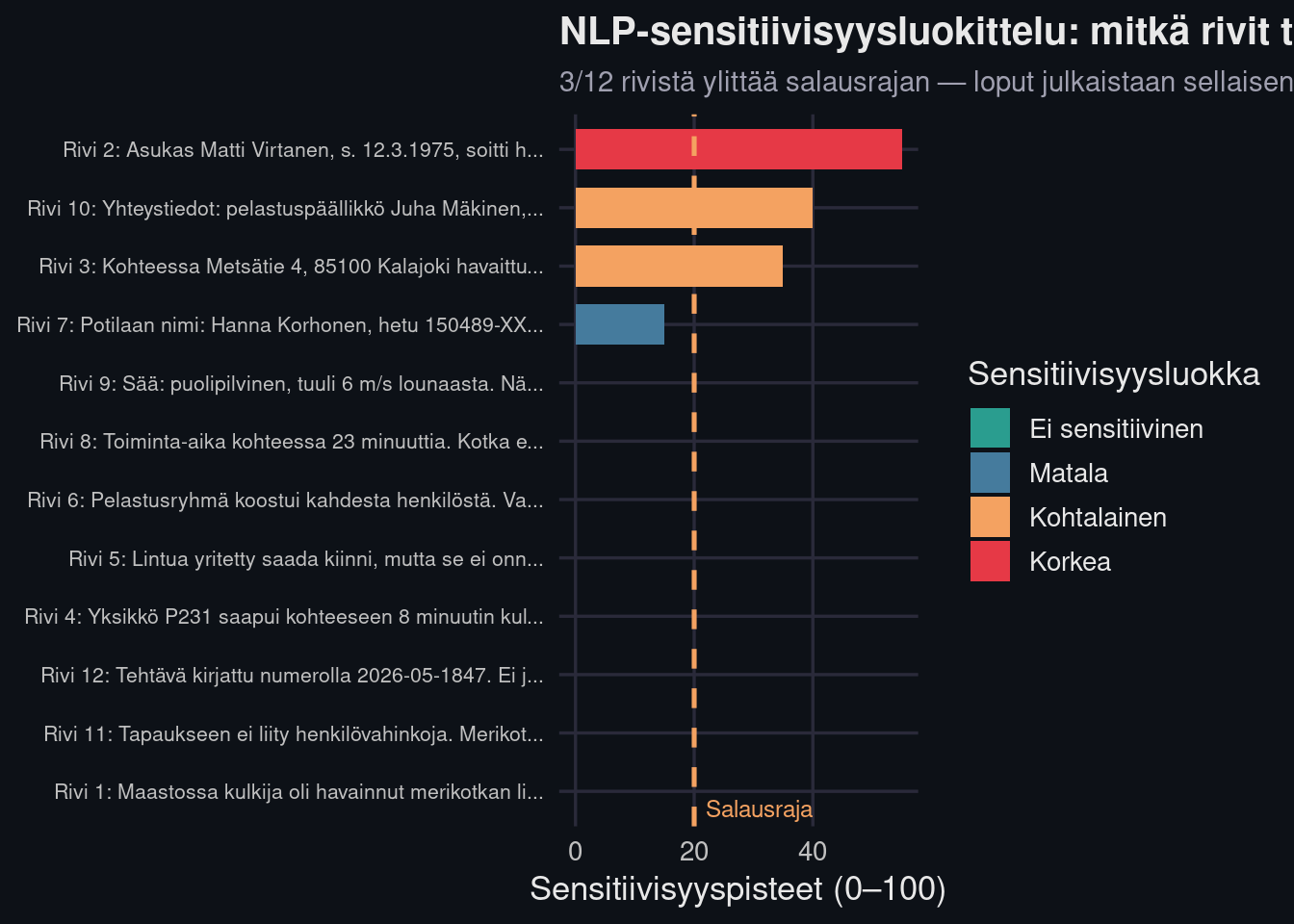
Tässä on avainero Pronton logiikkaan: järjestelmä ei mustaa kenttää rakenteen takia, vaan **sisällön** takia. Merikotkan pelastustehtävässä kuvauskenttä "Maastossa kulkija havaitsi merikotkan liikkuvan maassa" saa pisteet 0. Toisin sanoen ei henkilötietoja, ei salaustarvetta. Mutta rivi, jossa mainitaan henkilötunnus tai puhelinnumero saa pisteet 40–65 ja ohjataan automaattisesti salaukseen tai ihmisarvioon.
Pronto mustasi kaiken. NER mustaa vain sen mikä ansaitsee mustauksen.
---
## Menetelmä 3: Differentiaalinen yksityisyys pelastuslaitoksen tilastoihin
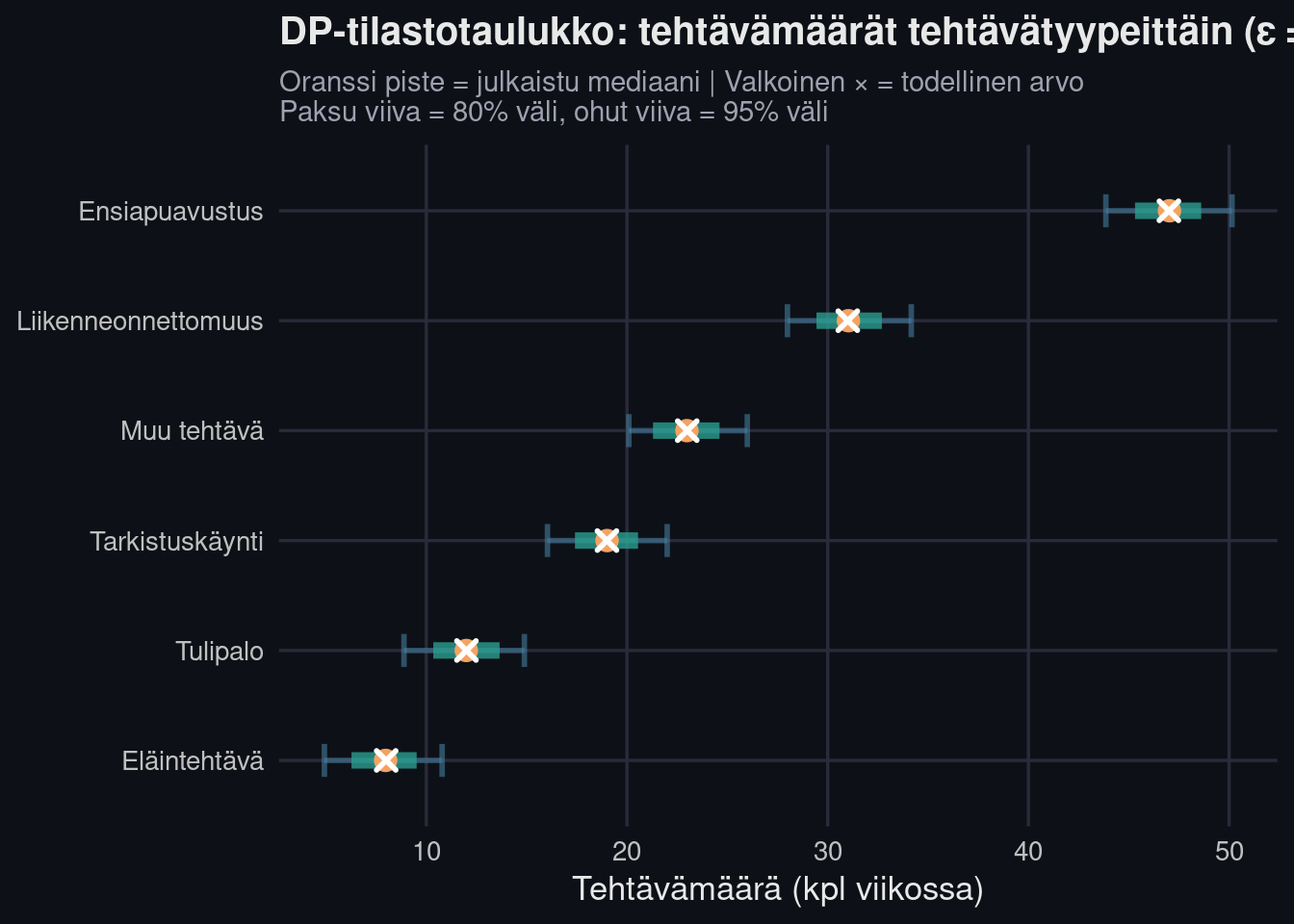
DP ei sovi yksittäisen onnettomuusselosteen salaamiseen. Se on tarkoitettu tilanteeseen, jossa **julkaistaan aggregoituja tilastoja** isolle joukolle tapauksia. Pelastuslaitos julkaisee vuosiraportteja, tehtävätilastoja, vasteaikoja. Juuri näissä DP loistaa.
Edellisessä osiossa demonstroin Laplace-mekanismin yksinkertaisella count-kyselyllä. Laajennetaan nyt esimerkki **useampaan samanaikaiseen kyselyyn** — mikä on realistisempi tilanne: pelastuslaitos haluaa julkaista tehtävätyypeittäin eritellyn viikkotaulukon.
```{r dp-monitaulukko}
#| fig-cap: "DP useammalle kyselylle samanaikaisesti: epävarmuus kasvaa pienillä tehtävätyypeillä"
#| fig-height: 5
tosi_arvot <- c(
"Tulipalo" = 12,
"Liikenneonnettomuus" = 31,
"Eläintehtävä" = 8,
"Ensiapuavustus" = 47,
"Tarkistuskäynti" = 19,
"Muu tehtävä" = 23
)
epsilon_total <- 1.0 # rinnakkaisella koostumuksella sama budjetti riittää kaikille
set.seed(42)
n_sims <- 3000
sim_results <- map_dfr(names(tosi_arvot), function(tyyppi) {
tosi <- tosi_arvot[tyyppi]
noisy <- tosi + laplace_noise(sensitivity = 1, epsilon = epsilon_total, n = n_sims)
tibble(tyyppi = tyyppi, tosi_arvo = tosi, julkaistu = noisy)
})
stopifnot(nrow(sim_results) == length(tosi_arvot) * n_sims)
dp_summary <- sim_results |>
group_by(tyyppi, tosi_arvo) |>
summarise(
med = median(julkaistu),
lo80 = quantile(julkaistu, 0.10),
hi80 = quantile(julkaistu, 0.90),
lo95 = quantile(julkaistu, 0.025),
hi95 = quantile(julkaistu, 0.975),
.groups = "drop"
)
stopifnot(all(dp_summary$lo80 < dp_summary$hi80))
ggplot(dp_summary, aes(y = reorder(tyyppi, tosi_arvo))) +
geom_errorbar(aes(xmin = lo95, xmax = hi95),
orientation = "y",
width = 0.3, color = col_blue, linewidth = 1.0, alpha = 0.6) +
geom_errorbar(aes(xmin = lo80, xmax = hi80),
orientation = "y",
width = 0, color = col_teal, linewidth = 3.0, alpha = 0.8) +
geom_point(aes(x = med), color = col_orange, size = 3.5) +
geom_point(aes(x = tosi_arvo), color = "white", size = 2.5,
shape = 4, stroke = 1.5) +
labs(
title = "DP-tilastotaulukko: tehtävämäärät tehtävätyypeittäin (ε = 1.0)",
subtitle = "Oranssi piste = julkaistu mediaani | Valkoinen × = todellinen arvo\nPaksu viiva = 80% väli, ohut viiva = 95% väli",
x = "Tehtävämäärä (kpl viikossa)",
y = NULL
) +
theme_kv()
```
Huomaa tärkeä havainto: **eläintehtäviä on 8 — julkaistu arvo heiluu eniten.** Ensiapuavustuksia on 47 — jakauma on suhteellisesti kapeampi. Tämä on matemaattisesti oikein: pienistä luvuista yksittäinen havainto on suhteellisesti merkittävämpi, joten DP:n antama suoja on samalla enemmän "tarpeen" ja samalla enemmän "näkyvissä" epävarmuutena.
---
## Yhteenveto menetelmistä
```{r vertailutaulukko}
#| echo: false
vertailu <- tibble(
Menetelmä = c(
"Pronto: automaattisalaus rakenteen perusteella",
"NLP / NER -sensitiivisyysluokittelu",
"Differentiaalinen yksityisyys (tilastot)",
"Ihmisarvio (korkean riskin tapaukset)"
),
`Sopii yksittäiseen selosteeseen` = c("Kyllä (mutta ylisalaa)", "Kyllä", "Ei", "Kyllä"),
`Sopii tilastojulkaisuun` = c("Ei", "Ei tarpeen", "Kyllä", "Liian hidas"),
`Matemaattinen tae` = c("Ei ole", "Ei ole", "Vahva (ε-DP)", "Ei mitattavissa"),
`Kohdistuu sisältöön` = c("Ei", "Kyllä", "Kyllä", "Kyllä"),
`Suositus` = c("Ei", "Kyllä selosteisiin", "Kyllä tilastoihin", "Kyllä epäselviin tapauksiin")
)
knitr::kable(vertailu, caption = "Menetelmien vertailu pelastuslaitoksen kontekstissa")
```
---
## Takaisin merikotkaan ja Pronton seuraajaan
Merikotkan tapauksessa kumpikaan menetelmistä ei ollut tarpeen: lintu ei ole luonnollinen henkilö, selosteessa ei ole suojattavaa tietoa, ja julkisuuslaki edellyttäisi avointa julkaisua. Järjestelmä silti mustasi.
Mutta nyt on oikea hetki kysyä: rakennetaanko uusi järjestelmä samalla logiikalla, automaattisalaus oletuksena, vai voisiko lähestymistapa olla erilainen?
Datatieteellinen vaihtoehto olisi kääntää logiikka: **automaattinen avoimuus oletuksena, salaus poikkeuksena, joka vaatii lasketun perusteen.**
Käytännössä tämä voisi toimia näin:
**Vaihe 1: Luokittelualgoritmi arvioi sensitiivisyyden.** Tekstinlouhinta tai kielimalli tunnistaa, sisältääkö seloste tunnistetietoja (nimet, osoitteet, sosiaaliturvatunnukset, terveystiedot). Eläintapauksessa malli palauttaisi: "ei henkilötietoja havaittu."
**Vaihe 2: Differentiaalinen yksityisyys suojaa aggregaatit.** Jos tapaukseen liittyy henkilötietoja, niitä sisältävät kentät suojataan DP:llä ennen julkaisua; ei mustauksella, joka estää kaiken hyödyntämisen, vaan kohinalla, joka mahdollistaa tilastollisen käytön.
**Vaihe 3: Bayeslainen arviointimalli tuottaa julkaisusuosituksen.** Jokainen seloste saa posterioritodennäköisyyden: kuinka todennäköisesti tämä sisältää lain edellyttämää salattavaa? Matalan todennäköisyyden tapaukset julkaistaan automaattisesti; korkean todennäköisyyden tapaukset menee ihmisarvioon.
Tämä ei ole utopia, sillä vastaavia järjestelmiä käytetään esimerkiksi Yhdysvaltain Census Bureaun datajulkaisuissa ja EU:n tilastovirasto Eurostatin mikroaineistoissa.
Hallinto-oikeuden emeritusprofessori Mäenpää sanoo, että "turvallisuus ja avoimuus kulkevat pikemminkin käsi kädessä kuin ovat toistensa vastakohtia." Datatiede on samaa mieltä. Mutta se vaatii, että salauksen logiikka käännetään — ja että päätöksentekijät ymmärtävät, mitä automaattinen salausjärjestelmä oikeastaan tekee.
---
## Lopuksi: tietosuoja on jakauma, ei kytkin. Se ei ole algoritmi, joka ei osaa lukea lakia
Pronto-järjestelmä on ollut käytössä yli kymmenen vuotta ja se on mustanut onnettomuusselosteita "ehkä koko olemassaolonsa ajan", kuten kehityspäällikkö Virtanen arvioi. Kukaan ei näytä kyseenalaistaneen tätä käytäntöä. Se on klassinen esimerkki siitä, miten automatisoitu prosessi muuttuu näkymättömäksi — kunnes merikotka törmää tuulivoimalaan ja paljastaa, että keisarilla ei ole vaatteita.
Automaattisalaus on huono ratkaisu paitsi oikeudellisesti myös tilastollisesti: se hävittää tietoa, jota yhteiskunta tarvitsee. Onnettomuusselosteet ovat arvokasta dataa turvallisuustutkimukselle, resurssisuunnittelulle ja viranomaisvalvonnalle. Kun ne salaataan automaattisesti, menetetään paitsi yksittäinen tapaus myös kumulatiivinen oppiminen.
Moderni tilastotiede, ja erityisesti **bayeslainen ajattelu**, tarjoaa paljon hienovaraisemman työkalupakin. Epävarmuus on tietoa. Julkaisemalla jakauma pisteen sijaan paljastetaan, mitä tiedetään ja mitä ei. Ja kun tiedetään, mitä ei tiedetä, voidaan päättää viisaammin siitä, mikä todella tarvitsee suojaa.
**Maailma on jakauma. Myös tietosuojakin.**
---
*Kristian Vepsäläinen on itsenäinen data-analytiikan konsultti ja Fractional Head of Data. Hän auttaa pk-yrityksiä tekemään parempia päätöksiä datan avulla — ilman täysiaikaisen datajohtajan palkkausta. [Varaa maksuton kartoituskeskustelu.](https://kristianvepsalainen.com)*