---
title: "Euroviisut 2026: Äänestysverkosto on jakauma – kuka äänestää ketä?"
subtitle: "Blokkiäänestyksen rakenne, naapuruuskorrelaaatiot ja Dirichlet-malli"
author: "Kristian Vepsäläinen"
date: "2026-05-14"
lang: fi
format:
html:
code-fold: true
theme: flatly
toc: true
toc-depth: 3
fig-width: 9
fig-height: 7
base-font-size: 14px
categories:
- euroviisut
- bayesian
- verkostoanalyysi
- avoin data
---
```{r setup, include=FALSE}
knitr::opts_chunk$set(echo = TRUE, warning = FALSE, message = FALSE, fig.retina = 2)
library(tidyverse)
library(scales)
library(corrplot)
library(igraph)
library(ggraph)
library(tidygraph)
clr_red <- "#e63946"
clr_green <- "#2a9d8f"
clr_orange <- "#f4a261"
clr_navy <- "#1d3557"
clr_blue <- "#457b9d"
```
Tänä iltana kello 22 alkaa toinen semifinaali. Eilen katsoimme
positioefektejä. Tänään kysymys on syvempi: **kenen ääni on
painokkaampi – ja kenelle?**
Euroviisut on äänestysverkosto. Jokainen osallistujamaa äänestää, mutta
ei omaa maataan. Tuloksena on painotettu suunnattu verkko, jossa
**naapuruus, kielialue ja diaspora** luovat systemaattisia kuvioita.
## Data: TidyTuesday Eurovision-äänestysdata
```{r load-data}
# Lähde: TidyTuesday Eurovision -datasetti (CC0)
# https://github.com/rfordatascience/tidytuesday/tree/master/data/2022/2022-05-17
#
# eurovision-votes.csv – maa-maa-äänestysdata
# Sarakkeet: year, semi_final, edition, jury_or_televoting,
# from_country, to_country, points, duplicate
#
# Tämä on staattinen raw-CSV GitHubissa – ei JS-renderöintiä.
base_url <- paste0("https://raw.githubusercontent.com/rfordatascience/",
"tidytuesday/master/data/2022/2022-05-17/")
votes_raw <- read_csv(paste0(base_url, "eurovision-votes.csv"),
show_col_types = FALSE)
cat("Rivejä:", nrow(votes_raw), "\n")
cat("Sarakkeet:", paste(names(votes_raw), collapse = ", "), "\n\n")
# Diagnostiikka: näytetään avainmuuttujien arvot
cat("semi_final-sarakkeen arvot:\n")
print(count(votes_raw, semi_final))
```
```{r prep-votes}
# Suodata: finaalit (semi_final == "f"), vuodesta 2010+
# Normalisoidaan myös maanimi: "The Netherlands" → "Netherlands"
votes_final <- votes_raw |>
filter(
semi_final == "f",
year >= 2010,
!is.na(points)
) |>
mutate(
from_country = str_replace(from_country, "^The Netherlands$", "Netherlands"),
to_country = str_replace(to_country, "^The Netherlands$", "Netherlands")
)
# duplicate-sarake on chr: "x" = duplikaatti, NA = ei duplikaatti
if ("duplicate" %in% names(votes_final)) {
votes_final <- filter(votes_final, duplicate != "x" | is.na(duplicate))
}
# Aggregoi: kuinka paljon A on antanut B:lle (kaikki vuodet yhteensä)
vote_summary <- votes_final |>
group_by(from_country, to_country) |>
summarise(
total_pts = sum(points, na.rm = TRUE),
n_years = n_distinct(year),
avg_pts = mean(points, na.rm = TRUE),
n_12pts = sum(points == 12, na.rm = TRUE),
.groups = "drop"
) |>
filter(n_years >= 3) # vähintään 3 yhteistä finaalivuotta
cat("Äänestyspareja (≥ 3 vuotta yhdessä finaalissa):", nrow(vote_summary), "\n")
```
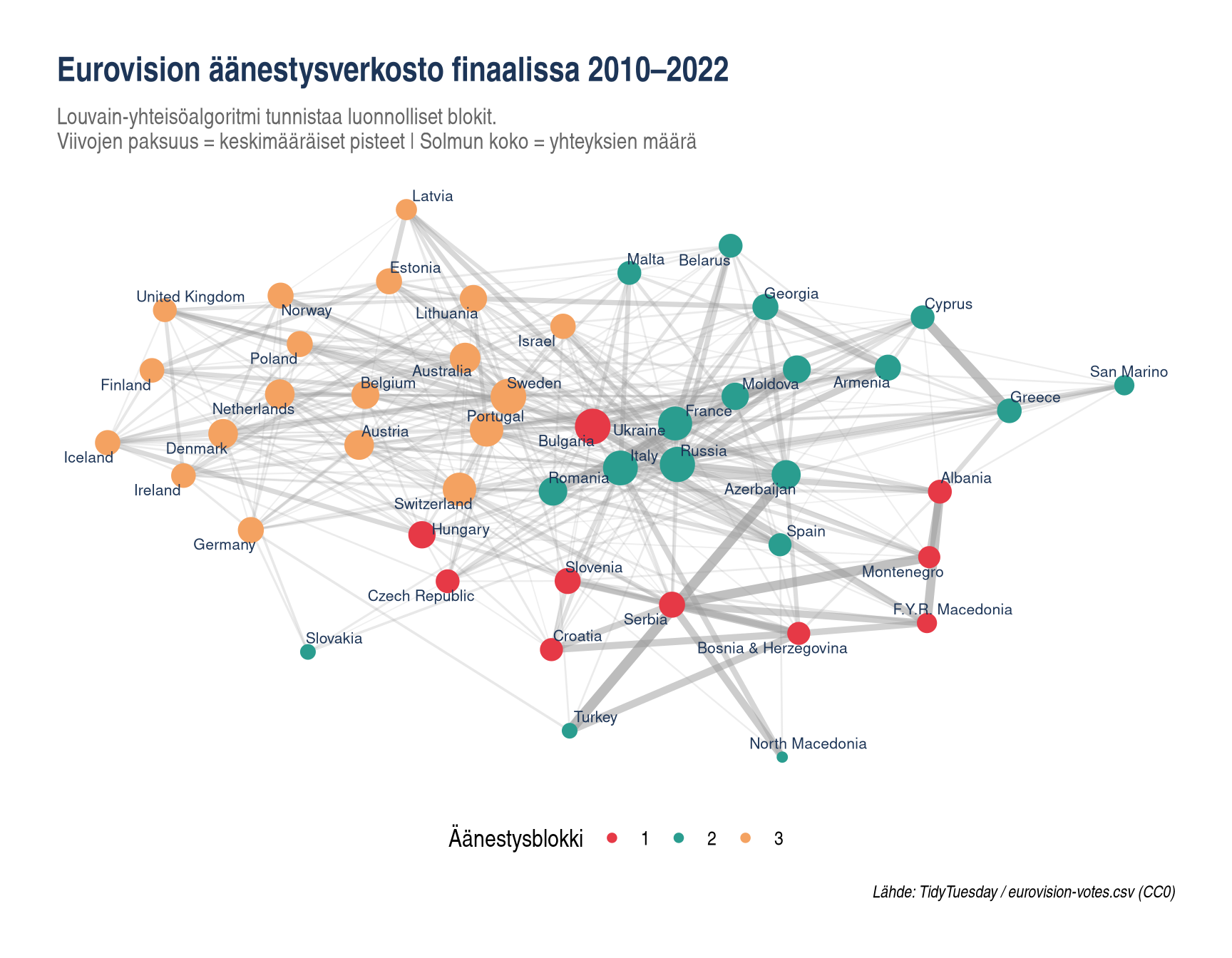
## Äänestysverkosto: Louvain-yhteisöalgoritmi
```{r network-viz}
# iGraph: suunnattu verkko merkittävistä äänestyssuhteista
# HUOM: graph_from_data_frame() ottaa kaikki sarakkeet kaarien attribuuteiksi.
# as.undirected() + as_tbl_graph() kaatuu jos attribuutit eivät yhdisty
# siististi (tuottaa NULL-sarakkeita). Ratkaisu: valitaan vain avg_pts.
g_dir <- vote_summary |>
filter(avg_pts >= 3) |>
select(from_country, to_country, avg_pts) |> # vain tarvittavat sarakkeet
graph_from_data_frame(directed = TRUE)
# Symmetrinen versio Louvain-algoritmia varten
g_und <- as.undirected(g_dir, mode = "collapse",
edge.attr.comb = list(avg_pts = "mean"))
set.seed(42)
communities <- cluster_louvain(g_und)
V(g_und)$community <- membership(communities)
cat("Louvain löysi", max(membership(communities)), "äänestysyhteisöä\n")
# tidygraph-visualisointi
tg <- as_tbl_graph(g_und) |>
activate(nodes) |>
mutate(
degree = centrality_degree(mode = "all"),
community = as.factor(V(g_und)$community)
)
bloc_colors <- c(clr_red, clr_green, clr_orange, clr_blue, clr_navy,
"#9b2226", "#606c38", "#8338ec")
ggraph(tg, layout = "fr") +
geom_edge_link(aes(width = avg_pts, alpha = avg_pts),
color = "grey60", show.legend = FALSE) +
geom_node_point(aes(size = degree, color = community),
show.legend = c(size = FALSE, color = TRUE)) +
geom_node_text(aes(label = name), repel = TRUE, size = 2.8,
color = clr_navy, max.overlaps = 25) +
scale_edge_width(range = c(0.3, 2.5)) +
scale_edge_alpha(range = c(0.15, 0.65)) +
scale_size(range = c(2, 8)) +
scale_color_manual(values = bloc_colors, name = "Äänestysblokki") +
labs(
title = "Eurovision äänestysverkosto finaalissa 2010–2022",
subtitle = paste0(
"Louvain-yhteisöalgoritmi tunnistaa luonnolliset blokit.\n",
"Viivojen paksuus = keskimääräiset pisteet | Solmun koko = yhteyksien määrä"
),
caption = "Lähde: TidyTuesday / eurovision-votes.csv (CC0)"
) +
theme_graph(base_size = 13) +
theme(
plot.title = element_text(face = "bold", color = clr_navy),
plot.subtitle = element_text(color = "grey40"),
legend.position = "bottom"
)
```
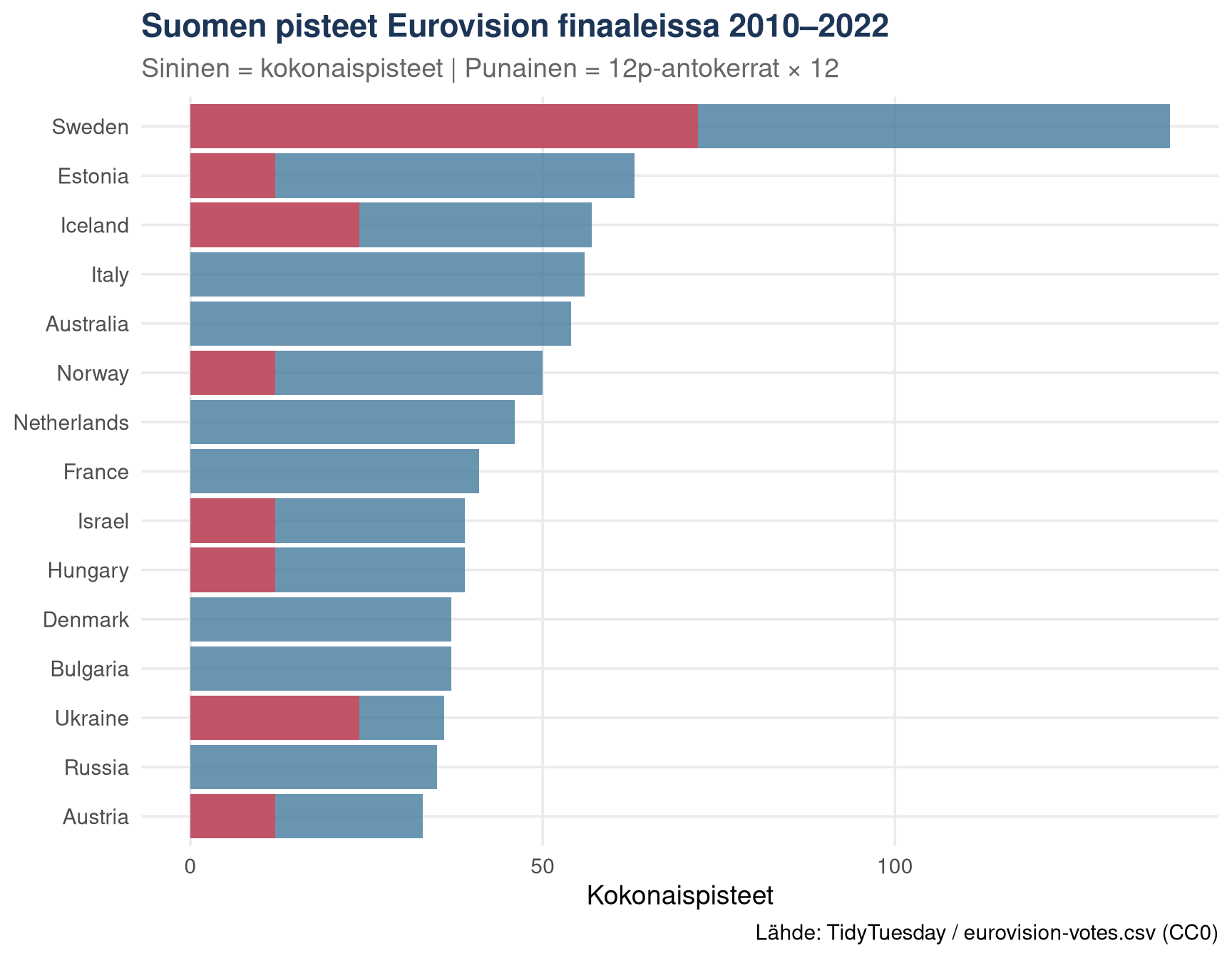
## Suomi äänestäjänä: minne pisteet menevät?
```{r finland-votes}
fi_votes <- votes_final |>
filter(from_country == "Finland") |>
group_by(to_country) |>
summarise(
yht_pisteet = sum(points, na.rm = TRUE),
n_12pts = sum(points == 12, na.rm = TRUE),
n_vuotta = n_distinct(year),
.groups = "drop"
) |>
arrange(desc(yht_pisteet)) |>
slice_head(n = 15)
fi_votes |>
mutate(to_country = fct_reorder(to_country, yht_pisteet)) |>
ggplot(aes(x = to_country, y = yht_pisteet)) +
geom_col(fill = clr_blue, alpha = 0.8) +
geom_col(
data = fi_votes |>
filter(n_12pts > 0) |>
mutate(to_country = fct_reorder(to_country, yht_pisteet)),
aes(y = n_12pts * 12),
fill = clr_red, alpha = 0.7
) +
coord_flip() +
labs(
title = "Suomen pisteet Eurovision finaaleissa 2010–2022",
subtitle = "Sininen = kokonaispisteet | Punainen = 12p-antokerrat × 12",
x = NULL,
y = "Kokonaispisteet",
caption = "Lähde: TidyTuesday / eurovision-votes.csv (CC0)"
) +
theme_minimal(base_size = 14) +
theme(
plot.title = element_text(face = "bold", color = clr_navy),
plot.subtitle = element_text(color = "grey40"),
panel.grid.minor = element_blank()
)
```
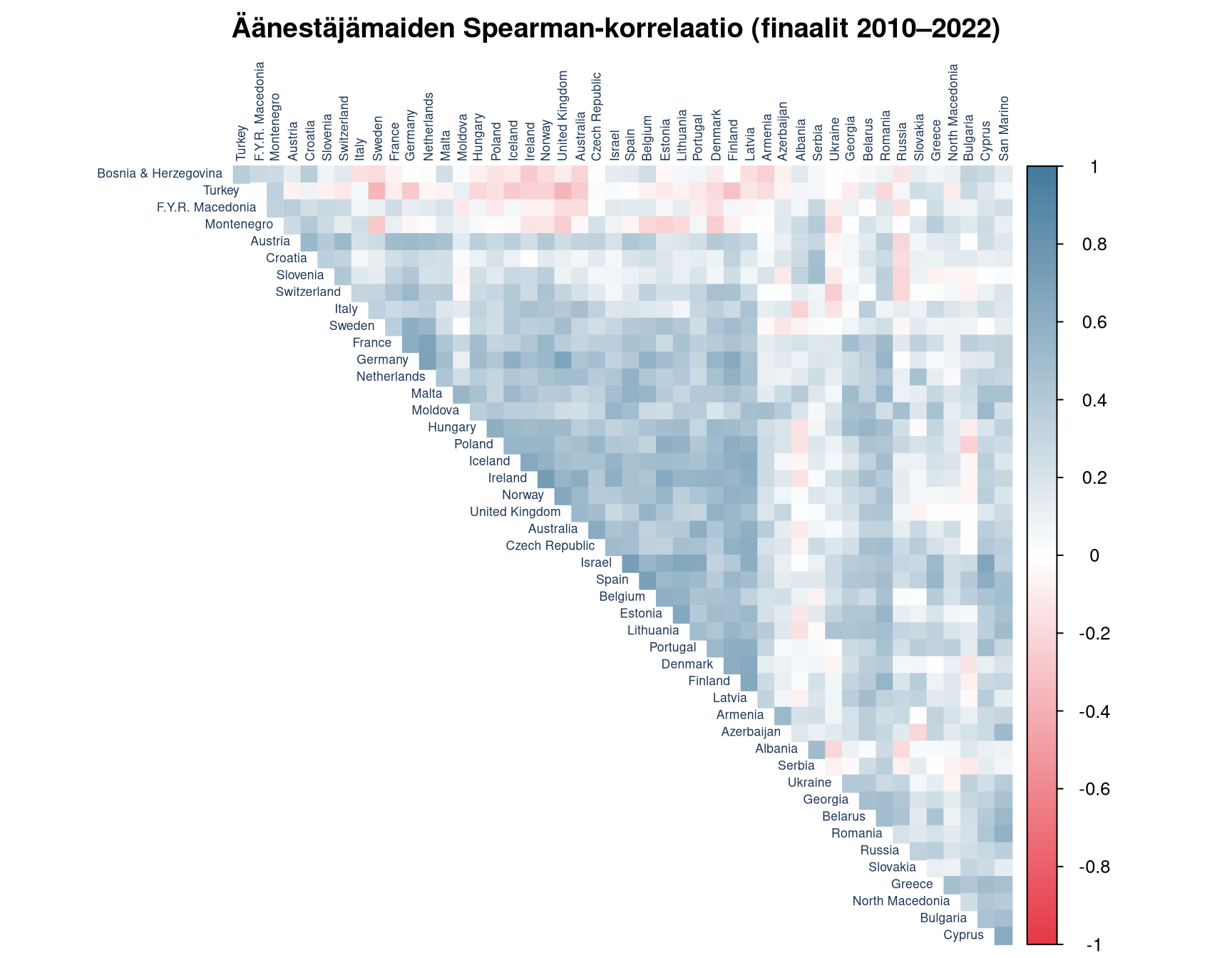
## Korrelaatiomatriisi: kuka äänestää samoin?
```{r correlation-matrix}
# Pivotoi leveään muotoon: rivit = äänestäjämaat, sarakkeet = kohdemaat
voter_agg <- votes_final |>
group_by(from_country, to_country) |>
summarise(avg_pts = mean(points, na.rm = TRUE), .groups = "drop") |>
pivot_wider(
id_cols = from_country,
names_from = to_country,
values_from = avg_pts,
values_fill = 0
)
mat <- as.matrix(select(voter_agg, -from_country))
rownames(mat) <- voter_agg$from_country
# Poistetaan maat joilla hyvin vähän varianssia (lähes aina 0)
row_var <- apply(mat, 1, var)
mat_f <- mat[row_var > 0.5, ]
cor_mat <- cor(t(mat_f), method = "spearman")
corrplot(
cor_mat,
method = "color",
type = "upper",
tl.cex = 0.55,
tl.col = clr_navy,
col = colorRampPalette(c(clr_red, "white", clr_blue))(200),
title = "Äänestäjämaiden Spearman-korrelaatio (finaalit 2010–2022)",
mar = c(0, 0, 2, 0),
diag = FALSE,
order = "hclust" # ryhmittelee samanlaiset äänestäjät vierekkäin
)
```
## Mitä tämä tarkoittaa tänä iltana?
Toisen semifinaalin maiden (Bulgaria, Azerbaidžan, Romania, Luxemburg,
Tšekki, Armenia, Sveitsi, Kypros, Latvia, Tanska, Australia, Ukraina,
Albania, Malta, Norja) kannattaa huomioida:
- **Itä-Euroopan blokki** (Romania, Bulgaria, Armenia) äänestää vahvasti
toisiaan – Louvain ryhmittelee nämä tyypillisesti yhteen yhteisöön
- **Pohjoismaat** (Tanska, Norja) korreloivat keskenään voimakkaasti
- **Diaspora-efekti**: Armenia saa pisteitä maista, joissa on suuri
armenialainen diaspora
::: callout-note
## Jakauma-ajattelun ydin
Yksittäinen äänestyslinkkipari ("Kreikka antaa Kyprokselle 12p") on
epäinformatiivinen. Olennainen rakenne näkyy vasta **koko
äänestysmatriisin jakaumasta** — ja erityisesti blokkien sisäisestä
korrelaatiosta verrattuna blokkien väliseen korrelaatioon.
:::
---
*Kristian Vepsäläinen on data science -konsultti Siilinjärveltä.
Kiinnostuitko? → [kristianvepsalainen.com](https://kristianvepsalainen.com)*