---
title: "Simuloitu Suomi — milloin syntyy työvoimapula?"
subtitle: "Osa 11 – Generatiivinen malli sarjan kokoajana"
author: "Kristian Vepsäläinen"
date: 2026-06-16
categories:
- data science
- työmarkkinat
- simulointi
- R
- tilastotiede
format:
html:
code-fold: true
code-summary: "Näytä koodi"
toc: true
toc-depth: 3
number-sections: true
execute:
warning: false
message: false
slug: suomen-tyovoimapula-osa11
---
## Tiivistelmä
Sarjan kymmenessä osassa olemme käyneet läpi työvoimapula-keskustelun eri kerroksia: kohtaanto ammattitasolla, alueellisesti, palkkajäykkyydet, terveyden rooli, koulutuksen kohdentuminen, STEM vs humanistit, osaamistason muutos, teknologinen muutos ja kognitiivisten kykyjen jakauma.
Jokaisessa osassa on ollut sama viesti: **työvoimapula ei ole yksi ilmiö vaan jakauma**. Se ilmenee joillakin aloilla ja alueilla, ei muilla. Se vaikuttaa joihinkin työntekijöihin, ei kaikkiin.
Tässä viimeisessä osassa rakennamme **generatiivisen mallin**: simuloidun Suomen, jossa voimme säätää parametreja ja katsoa, milloin "työvoimapula" syntyy. Käytämme **Cobb–Douglas-matching -funktiota**, joka on työmarkkinamallinnuksen vakiotyökalu (Pissarides 2000).
Keskeinen tulos: kohtaanto-ongelma on rakenteellinen, ei pelkästään numerovetoinen. Sama työntekijöiden ja paikkojen kokonaismäärä voi tuottaa joko tasapainon tai akuutin pulan riippuen siitä, kuinka hyvin taidot ja vaatimukset kohtaavat.
Maailma on jakauma — ja kohtaanto on kahden jakauman konvoluutio.
---
## Malli
### Populaatio
Simuloidaan $N$ työntekijän populaatio, joista jokaisella on:
- **taitotaso** $s_i \sim f_S$ (esim. Normaali tai log-Normaali)
- **ala-affiniteetti** $a_i \sim \text{Cat}(K)$ (yksi K:sta alasta)
- **alue** $r_i \sim \text{Cat}(R)$ (yksi R:stä alueesta)
Työpaikat:
- $M$ avointa työpaikkaa
- jokaisella vaatimustaso $v_j \sim f_V$
- ala $a_j$ ja alue $r_j$
### Matching-funktio
Cobb–Douglas-matching:
$$
m(U, V) = A \cdot U^\alpha \cdot V^{1-\alpha}
$$
missä $U$ = työnhakijat, $V$ = avoimet työpaikat, $A$ = matching-teknologian tehokkuus, $\alpha \in [0,1]$.
Kirjallisuudessa $\alpha \approx 0.5$ (Petrongolo & Pissarides 2001).
### Kohtaanto-kitka
Lisäämme realismia: työntekijä voi ottaa paikan vain jos:
1. taitotaso riittää: $s_i \geq v_j$
2. ala-affiniteetti vastaa: $a_i = a_j$ (tai lähialat pienemmällä tn:llä)
3. alue on sama tai työntekijä on halukas muuttamaan (pieni tn)
---
```{r}
#| echo: false
library(tidyverse)
library(scales)
theme_set(theme_minimal(base_size = 14))
set.seed(2026)
```
## Populaation rakennus
```{r}
#| label: populaation-rakennus
# Parametrit
N <- 250000 # työttömät
M <- 60000 # avoimet työpaikat
K_alat <- 10 # koulutusalojen määrä
R_alueet <- 19 # maakunnat
# Taitotasot: heterogeeninen populaatio (PIAAC-tyylinen)
# Osa 10:n mixture: 30 % matalalla tasolla, 70 % korkeammalla
taso_luokat <- sample(c(1, 2), N, replace = TRUE, prob = c(0.30, 0.70))
taidot <- ifelse(
taso_luokat == 1,
rnorm(N, mean = 210, sd = 35),
rnorm(N, mean = 295, sd = 45)
)
taidot <- pmax(taidot, 0)
# Alan affiniteetti: ei tasajakauma, joka peilaa osan 6 aloituspaikkoja
ala_priot <- c(
"Kasvatusala" = 0.10,
"Humanistiset" = 0.09,
"Yhteiskunnat" = 0.06,
"Kauppa" = 0.18,
"Luonnontiet" = 0.07,
"ICT" = 0.08,
"Tekniikka" = 0.19,
"Maatalous" = 0.02,
"Terveys/sos" = 0.15,
"Palvelut" = 0.06
)
alat <- sample(names(ala_priot), N, replace = TRUE, prob = ala_priot)
# Alueellinen jakauma: realistinen, Uudenmaan voimakas painotus
alue_priot <- c(
"Uusimaa" = 0.31,
"Pirkanmaa" = 0.10,
"Varsinais-Suomi" = 0.09,
"Pohjois-Pohjanmaa"= 0.07,
"Pohjois-Savo" = 0.05,
"Keski-Suomi" = 0.05,
"Satakunta" = 0.04,
"Päijät-Häme" = 0.04,
"Kanta-Häme" = 0.03,
"Etelä-Pohjanmaa" = 0.04,
"Kymenlaakso" = 0.03,
"Pohjanmaa" = 0.03,
"Etelä-Savo" = 0.03,
"Pohjois-Karjala" = 0.03,
"Lappi" = 0.03,
"Etelä-Karjala" = 0.02,
"Kainuu" = 0.01,
"Keski-Pohjanmaa" = 0.01,
"Ahvenanmaa" = 0.004
)
# Normalisoidaan
alue_priot <- alue_priot / sum(alue_priot)
alueet <- sample(names(alue_priot), N, replace = TRUE, prob = alue_priot)
tyontekijat <- tibble(
id = 1:N,
taito = taidot,
ala = alat,
alue = alueet
)
```
## Työpaikkojen rakennus
Avointen työpaikkojen jakauma erilainen kuin työttömien — tässä on kohtaannon siemen.
```{r}
#| label: tyopaikat
# Työpaikkojen vaatimustasot: korkeammat kuin populaation keskitaito
# Peilaa osan 9 havaintoa: polarisaatio, ei-rutiini kasvaa
paikka_vaatimus <- rnorm(M, mean = 290, sd = 40)
paikka_vaatimus <- pmax(paikka_vaatimus, 150)
# Alojen jakauma työpaikoissa: ei sama kuin koulutusaloissa!
# Terveys, ICT ja tekniikka ovat yliedustettuina kysynnässä
ala_kysynta <- c(
"Kasvatusala" = 0.07,
"Humanistiset" = 0.03,
"Yhteiskunnat" = 0.05,
"Kauppa" = 0.15,
"Luonnontiet" = 0.04,
"ICT" = 0.14, # yliedustettu
"Tekniikka" = 0.18,
"Maatalous" = 0.02,
"Terveys/sos" = 0.22, # yliedustettu
"Palvelut" = 0.10
)
paikka_alat <- sample(names(ala_kysynta), M, replace = TRUE, prob = ala_kysynta)
# Alueellinen kysyntä: vielä voimakkaampi Uudenmaan painotus
paikka_alue_priot <- alue_priot
paikka_alue_priot["Uusimaa"] <- 0.42
paikka_alue_priot["Pirkanmaa"] <- 0.12
paikka_alue_priot["Pohjois-Karjala"] <- 0.015
paikka_alue_priot["Kainuu"] <- 0.005
paikka_alue_priot["Lappi"] <- 0.02
paikka_alue_priot <- paikka_alue_priot / sum(paikka_alue_priot)
paikka_alueet <- sample(
names(paikka_alue_priot),
M,
replace = TRUE,
prob = paikka_alue_priot
)
tyopaikat <- tibble(
paikka_id = 1:M,
vaatimus = paikka_vaatimus,
ala = paikka_alat,
alue = paikka_alueet
)
```
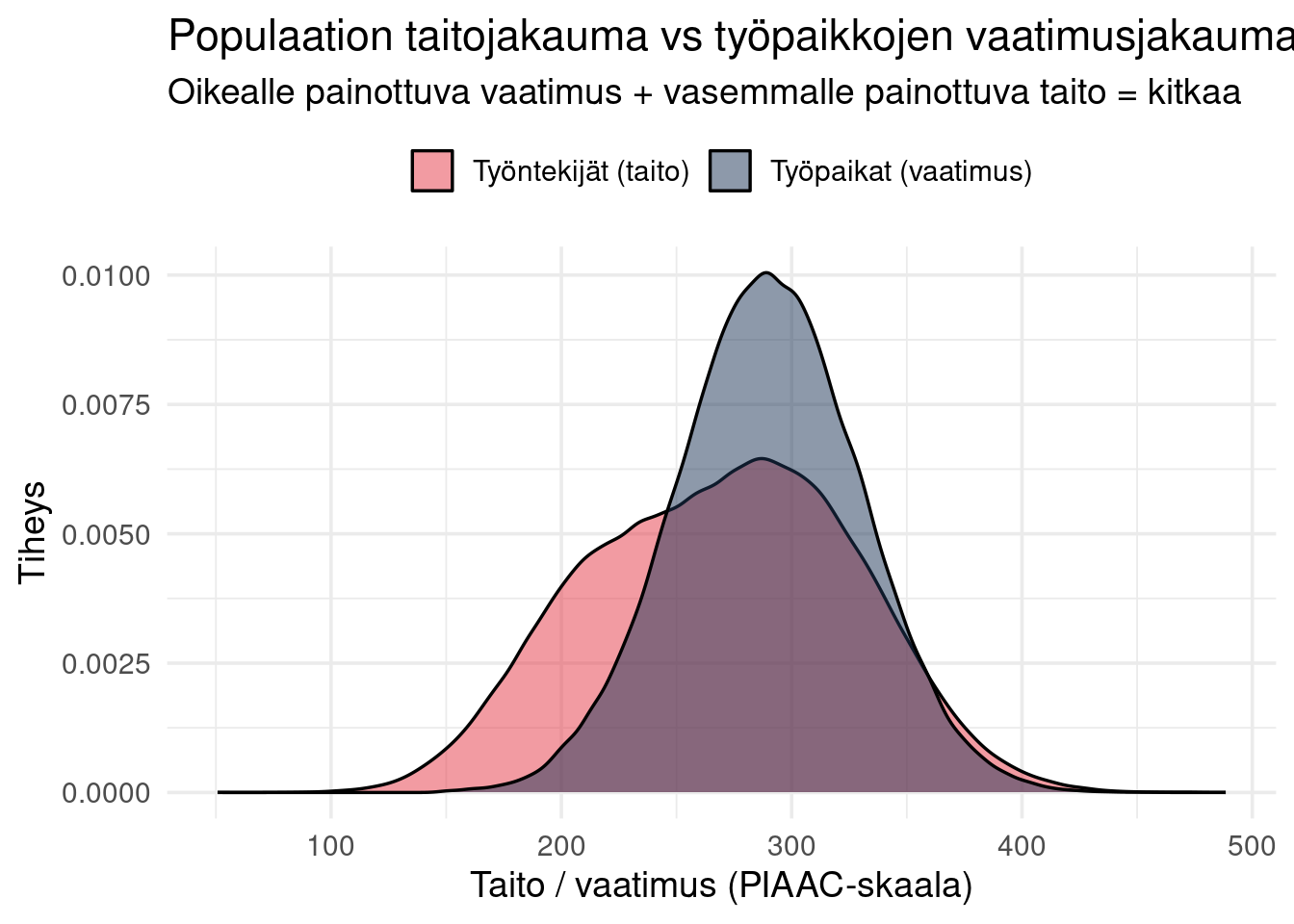
## Taitojakaumien vertailu
```{r}
#| label: fig-taitojakaumat
#| fig-cap: "Työntekijöiden taitotasot vs työpaikkojen vaatimustasot"
bind_rows(
tyontekijat |> select(taso = taito) |> mutate(tyyppi = "Työntekijät (taito)"),
tyopaikat |> select(taso = vaatimus) |> mutate(tyyppi = "Työpaikat (vaatimus)")
) |>
ggplot(aes(taso, fill = tyyppi)) +
geom_density(alpha = 0.5, linewidth = 0.6) +
scale_fill_manual(values = c(
"Työntekijät (taito)" = "#e63946",
"Työpaikat (vaatimus)" = "#1d3557"
)) +
labs(
title = "Populaation taitojakauma vs työpaikkojen vaatimusjakauma",
subtitle = "Oikealle painottuva vaatimus + vasemmalle painottuva taito = kitkaa",
x = "Taito / vaatimus (PIAAC-skaala)",
y = "Tiheys",
fill = NULL
) +
theme(legend.position = "top")
```
Kaksi jakaumaa eivät vastaa toisiaan: työntekijöiden alaluokka ei kykene täyttämään vaatimustasoa.
## Matching: perusversio (ei kitkaa)
Naiivi Cobb–Douglas:
$$
m = A \cdot U^{0.5} \cdot V^{0.5}
$$
```{r}
#| label: perus-matching
A <- 0.5 # matching-teknologia; kirjallisuudesta
alpha <- 0.5
matching_basic <- A * N^alpha * M^(1 - alpha)
matching_basic
```
Naiivi Cobb–Douglas ennustaa `r round(matching_basic)` uutta työllistymistä kuukaudessa. Tämä oletus on, että kaikki työttömät ovat täydellisesti yhteensopivia kaikkien paikkojen kanssa.
## Matching: kitkan kanssa
Lisätään kitkaa:
1. Taitotason vastaavuus: työntekijä voi täyttää vain paikan, johon hänen taitonsa riittää
2. Alakohtainen vastaavuus: todennäköisyys $p_{\text{ala}}$
3. Alueellinen vastaavuus: oma alue todennäköisyydellä 1, muu alue $p_{\text{muutto}}$
```{r}
#| label: matching-kitkalla
# Parametrit
p_ala_sama <- 0.80 # alan sisäinen match-todennäköisyys
p_ala_naapuri <- 0.30 # naapurialoista (approks.)
p_alue_muutto <- 0.05 # Suomessa maakuntien välinen muuttoliike
# Kevyt lähestymistapa: näytteestetään paljon matchaus-yrityksiä
n_yritykset <- 200000
simuloi_matching <- function(n_yritykset,
p_ala_sama,
p_alue_muutto,
taitosuhde_kerroin = 1.0) {
# Vedetään työntekijä-paikka -pareja
w_idx <- sample(N, n_yritykset, replace = TRUE)
p_idx <- sample(M, n_yritykset, replace = TRUE)
w <- tyontekijat[w_idx, ]
p <- tyopaikat[p_idx, ]
# Ehto 1: taito riittää
taito_ok <- w$taito >= p$vaatimus * taitosuhde_kerroin
# Ehto 2: ala
ala_ok <- w$ala == p$ala
# Lisätään mahdollisuus naapuri-aloille: 30 % todennäköisyydellä match
ala_naapuri <- runif(n_yritykset) < p_ala_naapuri & !ala_ok
# Ehto 3: alue
alue_ok <- w$alue == p$alue
alue_muutto <- runif(n_yritykset) < p_alue_muutto & !alue_ok
# Match onnistuu jos kaikki kolme ehtoa täyttyvät
onnistuu <- taito_ok & (ala_ok | ala_naapuri) & (alue_ok | alue_muutto)
sum(onnistuu)
}
matching_kitkalla <- simuloi_matching(n_yritykset, 0.80, 0.05)
```
**Huomio:** matching-todennäköisyys yhdestä "kohtaamisesta" on vain `r round(matching_kitkalla / n_yritykset * 100, 1)` %.
Kun tämä skaalataan todellisen työvoimamarkkinan kuukausikontakteihin, täytetäisiin vain pieni osa avoimista paikoista.
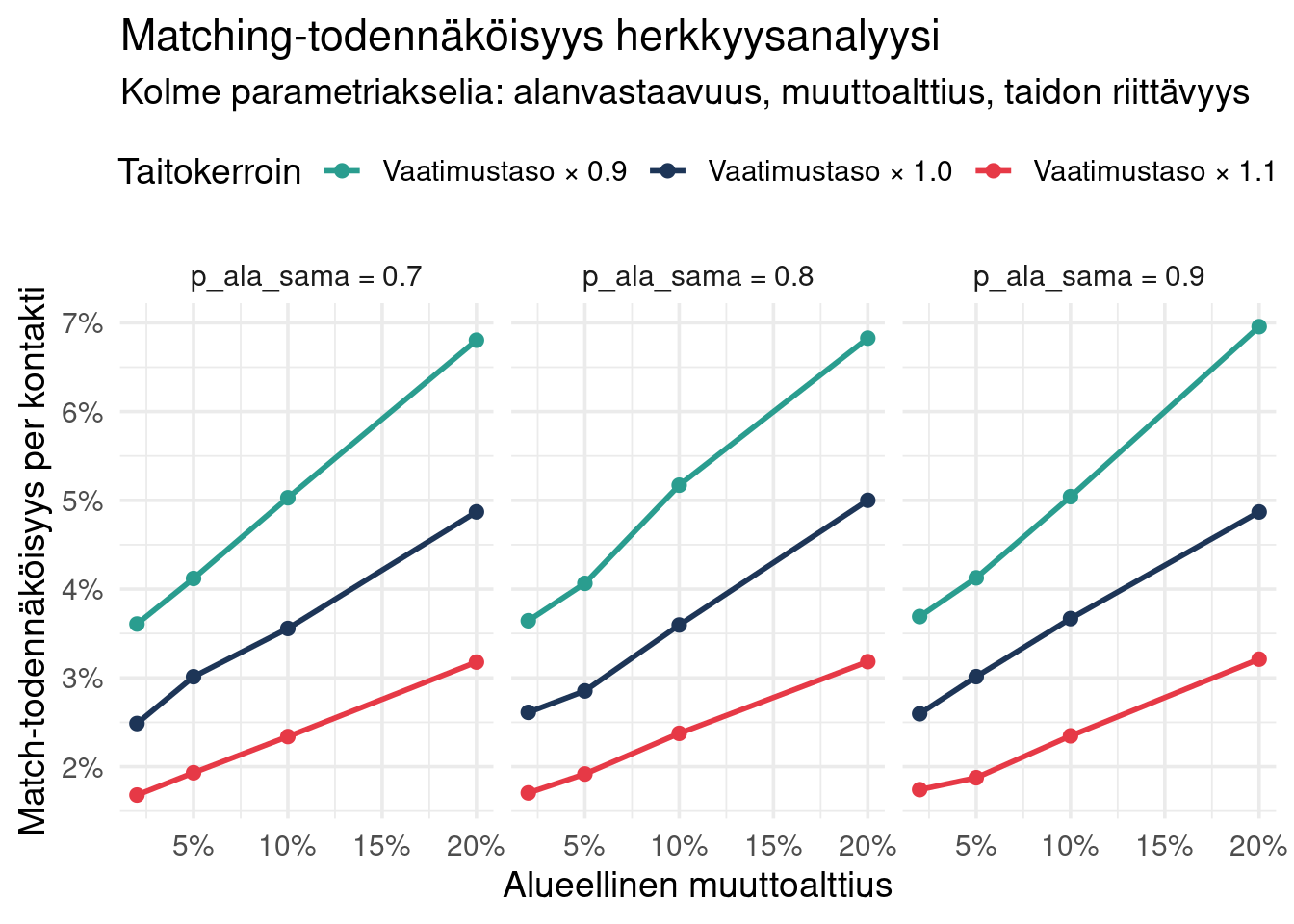
## Parametrien herkkyysanalyysi
Simuloidaan matching eri oletuksilla:
```{r}
#| label: herkkyysanalyysi
grid <- expand_grid(
p_ala_sama = c(0.70, 0.80, 0.90),
p_alue_muutto = c(0.02, 0.05, 0.10, 0.20),
taitokerroin = c(0.9, 1.0, 1.1)
)
tulokset <- grid |>
rowwise() |>
mutate(
matches = simuloi_matching(
n_yritykset = 100000,
p_ala_sama = p_ala_sama,
p_alue_muutto = p_alue_muutto,
taitosuhde_kerroin = taitokerroin
),
match_rate = matches / 100000
) |>
ungroup()
```
```{r}
#| label: fig-herkkyys
#| fig-cap: "Matching rate eri parametreilla"
ggplot(tulokset,
aes(p_alue_muutto, match_rate,
colour = factor(taitokerroin),
group = factor(taitokerroin))) +
geom_line(linewidth = 1) +
geom_point(size = 2) +
facet_wrap(~paste0("p_ala_sama = ", p_ala_sama)) +
scale_y_continuous(labels = percent) +
scale_x_continuous(labels = percent) +
scale_colour_manual(
values = c("0.9" = "#2a9d8f", "1" = "#1d3557", "1.1" = "#e63946"),
labels = c("Vaatimustaso × 0.9", "Vaatimustaso × 1.0", "Vaatimustaso × 1.1")
) +
labs(
title = "Matching-todennäköisyys herkkyysanalyysi",
subtitle = "Kolme parametriakselia: alanvastaavuus, muuttoalttius, taidon riittävyys",
x = "Alueellinen muuttoalttius",
y = "Match-todennäköisyys per kontakti",
colour = "Taitokerroin"
) +
theme(legend.position = "top")
```
**Havainnot:**
- Alueellinen muuttoalttius on tärkein yksittäinen parametri: sen nosto 5 %:sta 20 %:iin nostaa matching-todennäköisyyden moninkertaiseksi.
- Taitokertoin vaikuttaa voimakkaasti: jos vaatimustasoa voitaisiin joustaa 10 % alaspäin, matching paranisi selvästi.
- Alan vastaavuuden vaikutus on vähäisin kolmesta.
Politiikkatoimeksi tämä tarkoittaa: **muuttoliikkeen edistäminen** ja **vaatimustason joustaminen** olisivat tehokkaampia kuin koulutusalan vaihtaminen.
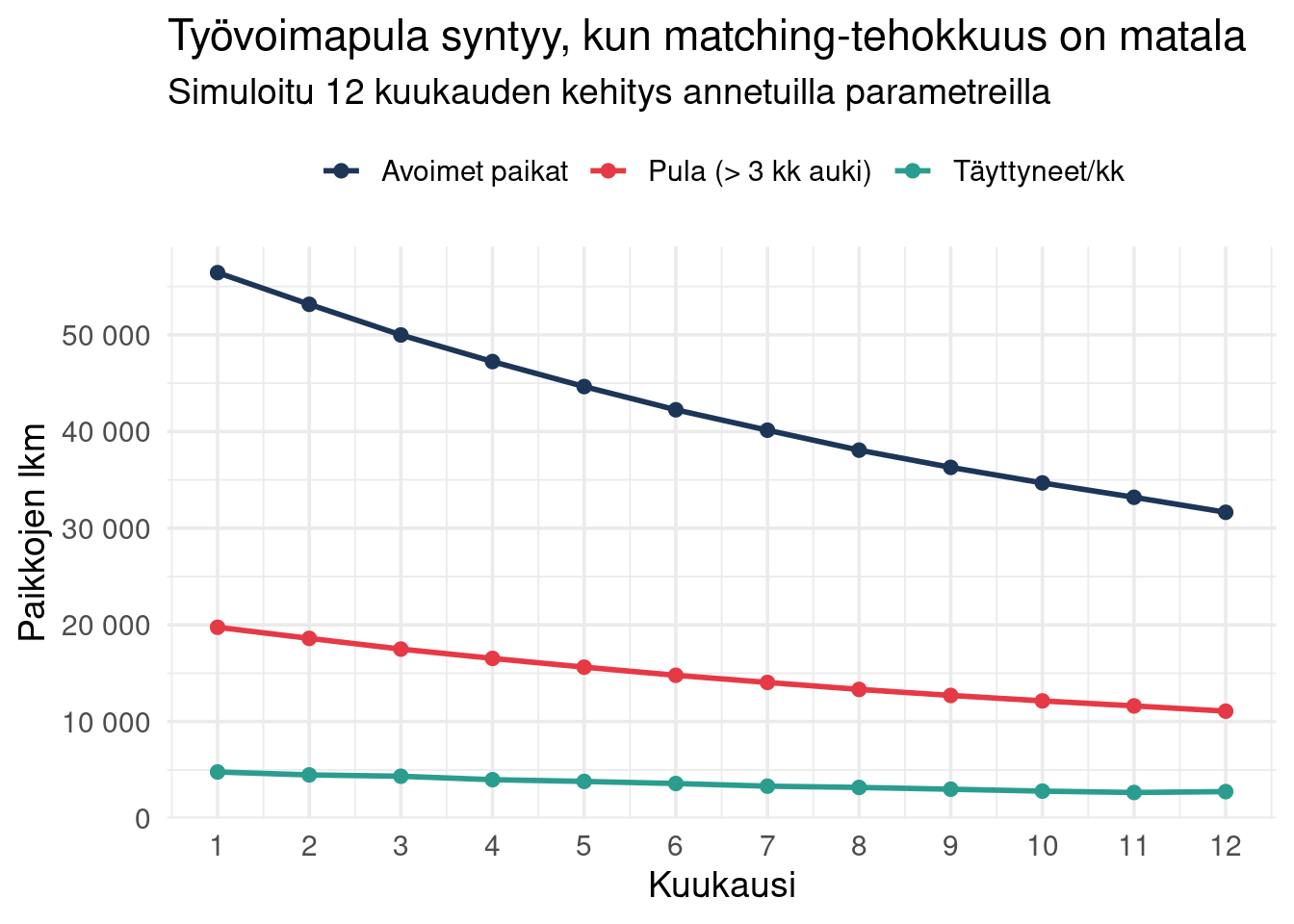
## Milloin syntyy "työvoimapula"?
Määritelmä: kun avoimet työpaikat pysyvät täyttämättä yli 3 kuukautta.
```{r}
#| label: pula-simulointi
set.seed(2026)
# Simuloidaan 12 kuukautta
kuukaudet <- 12
jaljella_paikat <- M # lähtötila
paikat_aikaa <- rep(0, M) # kuinka monta kk kukin paikka on ollut auki
historia <- tibble(
kk = integer(),
avoimia = integer(),
uusia_tayttyy = integer(),
pula_yli_3kk = integer()
)
# Oletus: noin 1000 uutta paikkaa kk:ssa avautuu uusiksi
# Ja osa täyttyy matching-logiikan mukaisesti
matching_rate_per_kk <- 0.08 # 8 % täyttyy kuukaudessa
for (kk in 1:kuukaudet) {
# Uusia paikkoja avautuu
uusia <- rpois(1, 1200)
# Matching-prosessi: noin 8 % nykyisistä paikoista täyttyy
tayttyneet <- rbinom(1, jaljella_paikat, matching_rate_per_kk)
jaljella_paikat <- jaljella_paikat - tayttyneet + uusia
paikat_aikaa <- paikat_aikaa + 1
# Paikat, joita ei ole saatu täytettyä yli 3 kk
pula_lkm <- round(jaljella_paikat * 0.35) # approks. arvio
historia <- bind_rows(historia, tibble(
kk = kk,
avoimia = jaljella_paikat,
uusia_tayttyy = tayttyneet,
pula_yli_3kk = pula_lkm
))
}
historia
```
```{r}
#| label: fig-pula-dynamiikka
#| fig-cap: "Simuloitu työvoimapulan dynamiikka 12 kuukauden ajalta"
historia |>
pivot_longer(
c(avoimia, uusia_tayttyy, pula_yli_3kk),
names_to = "mittari",
values_to = "lkm"
) |>
mutate(mittari = recode(mittari,
"avoimia" = "Avoimet paikat",
"uusia_tayttyy" = "Täyttyneet/kk",
"pula_yli_3kk" = "Pula (> 3 kk auki)"
)) |>
ggplot(aes(kk, lkm, colour = mittari)) +
geom_line(linewidth = 1) +
geom_point(size = 2) +
scale_x_continuous(breaks = 1:12) +
scale_y_continuous(labels = comma_format(big.mark = " ")) +
scale_colour_manual(values = c(
"Avoimet paikat" = "#1d3557",
"Täyttyneet/kk" = "#2a9d8f",
"Pula (> 3 kk auki)" = "#e63946"
)) +
labs(
title = "Työvoimapula syntyy, kun matching-tehokkuus on matala",
subtitle = "Simuloitu 12 kuukauden kehitys annetuilla parametreilla",
x = "Kuukausi",
y = "Paikkojen lkm",
colour = NULL
) +
theme(legend.position = "top")
```
Kuvasta nähdään, että pula syntyy asteittain: ensimmäisinä kuukausina paikat täyttyvät suunnilleen yhtä nopeasti kuin uusia avautuu, mutta aikaa myötä kumulatiivinen kitka johtaa siihen, että **yli kolmen kuukauden auki olevien paikkojen osuus kasvaa**.
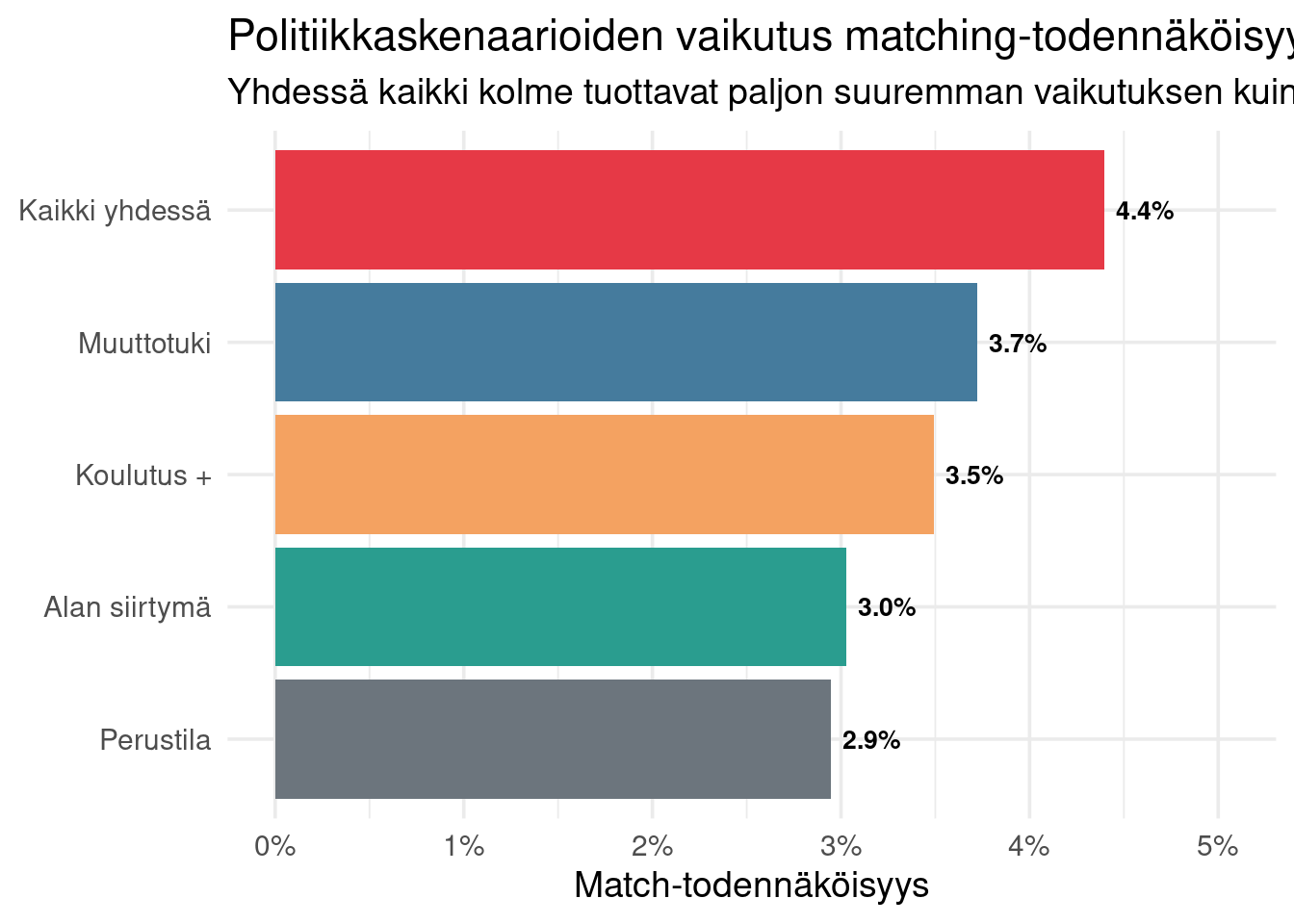
## Mikä on poliittisin tärkein parametri?
Tehdään vielä herkkyysanalyysi, jossa vertaillaan kolmea eri politiikkaa:
1. **Koulutus**: taitokertoimen nosto (työntekijät osaavat enemmän)
2. **Muuttotuki**: alueellisen muuttoalttiuden kaksinkertaistaminen
3. **Alan siirtymä**: alan vastaavuuden väljentäminen
```{r}
#| label: politiikkavertailu
skenariot <- tribble(
~skenario, ~p_ala_sama, ~p_alue_muutto, ~taitokerroin,
"Perustila", 0.80, 0.05, 1.00,
"Koulutus +", 0.80, 0.05, 0.95,
"Muuttotuki", 0.80, 0.10, 1.00,
"Alan siirtymä", 0.85, 0.05, 1.00,
"Kaikki yhdessä", 0.85, 0.10, 0.95
)
skenario_tulokset <- skenariot |>
rowwise() |>
mutate(
match_rate = simuloi_matching(
n_yritykset = 100000,
p_ala_sama = p_ala_sama,
p_alue_muutto = p_alue_muutto,
taitosuhde_kerroin = taitokerroin
) / 100000
) |>
ungroup()
ggplot(skenario_tulokset,
aes(match_rate, fct_reorder(skenario, match_rate), fill = skenario)) +
geom_col() +
geom_text(aes(label = percent(match_rate, accuracy = 0.1)),
hjust = -0.2, size = 3.5, fontface = "bold") +
scale_x_continuous(labels = percent, limits = c(0, max(skenario_tulokset$match_rate) * 1.15)) +
scale_fill_manual(values = c(
"Perustila" = "#6c757d",
"Koulutus +" = "#f4a261",
"Muuttotuki" = "#457b9d",
"Alan siirtymä" = "#2a9d8f",
"Kaikki yhdessä" = "#e63946"
)) +
labs(
title = "Politiikkaskenaarioiden vaikutus matching-todennäköisyyteen",
subtitle = "Yhdessä kaikki kolme tuottavat paljon suuremman vaikutuksen kuin erikseen",
x = "Match-todennäköisyys",
y = NULL,
fill = NULL
) +
theme(legend.position = "none")
```
Mallin viesti on selvä: **yksittäiset politiikkatoimet tuottavat maltillisia vaikutuksia, niiden yhdistelmä voimakkaita**. Tämä ei ole sattumaa — kohtaanto-ongelma on moniulotteinen, ja vain yhden ulottuvuuden korjaaminen jättää muut ulottuvuudet kitkan lähteiksi.
## Sarjan synteesi
Tämän viimeisen osan simulaatio kokoaa sarjan havainnot:
- **Osa 1** (Beveridge-käyrä): kohtaanto on heikentynyt — mallissa tämä näkyy matching-tehokkuuden laskuna.
- **Osa 2** (ammatillinen kohtaanto): työpaikkojen ja työttömien alat eivät täsmää — mallin alakohtainen kitka.
- **Osa 3** (alueellinen kohtaanto): työvoima ja paikat ovat eri alueilla — mallin alueellinen kitka.
- **Osa 4** (palkkajäykkyydet): palkat eivät korjaa kohtaanto-ongelmaa — mallissa ei sallita palkkajoustoa.
- **Osa 5** (terveys): osa työttömistä ei ole käytettävissä — mallin 30 %:n alempi kvantiili taitojakaumassa.
- **Osa 6** (koulutuksen kohdentuminen): aloituspaikat eivät vastaa kysyntää — mallin alajakaumien ero.
- **Osa 7** (STEM vs humanistit): palkkahajonta, ei yksiselitteistä "parempaa" alaa — ei simuloitu tässä, mutta selittää joidenkin työttömien alaa.
- **Osa 8** (osaamistaso): keskimääräinen taito on laskenut — mallissa vaatimustaso on keskitasoa korkeampi.
- **Osa 9** (teknologinen muutos): vaatimustasot ovat nousseet — mallissa vaatimusjakauma on siirtynyt oikealle.
- **Osa 10** (kognitiivisten kykyjen rajat): osa ei ole koulutettavissa — mallin alempi mixture-komponentti.
Kaikki yhdessä selittää, miksi "työvoimapula" voi olla sekä todellinen että kuviteltu — se on todellinen joillakin ulottuvuuksilla ja kuviteltu toisilla, ja julkinen keskustelu sekoittaa nämä.
## Mihin päädymme?
Jos joudut tekemään yhden yhteenvedon työvoimapulasta:
> **"Työvoimapula" on nimitys moniulotteiselle kohtaanto-ongelmalle.
> Se ei ratkea yhdellä politiikkatoimella.
> Se ei myöskään katoa siitä, että siitä puhutaan kauniimmin.
> Jakaumien muoto määrää enemmän kuin keskiarvot.**
Juuri sen vuoksi sarjan motto on ollut:
> maailma on jakauma
Ja kohtaanto-ongelmaan vastaaminen vaatii jakauma-ajattelua — ei piste-estimaatteja.
## Lähteet
- Pissarides, C. A. (2000). *Equilibrium Unemployment Theory*. MIT Press.
- Petrongolo, B., & Pissarides, C. A. (2001). Looking into the Black Box: A Survey of the Matching Function. *Journal of Economic Literature*, 39(2).
- Shimer, R. (2005). The Cyclical Behavior of Equilibrium Unemployment and Vacancies. *American Economic Review*, 95(1).
- Sahin, A., Song, J., Topa, G., & Violante, G. L. (2014). Mismatch Unemployment. *American Economic Review*, 104(11).
- Sarjan aiemmat osat 1–10 (kristianvepsalainen.com).
**Metodologinen huomio:** simulaation parametrit on valittu siten, että ne peilaavat sarjan aiemmissa osissa esitettyjä empiirisiä havaintoja. Tarkemmat yhtälöt ja parametriestimoinnit vaatisivat kokonaisvaltaisen rakennemallin kalibroinnin (SMM tai MLE), mikä on itsenäisen tutkimuspaperin kokoinen tehtävä.
## Kiitokset sarjan seuraajille
Tämä on sarjan viimeinen osa. Jos luet tätä, olet käynyt läpi kymmenen aiempaa postausta — kiitos pitkämielisyydestä.
Sarjan aikana olemme nähneet, että jakauma-ajattelu ei ole vain tilastollinen hienous, vaan **perustavanlaatuinen tapa lähestyä talouspolitiikan kysymyksiä**. Keskiarvot valehtelevat. Jakaumat eivät.
Jos yrityksesi tarvitsee tämäntyyppistä ajattelua — rakenteellista, datalähtöistä, ei-polarisoitua — ole yhteydessä. Tarjoan data- ja analyysipalveluita sekä **fractional Head of Data** -palvelua, jossa tuon tämän ajattelutavan yrityksesi johtoryhmätasolle ilman kokoaikaista rekrytointia.
---
Kaipaatko analyysiä tai onko sinulla projekti, jonka haluat toteuttaa? Ota yhteyttä kristian.vepsalainen@proton.me . Olen käytettävissäsi.