---
title: "Suomalainen yrityskenttä jakaumana, osa 2: Rekisteröidyt ilmoitukset"
subtitle: "Yritysten käyttäytymisen sormenjälki — mitä rekisterimerkinnät kertovat"
author: "Kristian Vepsäläinen"
date: "2026-06-30"
categories: [avoin data, YTJ, EDA, R]
format:
html:
toc: true
code-fold: true
code-tools: true
execute:
warning: false
message: false
freeze: auto
---
```{r setup}
#| include: false
library(here)
library(knitr)
source(here("R","ytj", "theme_kristian.R"))
source(here("R","ytj", "ytj_api.R"))
suppressPackageStartupMessages({
library(tidyverse)
library(patchwork)
})
data_dir <- here("data","ytj")
dir.create(data_dir, showWarnings = FALSE, recursive = TRUE)
```
> **Sarjan osa 2/20.** Osassa 1 katsoimme, *mitä* yritykset ovat. Nyt
> katsomme, *mitä ne tekevät*: jokainen nimenmuutos, osoitteenvaihto,
> hallituksen kokoonpanon päivitys ja tilintarkastajan poisto jättää
> kaupparekisteriin merkinnän. Näistä merkinnöistä muodostuu yrityksen
> käyttäytymisen aikasarja.
## Uutiskytkin: "yritysjärjestelyt kiihtyivät"
Kun talous heiluu, otsikoissa vilahtaa *"yritysjärjestelyt kiihtyivät"* tai
*"omistajanvaihdokset lisääntyivät."* Mutta mistä tämä tieto tulee, ja
voiko sitä mitata reaaliaikaisesti? Voi. Rekisteröityjen ilmoitusten
rajapinta sisältää **jokaisen kaupparekisterimerkinnän 7.11.2014 alkaen** —
päivämäärän, kohteen ja merkintälajin tarkkuudella.
Tämä on aliarvostettu aineisto. Yritysten määrä on tila (*stock*);
rekisterimerkinnät ovat virta (*flow*). Virta reagoi suhdanteisiin
nopeammin kuin tila, ja juuri siksi se on osassa 11 perustana
reaaliaikaiselle suhdannemittarille.
## Datan rakenne
Haetaan merkinnät aikaväliltä. Jokaisella ilmoituksella on yksi tai useampi
**merkintälaji** Nämä koodit ovat se sanasto, jolla yrityksen elämää voi
lukea. Alla on niistä täydellinen taulukko sekä esimerkki datasta.
```{r fetch-data}
#| cache: false
ilmoitukset_path <- here::here("data","ytj", "krek_ilmoitukset.qs")
notices_cp <- here::here("data", "ytj", "notices") # sivukohtaiset checkpointit
if (!file.exists(ilmoitukset_path)) {
# Yksi todennettu kutsu (GET /), purkaa ilmoitukset sivu kerrallaan.
# Checkpointtaa joka sivun -> keskeytys jatkuu siitä mihin jäi.
ilmoitukset <- fetch_notices_all_tidy(checkpoint_dir = notices_cp)
qs2::qs_save(ilmoitukset, ilmoitukset_path)
} else {
ilmoitukset <- qs2::qs_read(ilmoitukset_path)
}
# Rajaus ikkunaan tehdään client-side: rajapinta palauttaa koko historian.
ilmoitukset_ikkuna <- ilmoitukset |>
dplyr::filter(registration_date >= as.Date("2024-01-01"),
registration_date <= as.Date("2025-12-31"))
stopifnot(nrow(ilmoitukset_ikkuna) > 0,
!anyNA(ilmoitukset_ikkuna$registration_date))
```
```{r integrity-checks}
stopifnot(
nrow(ilmoitukset) > 1000,
all(c("business_id", "registration_date", "entry_codes", "n_entries") %in% names(ilmoitukset)),
all(ilmoitukset$n_entries >= 0)
)
# Viikonpäivän labelit eivät saa riippua käyttöjärjestelmän kielestä:
# wday(label=TRUE) antaisi "Mon"/"ma" lokaalin mukaan ja rikkoisi renderin.
# -> numero logiikkaan (1=ma … 7=su), labelit asetetaan itse.
vko_labels <- c("ma","ti","ke","to","pe","la","su")
ilmoitukset <- ilmoitukset |>
mutate(
registration_date = as.Date(registration_date),
vuosi = lubridate::year(registration_date),
kk = lubridate::floor_date(registration_date, "month"),
vko_num = lubridate::wday(registration_date, week_start = 1), # 1=ma … 7=su
vko = factor(vko_labels[vko_num], levels = vko_labels)
)
# Aikarajaus pitää: ei merkintöjä ennen 7.11.2014
stopifnot(min(ilmoitukset$registration_date, na.rm = TRUE) >= as.Date("2014-11-07"))
# EC-koodisto (PRH:n rekisterin oma koodilista, CC BY 4.0).
# Liitetään entry_code-sarakkeeseen: vasen liitos säilyttää havaitut frekvenssit.
ec_selitteet <- tibble::tribble(
~entry_code, ~selite,
"TASE", "Tilinpäätösasiakirjat",
"HAL", "Hallitus",
"TILTAR", "Tilintarkastajat",
"ESR", "Tosiasialliset edunsaajat",
"TAL", "Toimiala",
"OSLUKU", "Osakkeiden lukumäärä",
"TMI", "Toiminimi",
"NORTIL", "Normaali tilikausi",
"OPO", "Osakepääoma",
"KOTI", "Kotipaikka",
"TOIM", "Toimitusjohtajat",
"POITIL", "Poikkeava tilikausi"
)
kable(ec_selitteet)
```
```{r glimpse-ilmoitukset}
glimpse(ilmoitukset)
```
## Mitä virrasta paljastuu?
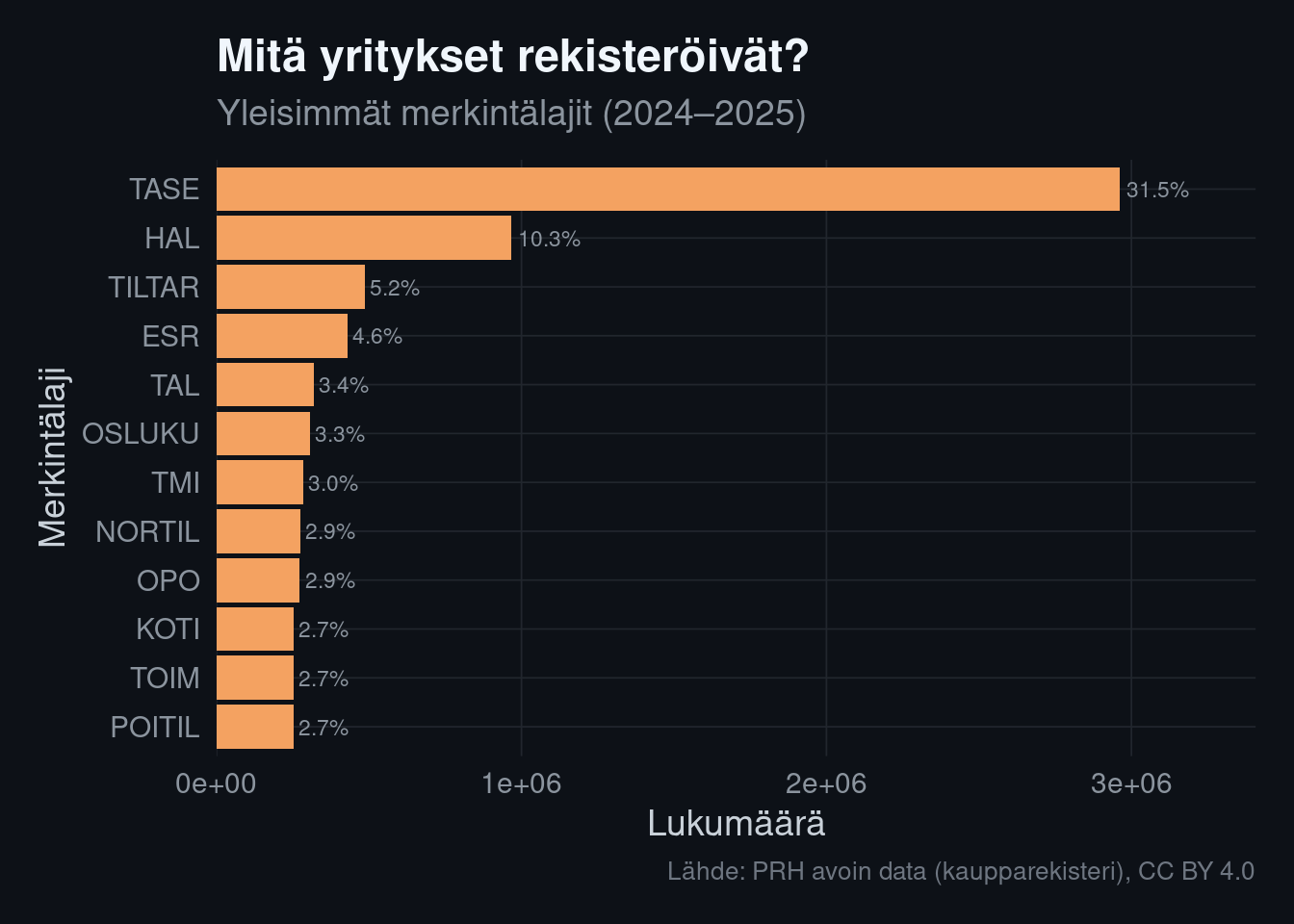
### 1. Merkintälajien jakauma: harvat lajit hallitsevat
```{r entry-code-dist}
lajit <- ilmoitukset |>
select(business_id, entry_codes) |>
unnest_longer(entry_codes) |>
filter(!is.na(entry_codes)) |>
count(entry_codes, sort = TRUE) |>
mutate(osuus = n / sum(n)) |>
slice_head(n = 12)
ggplot(lajit, aes(x = reorder(entry_codes, n), y = n)) +
geom_col(fill = kvar_palette[["orange"]]) +
geom_text(aes(label = scales::percent(osuus, accuracy = 0.1)),
hjust = -0.1, color = "#8b949e", size = 3) +
coord_flip() +
scale_y_continuous(expand = expansion(mult = c(0, 0.15))) +
labs(
title = "Mitä yritykset rekisteröivät?",
subtitle = "Yleisimmät merkintälajit (2024–2025)",
x = "Merkintälaji", y = "Lukumäärä",
caption = "Lähde: PRH avoin data (kaupparekisteri), CC BY 4.0"
)
```
### 2. Ilmoitukset per yritys on raskashäntäinen jakauma
Useimmat yritykset tekevät hyvin vähän merkintöjä. Pieni joukko tekee
paljon. Tämä on klassinen ylihajonta-tilanne — ja sillä on väliä, koska
merkintöjen tiheys on osassa 5 yksi voimakkaimmista riskisignaaleista.
per_yritys <- ilmoitukset |>
count(business_id, name = "n_ilmoitusta")
p_box <- ggplot(per_yritys, aes(y = n_ilmoitusta)) +
geom_boxplot(fill = kvar_palette[["blue"]], outlier.color = kvar_palette[["red"]]) +
scale_y_log10() +
labs(title = "Ilmoituksia per yritys", subtitle = "Logaritminen asteikko",
y = "Ilmoituksia (log10)", x = NULL) +
theme(axis.text.x = element_blank())
# Sovitetaan jakauma: Poisson vs. negatiivinen binomi (ylihajonta?)
lambda <- mean(per_yritys$n_ilmoitusta)
varianssi <- var(per_yritys$n_ilmoitusta)
dispersio <- varianssi / lambda # > 1 => ylihajontaa
p_bar <- per_yritys |>
count(n_ilmoitusta) |>
filter(n_ilmoitusta <= 10) |>
ggplot(aes(n_ilmoitusta, n)) +
geom_col(fill = kvar_palette[["teal"]]) +
labs(title = "Jakauman muoto",
subtitle = sprintf("Keskiarvo %.2f, varianssi %.2f → hajontasuhde %.1f",
lambda, varianssi, dispersio),
x = "Ilmoituksia / yritys", y = "Yrityksiä")
p_box + p_bar
> **Päättäjälle.** Hajontasuhde (varianssi / keskiarvo) on selvästi yli
> yhden. Käytännössä: yrityksen aktiivisuutta ei voi mallintaa pelkällä
> keskiarvolla, vaan tarvitaan jakauma, joka sallii "hiljaiset" ja
> "hyperaktiiviset" yritykset rinnakkain. Tähän palaamme mallinnusosissa.
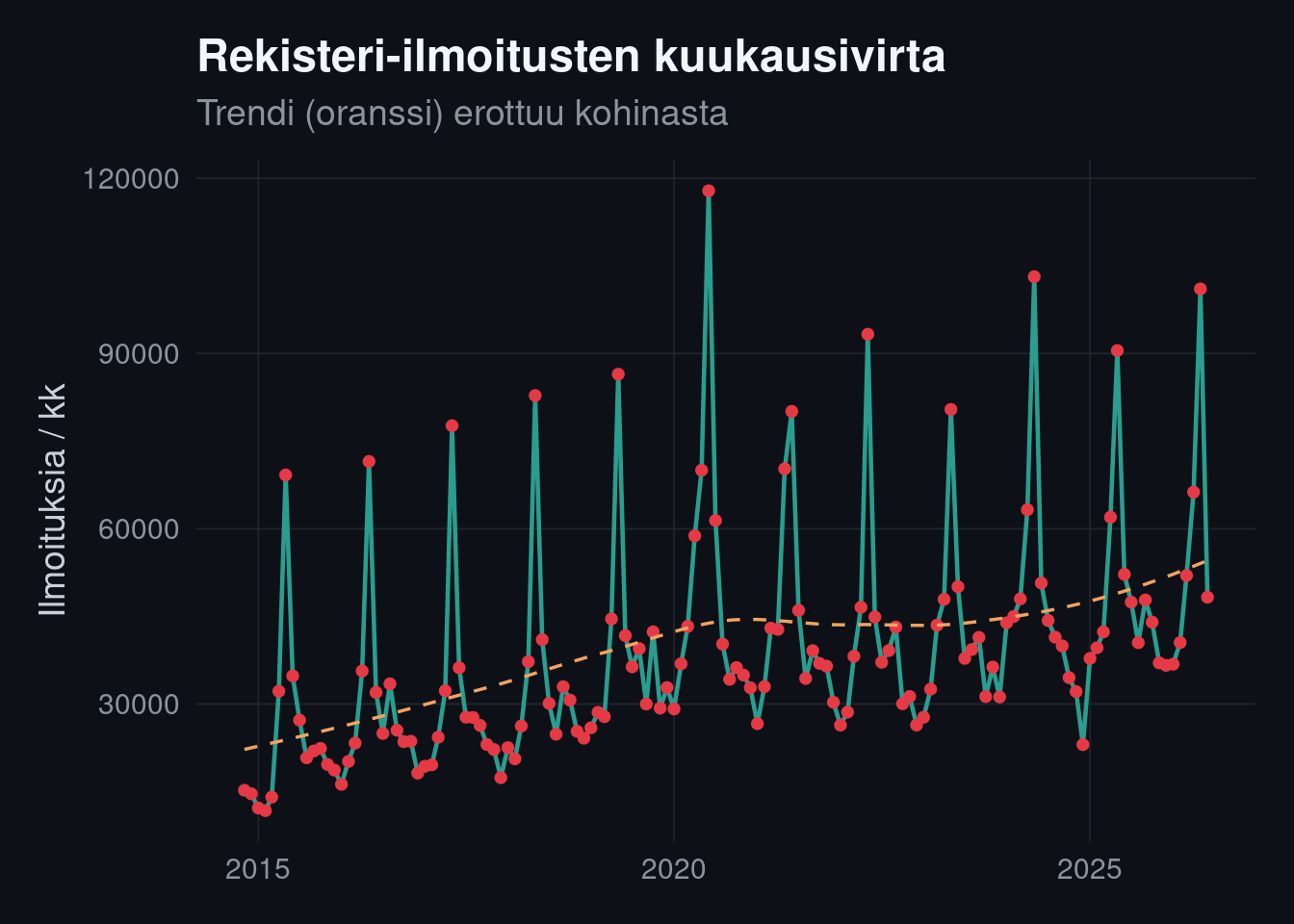
### 3. Ilmoitusvirran kausivaihtelu
```{r seasonality}
kk_sarja <- ilmoitukset |> count(kk)
ggplot(kk_sarja, aes(kk, n)) +
geom_line(color = kvar_palette[["teal"]], linewidth = 0.8) +
geom_point(color = kvar_palette[["red"]], size = 1.5) +
geom_smooth(method = "loess", se = FALSE, color = kvar_palette[["orange"]],
linewidth = 0.6, linetype = "dashed") +
labs(
title = "Rekisteri-ilmoitusten kuukausivirta",
subtitle = "Trendi (oranssi) erottuu kohinasta",
x = NULL, y = "Ilmoituksia / kk"
)
```
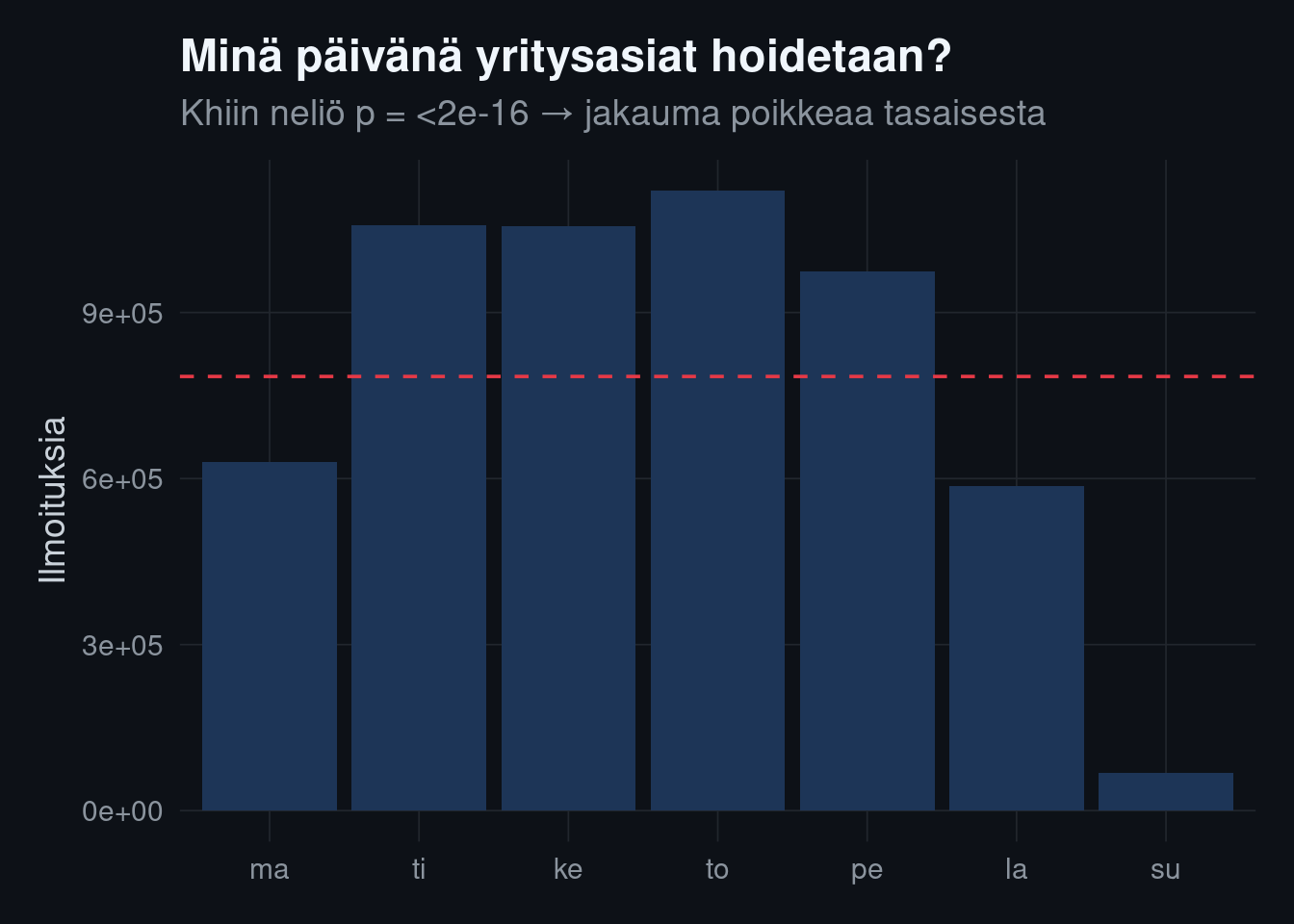
## Eroaako viikonpäivien aktiivisuus sattumasta?
Yritysjärjestelyt eivät jakaudu tasaisesti viikonpäiville. Testataan,
poikkeaako havaittu jakauma tasajakaumasta (mitä odottaisimme, jos päivällä
ei olisi väliä). Oikea työkalu on **khiin neliö -yhteensopivuustesti**.
```{r weekday-test}
ark <- ilmoitukset |>
filter(!is.na(vko)) |>
count(vko)
# H0: ilmoitukset jakautuvat tasaisesti viikon työpäiville
# (viikonloput sisältyvät, mutta odotamme niissä lähes nollaa -> testataan ma–pe)
ark_tyo <- ark |> filter(vko %in% c("ma","ti","ke","to","pe"))
khii <- chisq.test(ark_tyo$n, p = rep(1/nrow(ark_tyo), nrow(ark_tyo)))
stopifnot(all(khii$expected >= 5))
khii
```
```{r weekday-plot}
ark |>
mutate(odotettu = sum(n) / n()) |>
ggplot(aes(vko, n)) +
geom_col(fill = kvar_palette[["navy"]]) +
geom_hline(aes(yintercept = mean(n)), color = kvar_palette[["red"]], linetype = "dashed") +
labs(title = "Minä päivänä yritysasiat hoidetaan?",
subtitle = paste0("Khiin neliö p = ", format.pval(khii$p.value, digits = 2),
" → jakauma poikkeaa tasaisesta"),
x = NULL, y = "Ilmoituksia")
```
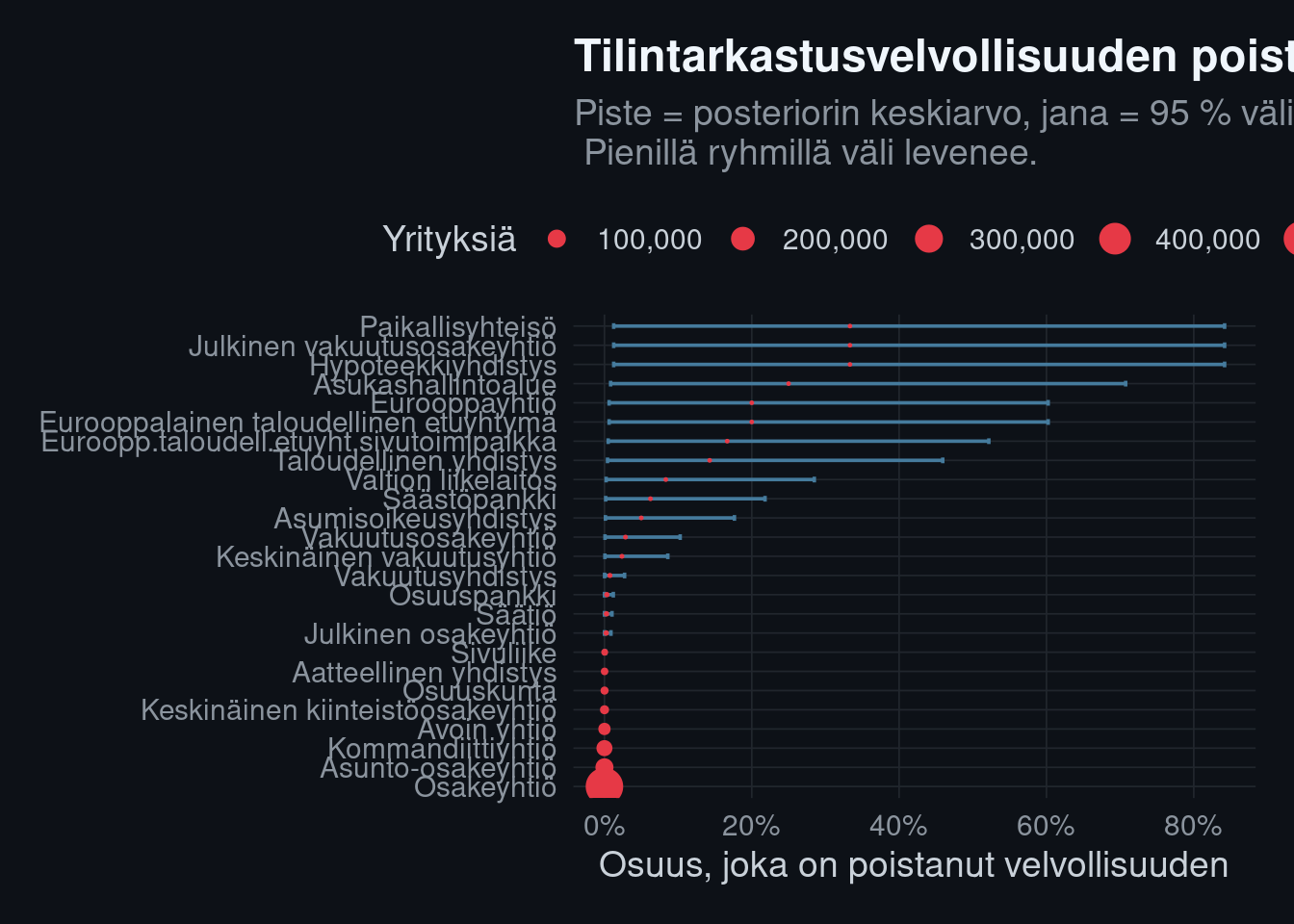
## Bayesilainen ajatuskoe: harvinainen merkintä
Jotkin merkintälajit ovat harvinaisia — esimerkiksi tilintarkastajan
poisto. Kun tapahtuma on harvinainen, pisteluku (*"X % yrityksistä"*) on
erityisen epävarma. Mallinnetaan osuus Beta-Binomi-mallilla ja näytetään,
miten epävarmuus kapenee, kun havaintoja on enemmän.
```{r rare-event}
library(dplyr); library(purrr); library(ggplot2)
## --- 1) MITTARIN MÄÄRITTELY (korjattu) -------------------------------------
# Kysymys: kuinka moni yritys on LUOPUNUT tilintarkastusvelvollisuudesta?
# TILTAP = Tilintarkastusmääräysten poisto <- tämä on "poisto"
# TILTAR = Tilintarkastajat (valinta/muutos) <- EI tämä (mittasi päinvastaista)
# TILTAE = Eronneet tilintarkastajat <- tilintarkastaja-aloitteinen, eri asia
poisto_koodit <- "TILTAP"
# Yritykset, jotka ovat elinkaarensa aikana jättäneet TILTAP-ilmoituksen.
# HUOM: "joskus poistanut" — yhtiö on voinut myöhemmin palauttaa velvollisuuden.
poistaneet <- ilmoitukset |>
filter(map_lgl(entry_codes, ~ any(poisto_koodit %in% .x))) |>
distinct(business_id) |> pull(business_id)
## --- 2) NIMITTÄJÄ: koko populaatio, ei vain ilmoittaneet -------------------
# Tilintarkastusvelvollisuus koskee käytännössä osakeyhtiöitä (koodi 16);
# rajaus tekee osuudesta tulkittavan (AOY:illä, yhdistyksillä eri säännöt).
perustiedot <- qs2::qs_read(here("data","ytj","ytj_perustiedot.qs"))
pohja <- perustiedot |> filter(company_form_code == "16")
n_yht <- n_distinct(pohja$business_id)
n_poisto <- sum(pohja$business_id %in% poistaneet)
stopifnot(n_poisto <= n_yht)
phat <- n_poisto / n_yht
# Koko populaatiolla tämä on käytännössä census-suure: raportoi se kuvailevana
# faktana, ÄLÄ piirrä credible intervalia saavutuksena (väli olisi häviävän kapea
# pelkän n:n vuoksi, ei siksi että tietäisimme jotain tarkasti).
glue::glue("Osakeyhtiöistä {scales::percent(phat, 0.1)} ",
"({scales::comma(n_poisto)} / {scales::comma(n_yht)}) on jossain ",
"vaiheessa poistanut tilintarkastusvelvollisuuden.")
## --- 3) Missä epävarmuus on aitoa: osuus yhtiömuodoittain ------------------
per_form <- perustiedot |>
mutate(poisti = business_id %in% poistaneet) |>
group_by(company_form) |>
summarise(n = n(), k = sum(poisti), .groups = "drop") |>
mutate(
keskiarvo = (1 + k) / (2 + n), # Beta(1+k, 1+n-k) odotusarvo
lo = qbeta(0.025, 1 + k, 1 + n - k),
hi = qbeta(0.975, 1 + k, 1 + n - k)
) |>
arrange(desc(keskiarvo))
ggplot(per_form, aes(keskiarvo, reorder(company_form, keskiarvo))) +
geom_errorbar(aes(xmin = lo, xmax = hi), height = 0.3,
color = kvar_palette[["blue"]]) +
geom_point(aes(size = n), color = kvar_palette[["red"]]) +
scale_x_continuous(labels = scales::percent) +
scale_size_area(max_size = 6, labels = scales::comma) +
labs(
title = "Tilintarkastusvelvollisuuden poisto yhtiömuodoittain",
subtitle = "Piste = posteriorin keskiarvo, jana = 95 % väli.\n Pienillä ryhmillä väli levenee.",
x = "Osuus, joka on poistanut velvollisuuden",
y = NULL, size = "Yrityksiä"
)
```
Tämä merkintälaji ei ole sattumaa — se on osassa 7 oma analyysinsa, sillä
tilintarkastajan poisto on tunnettu (mutta vähän hyödynnetty) ennakkomerkki
taloudellisesta ahdingosta.
## Yhteenveto ja seuraava osa
Rekisteröidyt ilmoitukset muuttavat yrityskentän staattisesta kuvasta
eläväksi virraksi. Merkintälajien jakauma on pitkähäntäinen, ilmoitusten
määrä per yritys on ylihajontainen, ja aktiivisuudella on selvä
kausirakenne. Nämä eivät ole kuriositeetteja — ne ovat raaka-aine
ennustemalleille.
**Osassa 3** käsittelemme kolmannen rajapinnan: digitaaliset
tilinpäätöstiedot. Sieltä saamme luvut — liikevaihdon, tuloksen, taseen —
ja näemme, kuinka harva yritys ne todella avoimesti raportoi.
---
*Haluatko nähdä, mitä oman toimialasi tai alueesi rekisterivirta kertoo?
Rakennan avoimesta datasta päätöksiä tukevaa analytiikkaa.
[kristianvepsalainen.com](https://www.kristianvepsalainen.com)*