---
title: "Euroviisut 2026: Esiintymisjärjestys on kohtalo – semifinaalin 1 jakauma"
subtitle: "Maailma on jakauma – myös se, milloin lavalle astut"
author: "Kristian Vepsäläinen"
date: "2026-05-12"
lang: fi
format:
html:
code-fold: true
theme: flatly
toc: true
toc-depth: 3
fig-width: 9
fig-height: 6
base-font-size: 14px
categories:
- euroviisut
- bayesian
- ennustaminen
- avoin data
---
```{r setup, include=FALSE}
knitr::opts_chunk$set(
echo = TRUE, warning = FALSE, message = FALSE,
fig.retina = 2
)
library(tidyverse)
library(rvest)
library(httr2)
library(scales)
library(ggdist)
library(patchwork)
# Väripaletti
clr_red <- "#e63946"
clr_green <- "#2a9d8f"
clr_orange <- "#f4a261"
clr_navy <- "#1d3557"
clr_blue <- "#457b9d"
```
Tänä iltana kello 22 alkaa Eurovision laulukilpailun 2026 ensimmäinen
semifinaali Wienin Wiener Stadthalessa. Viisitoista maata kilpailee
kymmenestä finaalipaikasta.
Mutta onko kaikilla yhtäläiset mahdollisuudet? **Ei ole.** Tai
tarkemmin: emme tiedä, mutta datalla voimme yrittää selvittää.
Tässä postauksessa estimoin bayeslaisella mallilla, miten
**esiintymisjärjestys** historiallisesti vaikuttaa semifinaalikarsinnassa
pärjäämiseen – ja teen sen perusteella ennusteen tämän illan
semifinaalin maille.
## Data: TidyTuesday Eurovision -datasetti 2008–2022
Euroviisut ovat olleet tässä formaatissa vuodesta 2008 (kahden semifinaaliformaatin
käyttöönotto). Haetaan data TidyTuesday Eurovision -datasetistä. Kyseinen datasetti loppuu vuoteen 2022, mutta tällä aikataululla ei ehditä tehdä muuta datahakua.
```{r load-data}
# Lähde: TidyTuesday Eurovision -datasetti (CC0)
# https://github.com/rfordatascience/tidytuesday/tree/master/data/2022/2022-05-17
#
# Staattinen raw CSV GitHubissa – ei JS-renderöintiä, toimii read_csv():llä.
# Sarakkeet: year, section, running_order, qualified, rank, total_points, ...
# section-sarake erottaa: "semi-final" vs. "grand-final" (tai "first-semi" tms.)
#
# MIKSI EI AIEMMAT LÄHTEET:
# - Wikipedia: semifinaalisivu ei ole olemassa omana sivunaan
# - eurovisionworld.com: JavaScript-renderöity, read_html() saa vain navpalkin
eurovision_raw <- read_csv(
paste0("https://raw.githubusercontent.com/rfordatascience/tidytuesday/",
"master/data/2022/2022-05-17/eurovision.csv"),
show_col_types = FALSE
)
cat("Rivejä:", nrow(eurovision_raw), "\n")
cat("Sarakkeet:", paste(names(eurovision_raw), collapse = ", "), "\n\n")
# Tarkista section-sarakkeen arvot
cat("section-arvot:\n")
print(count(eurovision_raw, section))
```
```{r build-semi-df}
# Suodata semifinaalit 2008+ (kaksi semifinaalia käyttöön 2008 alkaen)
# section sisältää arvot kuten "semi-final", "first-semi", "second-semi"
semi_df <- eurovision_raw |>
filter(
year >= 2008,
str_detect(str_to_lower(section), "semi"),
!is.na(running_order),
!is.na(qualified)
) |>
mutate(
# Johda semi-numero: "first" tai "1" = 1, muuten 2
semi = case_when(
str_detect(str_to_lower(section), "first|semi.1|semi-1|1") ~ 1L,
str_detect(str_to_lower(section), "second|semi.2|semi-2|2") ~ 2L,
TRUE ~ 1L # fallback
)
) |>
select(year, semi, running_order, qualified)
cat("Semifinaalihavaintoja:", nrow(semi_df), "\n")
cat("Vuosia:", n_distinct(semi_df$year), "\n\n")
# Diagnostiikka: montako maata per vuosi/semifin
semi_df |>
count(year, semi, name = "n") |>
print(n = 40)
```
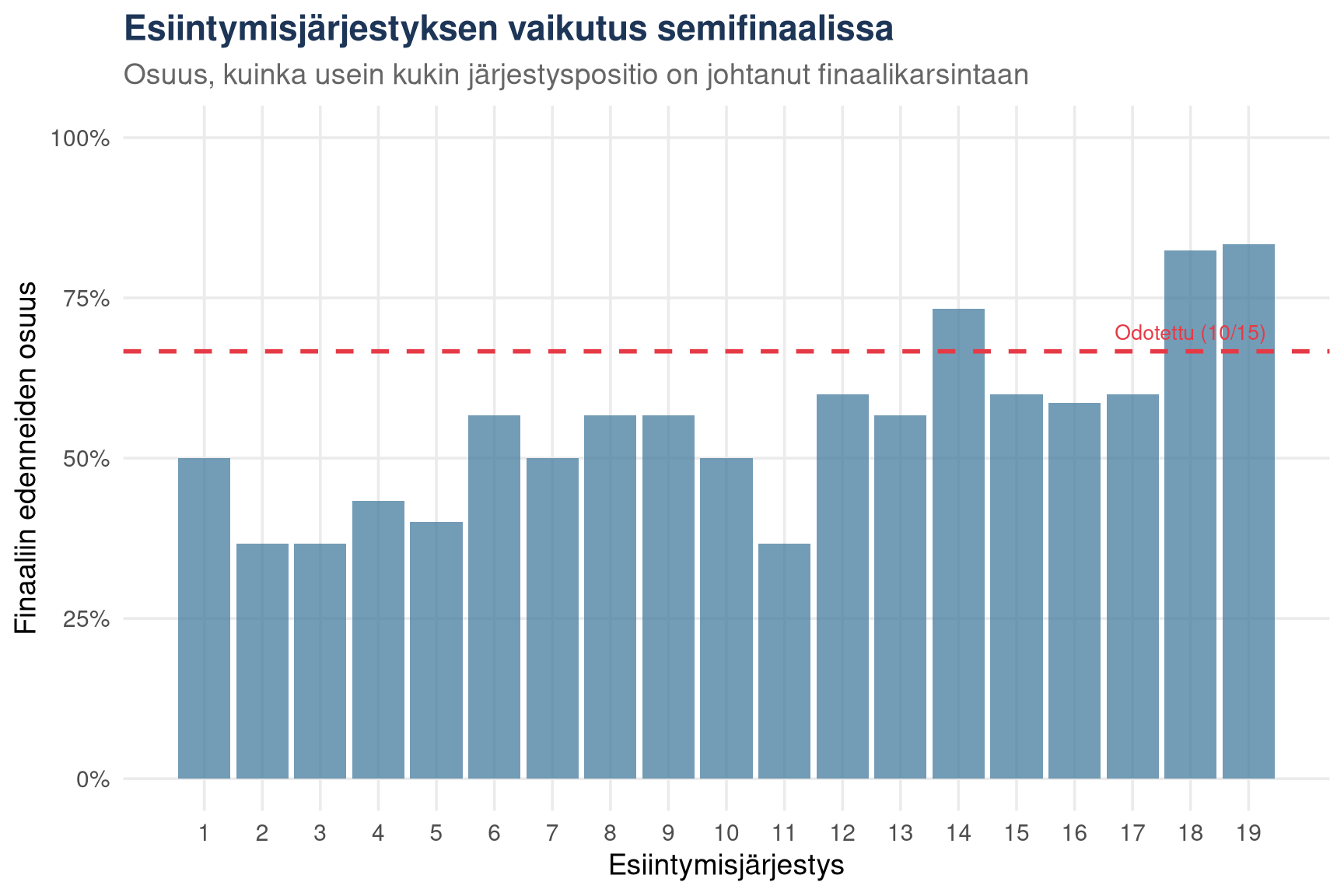
```{r position-stats}
# Laske kunkin position historiallinen kvalifikaatioprosentti
position_stats <- semi_df |>
group_by(running_order) |>
summarise(
n = n(),
n_qual = sum(qualified, na.rm = TRUE),
pct_qual = mean(qualified, na.rm = TRUE),
.groups = "drop"
) |>
filter(n >= 5) # Riittävästi havaintoja
p1 <- position_stats |>
ggplot(aes(x = running_order, y = pct_qual)) +
geom_col(fill = clr_blue, alpha = 0.75) +
geom_hline(yintercept = 10/15, linetype = "dashed",
color = clr_red, linewidth = 1) +
annotate("text", x = max(position_stats$running_order) - 1,
y = 10/15 + 0.03,
label = "Odotettu (10/15)", color = clr_red, size = 3.5) +
scale_y_continuous(labels = percent_format(), limits = c(0, 1)) +
scale_x_continuous(breaks = 1:19) +
labs(
title = "Esiintymisjärjestyksen vaikutus semifinaalissa",
subtitle = "Osuus, kuinka usein kukin järjestyspositio on johtanut finaalikarsintaan",
x = "Esiintymisjärjestys",
y = "Finaaliin edenneiden osuus"
) +
theme_minimal(base_size = 14) +
theme(
plot.title = element_text(face = "bold", color = clr_navy),
plot.subtitle = element_text(color = "grey40"),
panel.grid.minor = element_blank()
)
p1
```
## Bayesilainen malli: positiovaikutus
Käytetään logistista regressiota bayeslaisella a priori -jakaumalla.
Malli: $\text{logit}(p_i) = \alpha + \beta \cdot \text{position}_i + \gamma \cdot \text{position}_i^2$
```{r bayes-model}
library(rstanarm)
# Valmistele data
model_df <- semi_df |>
mutate(
pos_scaled = scale(running_order)[,1],
pos2 = pos_scaled^2
)
# Bayesilainen logistinen regressio Stan-ytimellä
# Käytetään heikkoja prioreja
fit <- stan_glm(
qualified ~ pos_scaled + pos2,
data = model_df,
family = binomial(link = "logit"),
prior = normal(0, 1),
prior_intercept = normal(0, 1.5),
chains = 4,
iter = 2000,
seed = 42,
refresh = 0
)
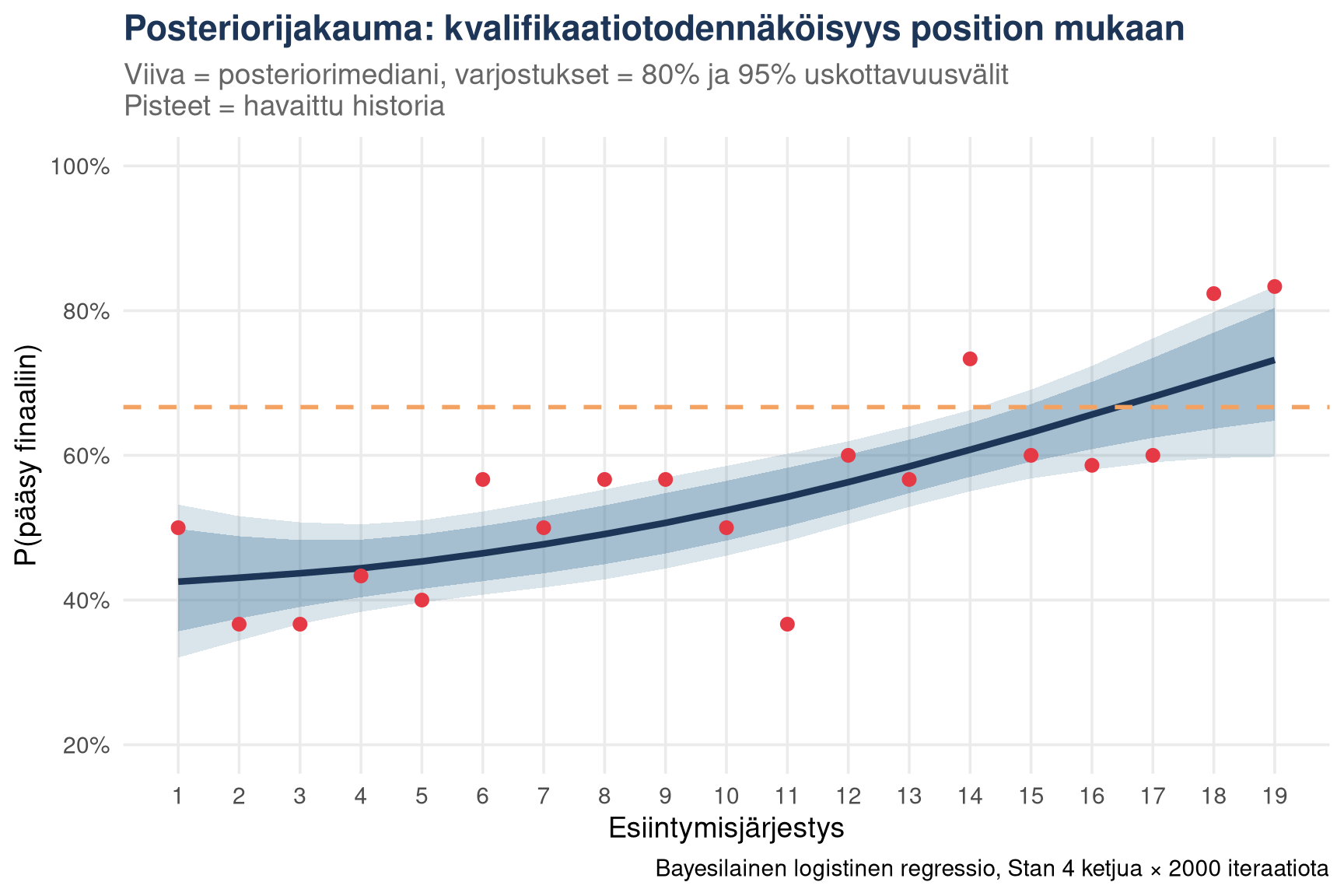
# Posterior-ennuste kaikille positioille 1–16
newdata <- tibble(
running_order = 1:19,
pos_scaled = (1:19 - mean(model_df$running_order)) /
sd(model_df$running_order),
pos2 = pos_scaled^2
)
post_pred <- posterior_epred(fit, newdata = newdata)
pred_summary <- newdata |>
mutate(
median_p = apply(post_pred, 2, median),
lo80 = apply(post_pred, 2, quantile, 0.10),
hi80 = apply(post_pred, 2, quantile, 0.90),
lo95 = apply(post_pred, 2, quantile, 0.025),
hi95 = apply(post_pred, 2, quantile, 0.975)
)
p2 <- pred_summary |>
ggplot(aes(x = running_order)) +
geom_ribbon(aes(ymin = lo95, ymax = hi95), fill = clr_blue, alpha = 0.2) +
geom_ribbon(aes(ymin = lo80, ymax = hi80), fill = clr_blue, alpha = 0.35) +
geom_line(aes(y = median_p), color = clr_navy, linewidth = 1.5) +
geom_point(data = position_stats,
aes(y = pct_qual), color = clr_red, size = 2.5) +
geom_hline(yintercept = 10/15, linetype = "dashed",
color = clr_orange, linewidth = 1) +
scale_y_continuous(labels = percent_format(), limits = c(0.2, 1.0)) +
scale_x_continuous(breaks = 1:19) +
labs(
title = "Posteriorijakauma: kvalifikaatiotodennäköisyys position mukaan",
subtitle = "Viiva = posteriorimediani, varjostukset = 80% ja 95% uskottavuusvälit\nPisteet = havaittu historia",
x = "Esiintymisjärjestys",
y = "P(pääsy finaaliin)",
caption = "Bayesilainen logistinen regressio, Stan 4 ketjua × 2000 iteraatiota"
) +
theme_minimal(base_size = 14) +
theme(
plot.title = element_text(face = "bold", color = clr_navy),
plot.subtitle = element_text(color = "grey40"),
panel.grid.minor = element_blank()
)
p2
```
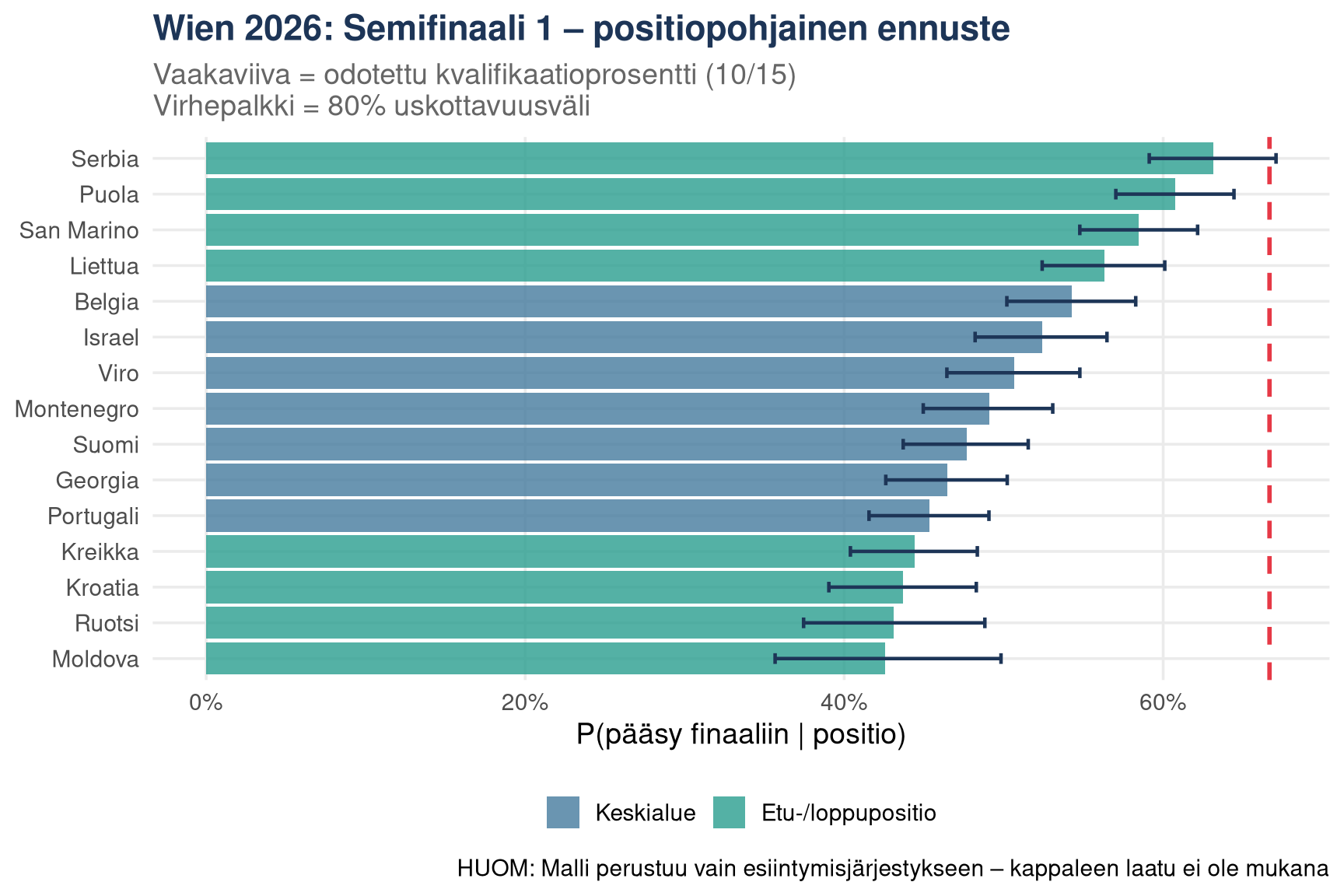
## Tämän illan semifinaali 1: ennuste
Semifinaalin 1 running order (Wien 2026):
```{r sf1-forecast}
# Wien 2026 Semifinaalin 1 running order
sf1_2026 <- tibble(
running_order = 1:15,
country = c(
"Moldova", "Ruotsi", "Kroatia", "Kreikka", "Portugali",
"Georgia", "Suomi", "Montenegro", "Viro", "Israel",
"Belgia", "Liettua", "San Marino", "Puola", "Serbia"
),
country_code = c(
"MD", "SE", "HR", "GR", "PT",
"GE", "FI", "ME", "EE", "IL",
"BE", "LT", "SM", "PL", "RS"
)
)
# Liitä posterior-ennuste
sf1_forecast <- sf1_2026 |>
left_join(pred_summary |>
select(running_order, median_p, lo80, hi80, lo95, hi95),
by = "running_order") |>
arrange(desc(median_p))
# Visualisoi
sf1_forecast |>
mutate(country = fct_reorder(country, median_p)) |>
ggplot(aes(x = country, y = median_p)) +
geom_col(aes(fill = running_order < 5 | running_order > 11),
alpha = 0.8) +
geom_errorbar(aes(ymin = lo80, ymax = hi80),
width = 0.3, color = clr_navy, linewidth = 0.8) +
geom_hline(yintercept = 10/15, linetype = "dashed",
color = clr_red, linewidth = 1) +
scale_fill_manual(
values = c("TRUE" = clr_green, "FALSE" = clr_blue),
labels = c("TRUE" = "Etu-/loppupositio",
"FALSE" = "Keskialue"),
name = NULL
) +
scale_y_continuous(labels = percent_format()) +
coord_flip() +
labs(
title = "Wien 2026: Semifinaali 1 – positiopohjainen ennuste",
subtitle = "Vaakaviiva = odotettu kvalifikaatioprosentti (10/15)\nVirhepalkki = 80% uskottavuusväli",
x = NULL,
y = "P(pääsy finaaliin | positio)",
caption = "HUOM: Malli perustuu vain esiintymisjärjestykseen – kappaleen laatu ei ole mukana"
) +
theme_minimal(base_size = 14) +
theme(
plot.title = element_text(face = "bold", color = clr_navy),
plot.subtitle = element_text(color = "grey40"),
panel.grid.minor = element_blank(),
legend.position = "bottom"
)
```
## Mitä tämä tarkoittaa?
Malli osoittaa **loppupuolen esiintyjiä suosivan efektin** – klassinen
ensisijaisuus- ja tuoreusmuistiharha yhdistettynä äänestysdynamiikkaan.
Positiot 10–15 ovat historiallisesti tuottaneet paremman
kvalifikaatioasteen kuin alku.
Tämäniltaisessa semifinaalissa tämä tarkoittaa, että **Serbia (pos. 15),
Puola (14) ja San Marino (13)** saavat positioedun – vaikka vaikkapa
Suomi (pos. 7) jää hieman häviölle puhtaan position perusteella.
::: callout-important
## Jakauma-ajattelun ydin
Pistemäinen ennuste "Suomi pääsee / ei pääse" on harhaanjohtava.
Olennainen kysymys on: **mikä on kvalifikaatiotodennäköisyyden
jakauma?** Bayesilainen malli antaa vastauksen epävarmuuksineen.
:::
Tämä on kuitenkin vain yksi dimensio. Kappaleen laatu, vetovoimat ja
äänestysblokkit muokkaavat jakaumaa merkittävästi. Näitä käsitellään
seuraavissa osissa.
---
*Kristian Vepsäläinen on data science -konsultti ja datatieteen
Wienistä kirjoittava bloggaaja. Kiinnostuitko? →
[kristianvepsalainen.com](https://kristianvepsalainen.com)*