---
title: "Keitä kansanedustajat ovat — ja ketä he eivät edusta"
subtitle: "Eduskunta jakaumana, osa 1: kuka salissa istuu"
description: >
Vuoden 2027 vaalit lähestyvät ja puolueet asettavat ehdokkaitaan. Ennen kuin
arvioimme seuraavaa eduskuntaa, katsotaan dataan: keitä kansanedustajat ovat
olleet sadan vuoden ajan — ja kuinka paljon eduskunta poikkeaa väestöstä.
date: 2026-07-02
author: "Kristian Vepsäläinen"
categories: [eduskunta, avoin data, bayes, jakaumat, edustavuus]
format:
html:
toc: true
toc-title: "Sisällys"
code-fold: true
code-summary: "Näytä koodi"
code-tools: true
execute:
warning: false
message: false
echo: true
---
> **Sarjan idea.** "Maailma on jakauma" tarkoittaa, että yksittäinen luku —
> keskiarvo, otsikko, pistearvio — kätkee yleensä enemmän kuin se paljastaa.
> Tässä sarjassa puramme eduskunnan avointa dataa juuri tästä näkökulmasta.
> Aloitamme ihmisistä: keitä kansanedustajat ovat, ja edustaako eduskunta sitä
> kansaa, jonka se valitsee.
## Uutiskoukku: ennen kuin arvioit seuraavaa eduskuntaa
Seuraavat eduskuntavaalit pidetään **18.4.2027**, ja puolueet asettavat
ehdokkaitaan parhaillaan. Pian uutiset täyttyvät ehdokasgallerioista, ja jokainen
meistä tekee nopean arvion: "tämä porukka näyttää tältä". Se arvio on pistearvio —
yksi mielikuva yhdestä otoksesta.
Tämä kirjoitus tarjoaa vaihtoehdon. Sen sijaan että muodostaisimme mielikuvan,
katsomme **koko jakaumaa**: keitä kansanedustajat ovat olleet, miten se on
muuttunut, ja — olennaisin kysymys päättäjälle — kuinka paljon eduskunta
**poikkeaa väestöstä**, jota se edustaa. Lopuksi mittaamme poikkeaman
tilastollisesti ja kerromme rehellisesti, mitä luku tarkoittaa ja mitä ei.
## Mistä data tulee
Käytämme kahta julkista lähdettä:
- **Eduskunnan avoin data** (`avoindata.eduskunta.fi`, CC BY 4.0): kansanedustajien
henkilötiedot vuodesta 1908 — `MemberOfParliament`-taulu, jossa kunkin edustajan
tiedot ovat jäsenneltynä XML:nä.
- **Tilastokeskus, StatFin** (taulu `11rc`, väestö iän ja sukupuolen mukaan
1865–2025): vertailujakauma väestöstä.
```{r setup}
#| cache: false
# --- Setup ajetaan ENSIN. Muut lohkot olettavat tämän ajetuksi. ---
library(tidyverse)
library(here) # polut here-paketilla
library(httr2) # eduskunnan rajapinta
library(xml2) # MemberOfParliament-XML
library(pxweb) # StatFin (hoitaa GET-before-POSTin)
library(qs2) # raskaiden välimuistien tallennus (XML kasvaa isoksi)
library(ggdist)
library(patchwork)
library(scales)
set.seed(20270418) # vaalipäivä siemenenä
pal <- c(punainen = "#e63946", turkoosi = "#2a9d8f", oranssi = "#f4a261",
laivasto = "#1d3557", sininen = "#457b9d")
theme_kv <- function() {
theme_minimal(base_size = 13) +
theme(plot.title = element_text(face = "bold"),
plot.subtitle = element_text(color = "grey30"),
panel.grid.minor = element_blank(),
legend.position = "top", legend.title = element_blank())
}
theme_set(theme_kv())
data_dir <- here("data", "eduskunta")
dir.create(data_dir, recursive = TRUE, showWarnings = FALSE)
mp_raw_path <- file.path(data_dir, "mp_raw.qs") # iso (XML) -> qs
mp_parsed_path <- file.path(data_dir, "mp_parsed.qs") # list-sarakkeita -> qs
pop_path <- file.path(data_dir, "vaesto.qs")
REF_VUOSI <- 2025L # vertailuvuosi nykyeduskunnalle
```
## Haku 1: kansanedustajat eduskunnan rajapinnasta
```{r hae-mp}
#| cache: false
hae_eduskunta_taulu <- function(taulu, per_page = 100, max_sivut = 500) {
base <- "https://avoindata.eduskunta.fi/api/v1/tables"
rivit <- list(); sarakkeet <- NULL; sivu <- 0
repeat {
js <- request(base) |>
req_url_path_append(taulu, "rows") |>
req_url_query(page = sivu, perPage = per_page) |>
req_user_agent("kristianvepsalainen.com (avoin data -analyysi)") |>
req_retry(max_tries = 4) |>
req_perform() |>
resp_body_json(simplifyVector = FALSE)
if (is.null(sarakkeet)) sarakkeet <- unlist(js$columnNames)
if (length(js$rowData) == 0) break
rivit <- c(rivit, js$rowData)
if (isFALSE(js$hasMore)) break
sivu <- sivu + 1; if (sivu >= max_sivut) break
}
m <- do.call(rbind, lapply(rivit, \(r) unlist(lapply(r, \(x) x %||% NA))))
colnames(m) <- sarakkeet
as_tibble(m)
}
if (!file.exists(mp_raw_path)) {
mp_raw <- hae_eduskunta_taulu("MemberOfParliament")
qs2::qd_save(mp_raw, mp_raw_path)
}
mp_raw <- qs2::qd_read(mp_raw_path)
stopifnot("MP-haku tyhjä" = nrow(mp_raw) > 0,
"MP-rivejä epäilyttävän vähän" = nrow(mp_raw) >= 2000)
xml_col <- "XmlDataFi"
stopifnot("XML-saraketta ei löydy" = xml_col %in% names(mp_raw))
```
### XML:n jäsentäminen
Henkilö-XML sisältää muun muassa elementit `SukuPuoliKoodi`, `SyntymaPvm`,
`Ammatti` sekä rakenteet `Edustajatoimet` (todelliset edustajakaudet) ja
`Vaalipiirit`. Poimimme edustavuusvertailuun tarvittavan: **sukupuoli**,
**syntymävuosi** ja **kaudet**.
```{r jasenna-mp}
#| cache: false
vuosi <- function(x) suppressWarnings(as.integer(str_extract(x, "\\d{4}")))
jasenna_henkilo <- function(xml_str) {
if (is.na(xml_str) || !nzchar(xml_str)) return(NULL)
doc <- read_xml(xml_str)
g <- function(xp) {
v <- xml_text(xml_find_first(doc, xp)); if (length(v) == 0) NA_character_ else v
}
toimet <- xml_find_all(doc, ".//Edustajatoimet/Edustajatoimi")
kaudet <- if (length(toimet) == 0) tibble(alku = NA_integer_, loppu = NA_integer_)
else map_dfr(toimet, \(t) tibble(
alku = vuosi(xml_text(xml_find_first(t, "./AlkuPvm"))),
loppu = vuosi(xml_text(xml_find_first(t, "./LoppuPvm")))))
tibble(
henkilo_nro = g(".//HenkiloNro"),
etunimi = g(".//EtunimetNimi"),
sukunimi = g(".//SukuNimi"),
sp_koodi = g(".//SukuPuoliKoodi"),
synt_pvm = g(".//SyntymaPvm"),
ammatti = g(".//Ammatti"),
kaudet = list(kaudet)
)
}
if (!file.exists(mp_parsed_path)) {
mp_long <- map_dfr(mp_raw[[xml_col]], jasenna_henkilo)
qs2::qd_save(mp_long, mp_parsed_path)
}
mp_long <- qs2::qd_read(mp_parsed_path)
stopifnot("Liian vähän jäsennettyjä" = nrow(mp_long) >= 2000)
mp <- mp_long |>
mutate(
nimi = str_squish(paste(etunimi, sukunimi)),
synt_vuosi = vuosi(synt_pvm),
sp_l = str_to_lower(replace_na(sp_koodi, "")),
sukupuoli = case_when(
sp_l %in% c("1", "m", "mies") | str_starts(sp_l, "mie") ~ "Mies",
sp_l %in% c("2", "n", "nainen") | str_starts(sp_l, "nai") ~ "Nainen",
TRUE ~ NA_character_))
# Itsevarmistus: tunnetut edustajat oikein? (kaataa renderöinnin jos koodaus väärin)
tark <- mp |> filter(nimi %in% c("Esko Aho", "Raila Aho")) |>
select(nimi, sukupuoli) |> deframe()
stopifnot(
"Sukupuoli yhä enimmäkseen NA" = mean(is.na(mp$sukupuoli)) < 0.10,
"Sukupuolikoodin suunta väärin (Esko Aho ei mies)" =
is.na(tark["Esko Aho"]) || tark["Esko Aho"] == "Mies",
"Sukupuolikoodin suunta väärin (Raila Aho ei nainen)" =
is.na(tark["Raila Aho"]) || tark["Raila Aho"] == "Nainen")
```
### Edustajakaudet palveluvuosiksi
```{r mp-vuodet}
#| cache: false
mp_years <- mp |>
select(henkilo_nro, nimi, sukupuoli, synt_vuosi, kaudet) |>
unnest(kaudet) |> filter(!is.na(alku)) |>
mutate(loppu = coalesce(loppu, REF_VUOSI)) |>
filter(loppu >= alku, between(alku, 1907, REF_VUOSI)) |>
mutate(v = map2(alku, pmin(loppu, REF_VUOSI), seq)) |>
unnest(v) |> rename(vuosi = v) |>
mutate(ika = vuosi - synt_vuosi) |>
distinct(henkilo_nro, vuosi, .keep_all = TRUE)
stopifnot("Edustajavuodet tyhjä" = nrow(mp_years) > 5000)
# Nykyeduskunta: REF_VUOSI:nä istuvat
nyt <- mp_years |> filter(vuosi == REF_VUOSI) |>
distinct(henkilo_nro, .keep_all = TRUE) |>
filter(between(ika, 18, 100))
stopifnot("Nykyedustajia ei ~200" = between(nrow(nyt), 180, 220))
```
## Haku 2: väestön vertailujakauma (StatFin 11rc)
Käytämme `pxweb_interactive()`-työkalun tuottamaa varmaa kyselyä. Toimiva
API-osoite on `statfin.stat.fi/PXWeb/api/v1/...` ja taulu **11rc** (väestö
iän ja sukupuolen mukaan, 5-vuotisluokat, 1865–2025).
```{r hae-vaesto}
#| cache: false
pop_url <- "https://statfin.stat.fi/PXWeb/api/v1/fi/StatFin/vaerak/11rc.px"
pop_query <- list(
"timeperiod_y" = as.character(1865:2025),
"sukupuoli_9_20180101" = c("1", "2"), # 1 = Miehet, 2 = Naiset (jätetään SSS pois)
"ikaryhma_10_20180101" = c("20-24","25-29","30-34","35-39","40-44","45-49",
"50-54","55-59","60-64","65-69","70-74","75-79",
"80-84","85-"),
"contentscode" = "vaerak-vaesto")
if (!file.exists(pop_path)) {
px <- pxweb_get(url = pop_url, query = pxweb_query(pop_query))
px_df <- as.data.frame(px, column.name.type = "text", variable.value.type = "text")
qs2::qd_save(px_df, pop_path)
}
px_df <- qs2::qd_read(pop_path)
# Sarakkeet tulevat muuttujien teksteinä — ratkaistaan ne nimien perusteella,
# ettei koodi hajoa jos otsikointi muuttuu.
nimet <- names(px_df)
col_v <- nimet[str_detect(str_to_lower(nimet), "vuosi")][1]
col_sp <- nimet[str_detect(str_to_lower(nimet), "sukupuoli")][1]
col_ika<- nimet[str_detect(str_to_lower(nimet), "ikä|ikaryhma|ikä")][1]
col_n <- nimet[str_detect(str_to_lower(nimet), "väestö|vaesto")][1]
stopifnot("StatFin-sarakkeita ei tunnistettu" =
!any(is.na(c(col_v, col_sp, col_ika, col_n))))
vaesto <- px_df |>
transmute(
vuosi = as.integer(.data[[col_v]]),
sukupuoli = .data[[col_sp]],
ika_alaraja = as.integer(str_extract(.data[[col_ika]], "\\d+")),
n = as.numeric(.data[[col_n]])) |>
filter(!is.na(n), ika_alaraja >= 20)
stopifnot("Väestö-tibble tyhjä" = nrow(vaesto) > 0)
```
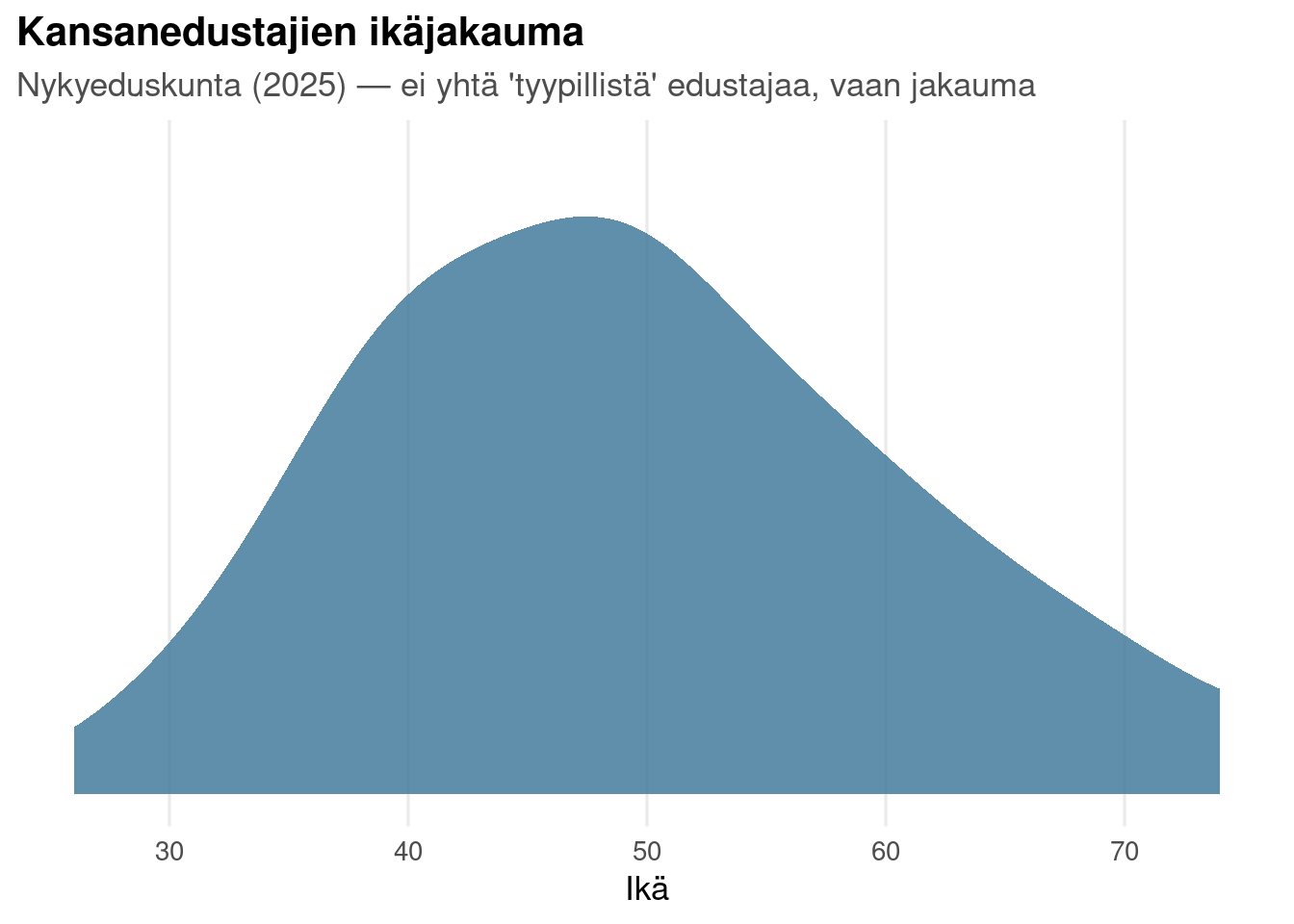
## Jakauma ensin: ikä nyt
```{r eda-nyt}
ggplot(nyt, aes(x = ika)) +
stat_slab(fill = pal["sininen"], alpha = .85) +
labs(title = "Kansanedustajien ikäjakauma",
subtitle = paste0("Nykyeduskunta (", REF_VUOSI,
") — ei yhtä 'tyypillistä' edustajaa, vaan jakauma"),
x = "Ikä", y = NULL) +
scale_y_continuous(breaks = NULL)
```
Yksi luku — vaikkapa keski-ikä — tiivistäisi tämän pisteeksi. Jakauma kertoo
enemmän: missä massa on, kuinka leveä haarukka on, ja onko se yksi- vai
kaksihuippuinen. Seuraavaksi katsomme, miten tämä jakauma on liikkunut sadassa
vuodessa.
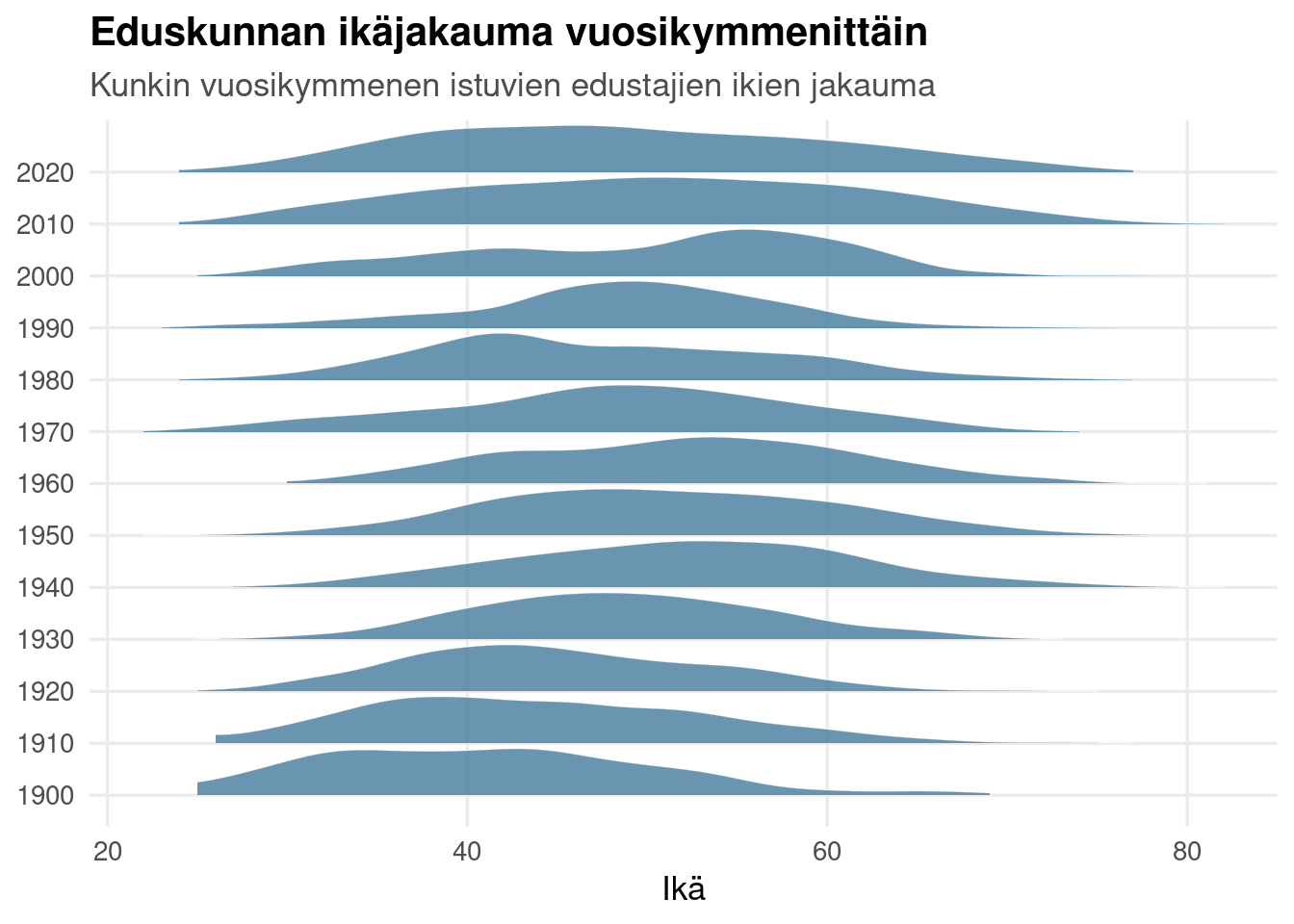
## Ikäjakauma ajassa
```{r ika-ridge}
ika_ts <- mp_years |>
filter(!is.na(ika)) |>
mutate(vk = (vuosi %/% 10) * 10) |>
filter(vk >= 1900, vk <= 2020)
ggplot(ika_ts, aes(x = ika, y = factor(vk))) +
stat_slab(normalize = "groups", fill = pal["sininen"],
alpha = .8, color = "white", linewidth = .2) +
labs(title = "Eduskunnan ikäjakauma vuosikymmenittäin",
subtitle = "Kunkin vuosikymmenen istuvien edustajien ikien jakauma",
x = "Ikä", y = NULL)
```
Tämä on koko sarjan idea yhtenä kuvana: emme katso yhtä lukua kymmeneltä
vuosikymmeneltä vaan kymmentä **jakaumaa**. Massan liike vasemmalta oikealle ja
jakauman leveyden muutos näkyvät heti — eikä kumpaakaan saisi näkyviin
keskiarvokäyrästä.
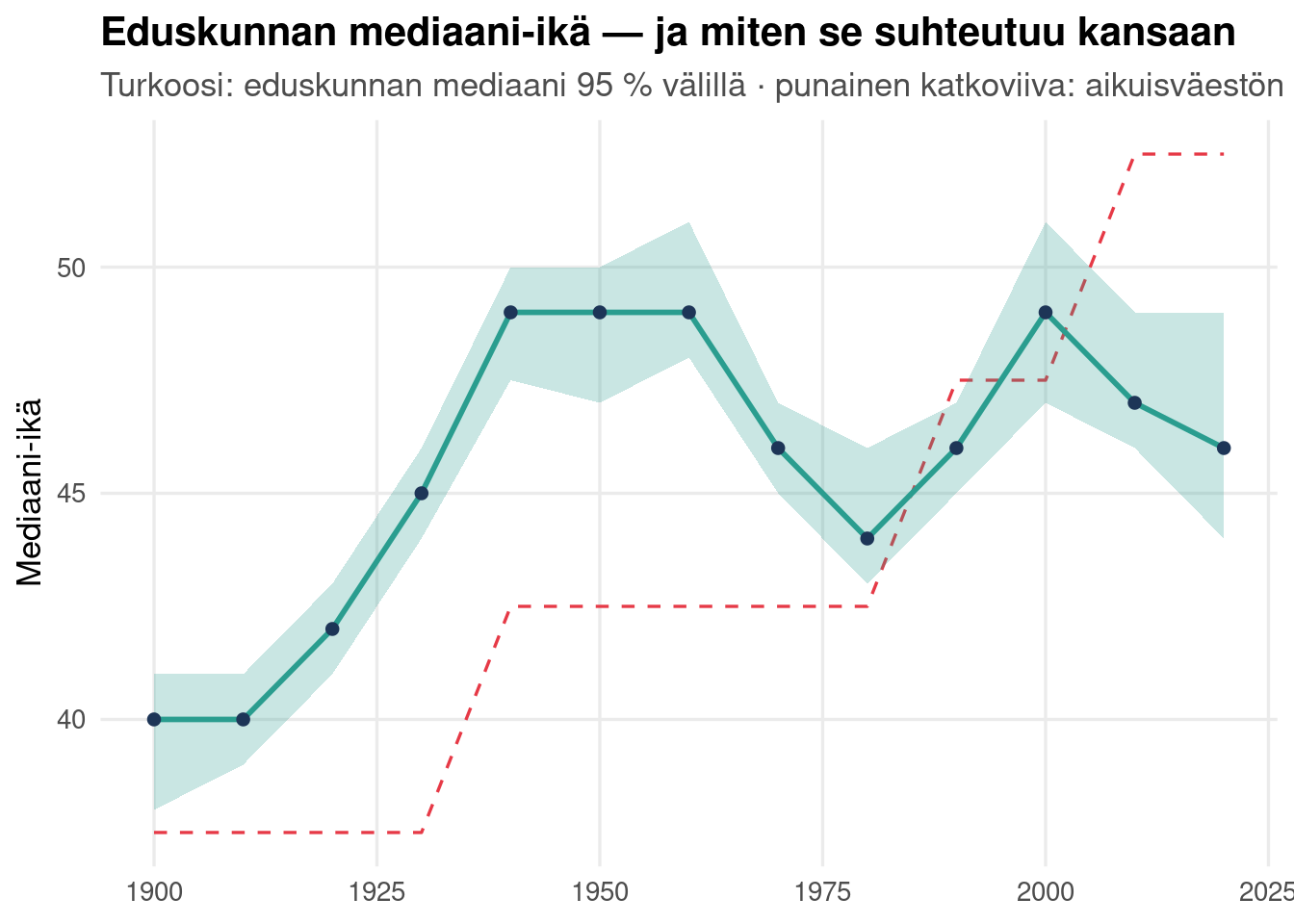
## Miten ikä on muuttunut
Tiivistetään muutos kahdella tavalla: **mediaani-ikä epävarmuusvälillä**
vuosikymmenittäin, ja vertailu **aikuisväestön (20+) mediaani-ikään**. Näin
näemme, onko eduskunta ikääntynyt itsessään, ja onko se ikääntynyt suhteessa
kansaan.
```{r ika-trendi}
# Eduskunnan mediaani-ikä vuosikymmenittäin, bootstrap-uskottavuusväli.
# HUOM: käytetään yksittäisiä henkilöitä vuosikymmenessä (ikä vuosikymmenen
# ensimmäisenä palvelusvuonna), jotta pitkään istuneet eivät paina toistoina.
hlo_vk <- mp_years |> filter(!is.na(ika)) |>
mutate(vk = (vuosi %/% 10) * 10) |>
group_by(henkilo_nro, vk) |> slice_min(vuosi, n = 1, with_ties = FALSE) |>
ungroup() |> filter(vk >= 1900, vk <= 2020)
boot_med <- function(x, B = 2000) {
m <- replicate(B, median(sample(x, replace = TRUE)))
tibble(med = median(x), lo = unname(quantile(m, .025)),
hi = unname(quantile(m, .975)))
}
mp_med <- hlo_vk |> group_by(vk) |> reframe(boot_med(ika))
# Aikuisväestön (20+) mediaani-ikä vuosikymmenittäin (painotettu mediaani
# luokkien keskipisteistä; 85- -> 88).
wmedian <- function(values, w) {
o <- order(values); values <- values[o]; w <- w[o]
values[which(cumsum(w) / sum(w) >= 0.5)[1]]
}
vaesto_med <- vaesto |>
mutate(mid = if_else(ika_alaraja >= 85, 88, ika_alaraja + 2.5),
vk = (vuosi %/% 10) * 10) |>
filter(vk >= 1900, vk <= 2020) |>
group_by(vk) |>
summarise(pop_med = wmedian(mid, n), .groups = "drop")
ggplot(mp_med, aes(x = vk, y = med)) +
geom_line(data = vaesto_med, aes(y = pop_med), color = pal["punainen"],
linetype = "dashed") +
geom_ribbon(aes(ymin = lo, ymax = hi), fill = pal["turkoosi"], alpha = .25) +
geom_line(color = pal["turkoosi"], linewidth = 1) +
geom_point(color = pal["laivasto"]) +
labs(title = "Eduskunnan mediaani-ikä — ja miten se suhteutuu kansaan",
subtitle = "Turkoosi: eduskunnan mediaani 95 % välillä · punainen katkoviiva: aikuisväestön (20+) mediaani",
x = NULL, y = "Mediaani-ikä")
```
```{r ika-testi}
# Muodollinen ryhmäerotesti: ensimmäinen vs. viimeinen vuosikymmen.
# Yksittäiset henkilöt (ei toistoja) -> Wilcoxonin rank-sum + rank-biserial efektikoko.
vk_min <- min(hlo_vk$vk); vk_max <- max(hlo_vk$vk)
a1 <- hlo_vk$ika[hlo_vk$vk == vk_min]
a2 <- hlo_vk$ika[hlo_vk$vk == vk_max]
wt <- suppressWarnings(wilcox.test(a1, a2))
rank_biserial <- 1 - 2 * unname(wt$statistic) / (length(a1) * length(a2))
tibble(vuosikymmen_1 = vk_min, mediaani_1 = median(a1),
vuosikymmen_2 = vk_max, mediaani_2 = median(a2),
p = signif(wt$p.value, 3), rank_biserial = round(rank_biserial, 3))
```
::: {.callout-note title="Miksi Wilcoxon ja yksittäiset henkilöt?"}
Vertaamme kahden vuosikymmenen **ikäjakaumia**, emme keskiarvoja, joten
jakaumavapaalla Wilcoxonin testillä on perusteltua. Käytämme kustakin edustajasta
yhtä havaintoa vuosikymmenessä, koska sama henkilö istuu monena vuonna — muuten
pitkät urat tuottaisivat näennäistoistoa ja liioittelisivat merkitsevyyttä.
Efektikoko (rank-biserial) kertoo eron suuruuden, joka on tulkinnan kannalta
olennaisempi kuin p-arvo.
:::
## Ammatit: mistä eduskuntaan tullaan
Ammattikenttä on sotkuinen: yhdellä edustajalla voi olla useita ammatteja pilkulla
eroteltuna, ja sama ammatti on kirjoitettu monella tavalla ("Everstiluutnantti evp",
"everstiluutnantti evp.", "everstiluutnantti"). Siivoamme tämän ennen laskentaa:
puramme pilkut omiksi riveiksi ja normalisoimme kirjoitusasun.
```{r ammatti-siivous}
normalisoi_ammatti <- function(x) {
x |> str_to_lower() |>
str_replace_all("[.,;:()]", " ") |>
str_replace_all("\\bevp\\b", " ") |> # eronnut vakinaisesta palveluksesta
str_replace_all("\\bev\\s*p\\b", " ") |>
str_squish()
}
# Itsevarmistus juuri ongelmaesimerkillä: kolmen variantin pitää yhdistyä yhdeksi.
stopifnot("Ammatin normalisointi ei yhdistä evp-variantteja" =
length(unique(normalisoi_ammatti(
c("Everstiluutnantti evp", "everstiluutnantti evp.", "everstiluutnantti")))) == 1)
amm_long <- mp |> filter(!is.na(ammatti)) |>
tidyr::separate_rows(ammatti, sep = ",") |>
mutate(ammatti_norm = normalisoi_ammatti(ammatti)) |>
filter(ammatti_norm != "") |>
distinct(henkilo_nro, ammatti_norm)
stopifnot("Ammattirivit tyhjät" = nrow(amm_long) > 1000)
```
::: {.callout-warning title="Mitä siivous tekee — ja mitä ei"}
Normalisointi yhdistää saman ammatin **kirjoitusasun** vaihtelut (kirjainkoko,
välimerkit, "evp"-lisä). Se **ei** yhdistä eri sanoja, jotka tarkoittavat lähes
samaa (esim. "maanviljelijä", "agronomi", "maanviljelysneuvos"). Tällainen
**semanttinen** yhdistäminen on tulkintaa, joka kuuluu omaan osaansa — emme tee
sitä hiljaa tässä, koska se vaikuttaisi tuloksiin näkymättömästi.
:::
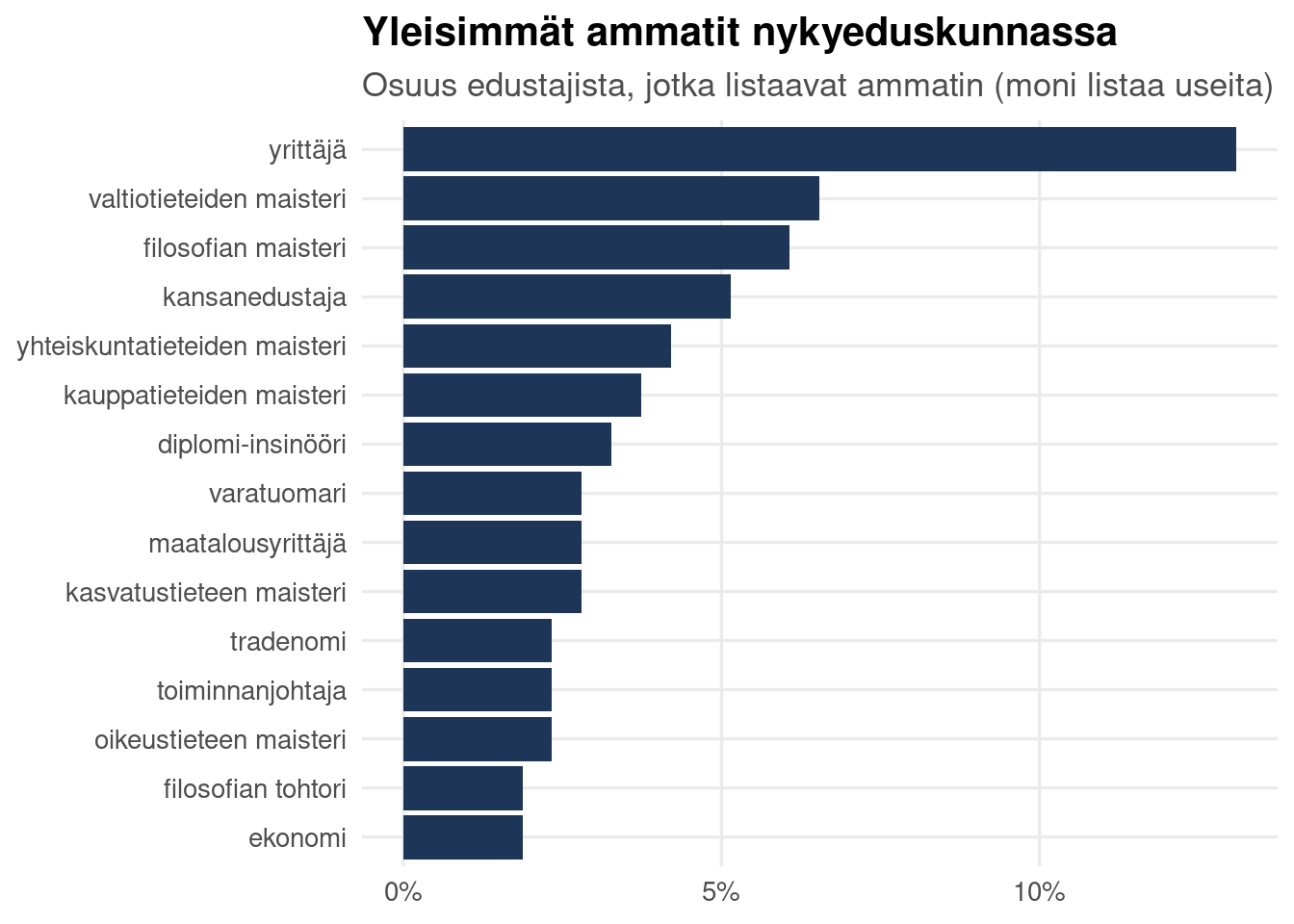
### Ammatit nykyeduskunnassa
```{r ammatti-nyt}
amm_nyt <- amm_long |> semi_join(nyt, by = "henkilo_nro")
n_nyt <- n_distinct(nyt$henkilo_nro)
top_nyt <- amm_nyt |> count(ammatti_norm, sort = TRUE) |>
slice_head(n = 15) |> mutate(osuus = n / n_nyt)
ggplot(top_nyt, aes(x = osuus, y = fct_reorder(ammatti_norm, osuus))) +
geom_col(fill = pal["laivasto"]) +
scale_x_continuous(labels = label_percent()) +
labs(title = "Yleisimmät ammatit nykyeduskunnassa",
subtitle = "Osuus edustajista, jotka listaavat ammatin (moni listaa useita)",
x = NULL, y = NULL)
```
### Ammattien muutos ajassa
```{r ammatti-trendi}
# Henkilö-vuosikymmen, ammatti kytketään kaikkiin palveltuihin vuosikymmeniin.
hlo_vk_all <- mp_years |> mutate(vk = (vuosi %/% 10) * 10) |>
distinct(henkilo_nro, vk) |> filter(vk >= 1900, vk <= 2020)
mp_per_vk <- hlo_vk_all |> count(vk, name = "n_mp")
# Seurataan kuutta yleisintä ammattia koko ajalta.
top6 <- amm_long |> count(ammatti_norm, sort = TRUE) |>
slice_head(n = 6) |> pull(ammatti_norm)
amm_trendi <- hlo_vk_all |>
inner_join(amm_long, by = "henkilo_nro", relationship = "many-to-many") |>
filter(ammatti_norm %in% top6) |>
count(vk, ammatti_norm) |>
left_join(mp_per_vk, by = "vk") |>
mutate(osuus = n / n_mp)
#Lisäväri
amm_varit <- c(unname(pal), "#8d6e9c") # 6. väri (pehmeä violetti) kuudennelle ammatille
ggplot(amm_trendi, aes(x = vk, y = osuus, color = ammatti_norm)) +
geom_line(linewidth = 1) + geom_point(size = 1.3) +
scale_y_continuous(labels = label_percent()) +
scale_color_manual(values = unname(amm_varit)) +
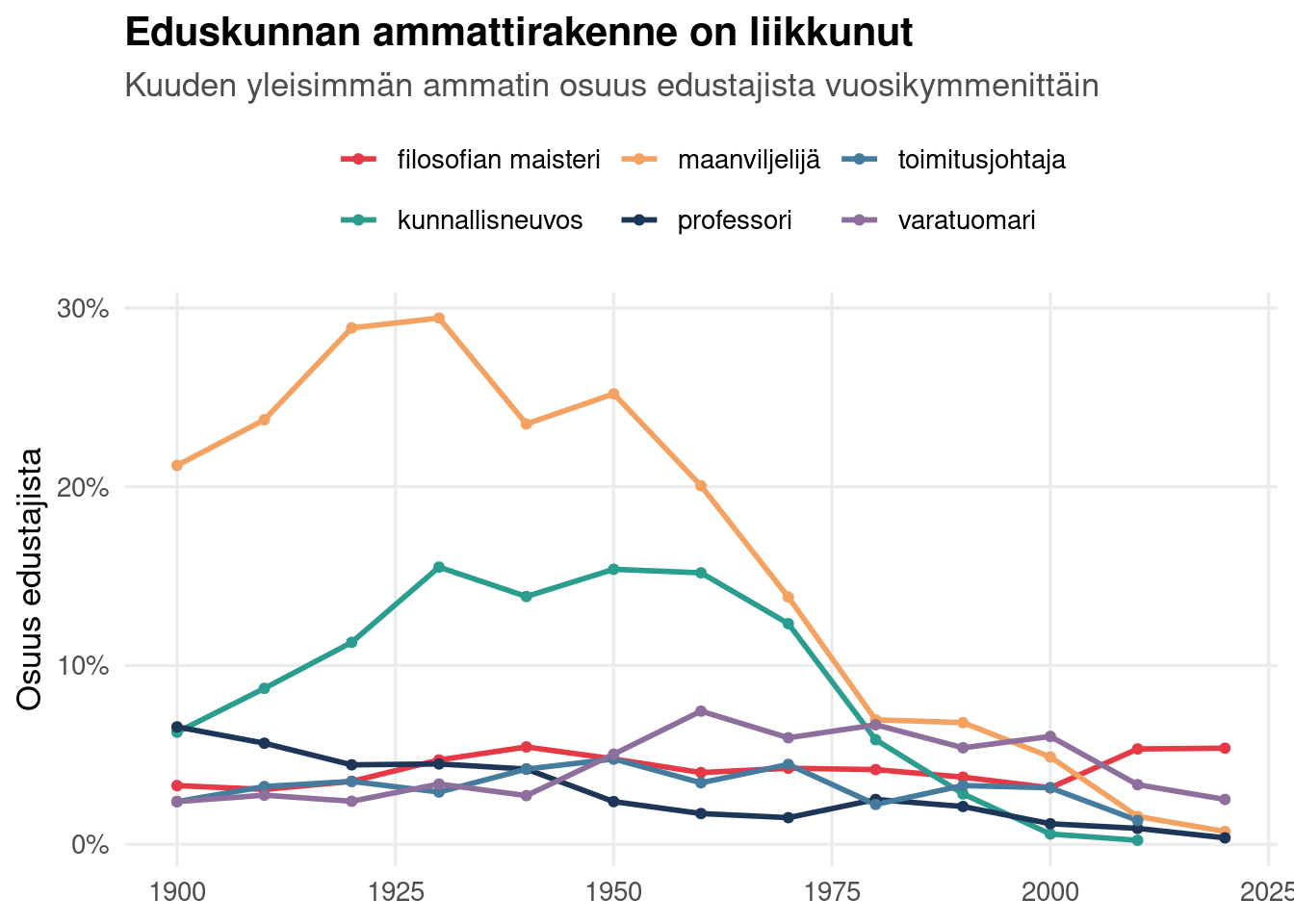
labs(title = "Eduskunnan ammattirakenne on liikkunut",
subtitle = "Kuuden yleisimmän ammatin osuus edustajista vuosikymmenittäin",
x = NULL, y = "Osuus edustajista")
```
Ammattirakenteen muutos on tarina itsessään: mitkä taustat ovat kadonneet salista
ja mitkä nousseet. Tämä on myös silta sarjan myöhempiin osiin — kun tarkastelemme,
mitä edustajat *tekevät*, voimme kysyä, ennustaako tausta toimintaa.
## Mitataan edustavuus: poikkeaako eduskunta väestöstä?
Verrataan vielä nykyeduskunnan sukupuoli- ja ikäjakaumaa väestöön **yhden otoksen
yhteensopivuustestillä** (chi-square goodness-of-fit). Efektikokona Cohenin w
(0.1 pieni, 0.3 kohtalainen, 0.5 suuri).
::: {.callout-important title="Testin valinta ja tulkinta — rehellisesti"}
GOF-testi vertaa yhtä ryhmää (eduskunta) tunnettuun vertailujakaumaan (väestö).
Kansanedustajat eivät ole satunnaisotos vaan valittu joukko, joten p-arvo ei
mittaa otantavirhettä tavanomaisessa mielessä — tulkitsemme sen poikkeaman
suuruuden mittarina ja painotamme efektikokoa. Vertaamme 20+ väestöön, koska
StatFinin 5-vuotisluokat alkavat luokasta 20–24.
:::
```{r testi-sukupuoli}
vaesto_ref <- vaesto |> filter(vuosi == REF_VUOSI)
nais_osuus_vaesto <- with(vaesto_ref, sum(n[sukupuoli == "Naiset"]) / sum(n))
sp <- nyt |> filter(!is.na(sukupuoli)) |> count(sukupuoli)
k <- sp$n[sp$sukupuoli == "Nainen"]; n_tot <- sum(sp$n)
obs <- c(naiset = k, miehet = n_tot - k)
exp_p <- c(naiset = nais_osuus_vaesto, miehet = 1 - nais_osuus_vaesto)
khi_sp <- chisq.test(obs, p = exp_p)
w_sp <- sqrt(unname(khi_sp$statistic) / n_tot)
tibble(naiset_eduskunta = k / n_tot, naiset_vaesto = nais_osuus_vaesto,
khi2 = unname(khi_sp$statistic), df = unname(khi_sp$parameter),
p = khi_sp$p.value, cohen_w = w_sp) |>
mutate(across(where(is.numeric), \(x) round(x, 3)))
```
```{r testi-ika}
ed_ika <- nyt |> mutate(ika_alaraja = pmin((ika %/% 5) * 5, 85)) |>
filter(ika_alaraja >= 20) |> count(ika_alaraja, name = "havaittu")
va_ika <- vaesto_ref |> group_by(ika_alaraja) |>
summarise(n = sum(n), .groups = "drop") |> mutate(osuus = n / sum(n))
vrt <- ed_ika |> right_join(va_ika |> select(ika_alaraja, osuus),
by = "ika_alaraja") |>
mutate(havaittu = replace_na(havaittu, 0))
stopifnot("Ikäluokat eivät täsmää" = nrow(vrt) == nrow(va_ika))
khi_ika <- chisq.test(x = vrt$havaittu, p = vrt$osuus, rescale.p = TRUE)
w_ika <- sqrt(unname(khi_ika$statistic) / sum(vrt$havaittu))
list(khi2 = round(unname(khi_ika$statistic), 2), df = unname(khi_ika$parameter),
p = signif(khi_ika$p.value, 3), cohen_w = round(w_ika, 3))
```
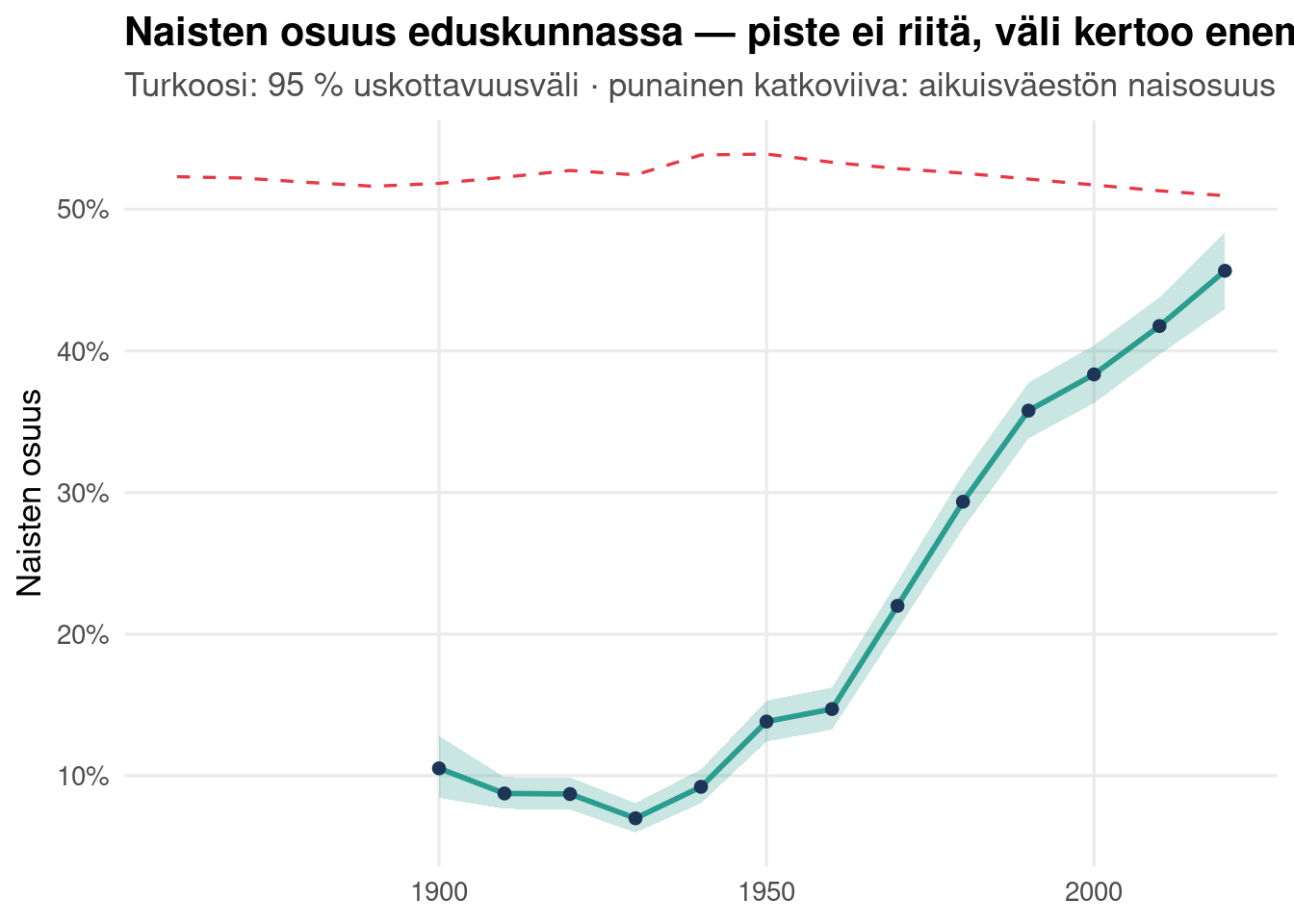
## Epävarmuus näkyviin: naisten osuuden trendi
```{r bayes-trendi}
trendi <- mp_years |> filter(!is.na(sukupuoli)) |>
mutate(vk = (vuosi %/% 10) * 10) |>
group_by(vk) |>
summarise(n = n(), naiset = sum(sukupuoli == "Nainen"), .groups = "drop") |>
filter(n >= 20) |>
mutate(a = 1 + naiset, b = 1 + (n - naiset),
keski = a / (a + b), lo = qbeta(.025, a, b), hi = qbeta(.975, a, b))
vaesto_nais_vk <- vaesto |> mutate(vk = (vuosi %/% 10) * 10) |>
group_by(vk) |>
summarise(osuus = sum(n[sukupuoli == "Naiset"]) / sum(n), .groups = "drop")
ggplot(trendi, aes(x = vk, y = keski)) +
geom_line(data = vaesto_nais_vk, aes(y = osuus), color = pal["punainen"],
linetype = "dashed") +
geom_ribbon(aes(ymin = lo, ymax = hi), fill = pal["turkoosi"], alpha = .25) +
geom_line(color = pal["turkoosi"], linewidth = 1) +
geom_point(color = pal["laivasto"]) +
scale_y_continuous(labels = label_percent()) +
labs(title = "Naisten osuus eduskunnassa — piste ei riitä, väli kertoo enemmän",
subtitle = "Turkoosi: 95 % uskottavuusväli · punainen katkoviiva: aikuisväestön naisosuus",
x = NULL, y = "Naisten osuus")
```
## Mitä tämä tarkoittaa päättäjälle
- **Eduskunta ei ole väestön pienoiskuva** — ei iältään, sukupuoleltaan eikä
ammattitaustaltaan — ja poikkeaman suuruus on mitattavissa, ei mielipide.
- **Muutos on jakauman muutos.** Ikä, naisosuus ja ammattirakenne ovat liikkuneet
sadassa vuodessa tavalla, jota yksikään yksittäinen luku ei tavoita.
- **Tämä on lähtötaso.** Kun seuraavissa osissa siirrymme siihen, mitä edustajat
*tekevät*, tiedämme jo keitä he ovat — ja voimme kysyä, ennustaako tausta
toimintaa.
## Uutiskoukku takaisin
Kun vuoden 2027 ehdokasgalleriat seuraavan kerran vilahtavat uutisissa, sinulla
on nyt toinen tapa katsoa niitä: et yhtä mielikuvaa, vaan jakauman — ikä, sukupuoli
ja ammatti — ja sen etäisyyden siihen Suomeen, jota sen on määrä edustaa.
---
::: {.callout-tip title="Tehdäänkö teidän datallenne sama?"}
Rakennan organisaatioille analytiikkaa, joka korvaa pistearviot jakaumilla ja
epävarmuuden mittaamisella — siellä missä päätökset oikeasti tehdään. Jos
lending-, compliance-, juridiikan tai julkishallinnon päätöksenne nojaavat
yksittäisiin lukuihin, otetaan yhteyttä: **kristianvepsalainen.com**.
:::
*Datalähteet: Eduskunnan avoin data (CC BY 4.0) ja Tilastokeskus, StatFin (11rc).
Analyysi ja mahdolliset virheet ovat omiani.*